Evaluating RAG performance: Metrics and benchmarks
Introduction
RAG architectures facilitate the extraction of pertinent information, enhancing the overall quality and accuracy of generated outputs. This blog explores the intricacies of RAG architecture, focusing on the evaluation of its retrieval and generation components, the structure of effective evaluation datasets, and the metrics essential for assessing system performance. Additionally, it highlights the role of platforms like Maxim in optimizing dataset management and evaluation processes.
Overview of RAG architecture
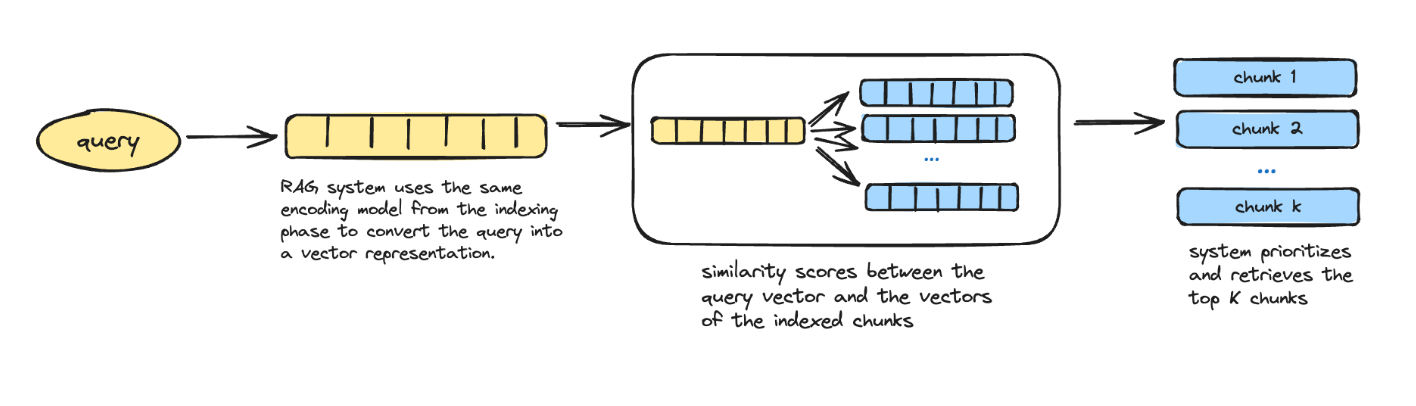
The RAG system architecture consists of two core components: Retrieval and Generation. The retrieval component focuses on extracting relevant information from external knowledge sources, following two main phases—indexing and searching. Indexing structures documents for efficient retrieval, either through inverted indexes (sparse retrieval) or dense vector encoding (dense retrieval). The search phase then utilizes these indexes to retrieve relevant documents based on user queries, often with re-rankers to enhance document relevance.
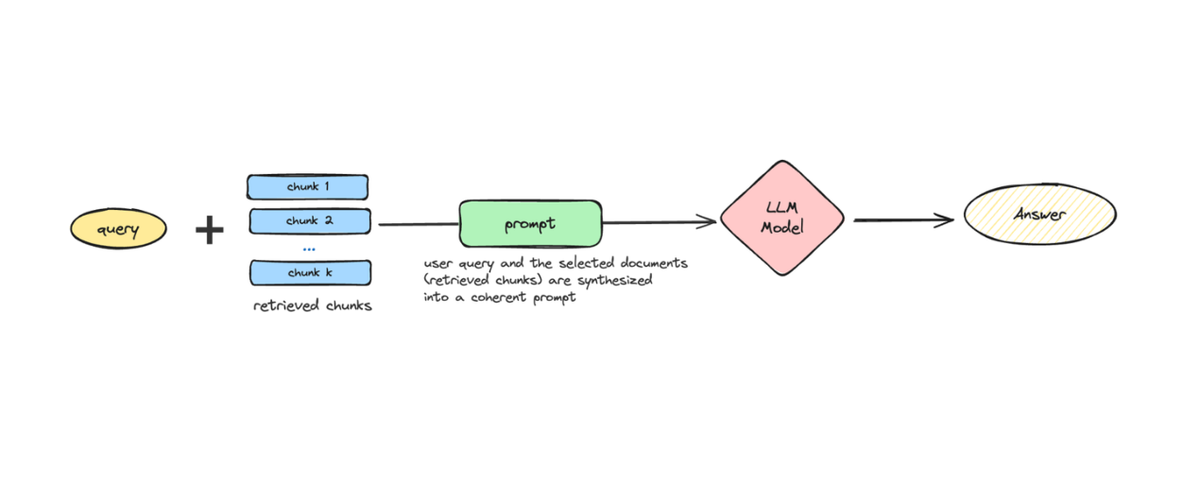
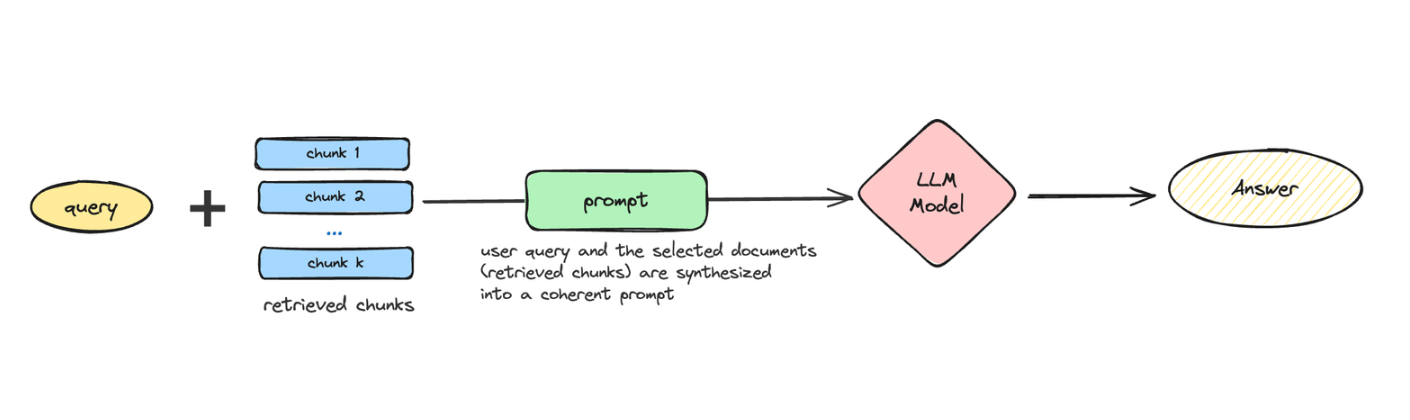
In the generation component, the retrieved content is used to produce coherent and contextually aligned responses. Generation involves prompting methods, document summarization strategies, and document repacking techniques to improve response quality. The inferencing step then interprets these prompts, generating accurate answers that integrate retrieved information. Additionally, fine-tuning the generator to prioritize relevant contexts over irrelevant ones enhances model output for specific tasks. Together, these methodologies refine the RAG generation workflow.
What is RAG evaluation?
Evaluating an RAG system involves assessing its retrieval, generation, and overall effectiveness.
- Retrieval: This component is evaluated for its ability to accurately and efficiently retrieve relevant documents. Key considerations include the relevance of the retrieved information to the user query and the precision in ranking relevant documents above non-relevant ones.
- Generation: Evaluation here focuses on not only factual correctness but also the coherence, fluency, and alignment of generated responses with the user's intent. Generation metrics assess whether the output is informative, relevant, and free from factual errors.
- System as a whole: Effective RAG evaluation also looks at the integration of retrieval and generation, assessing how well the retrieved content enhances the quality of generated responses. Practical aspects, such as response time and handling of complex queries, are also important to measure the system's usability and effectiveness in real-world applications.
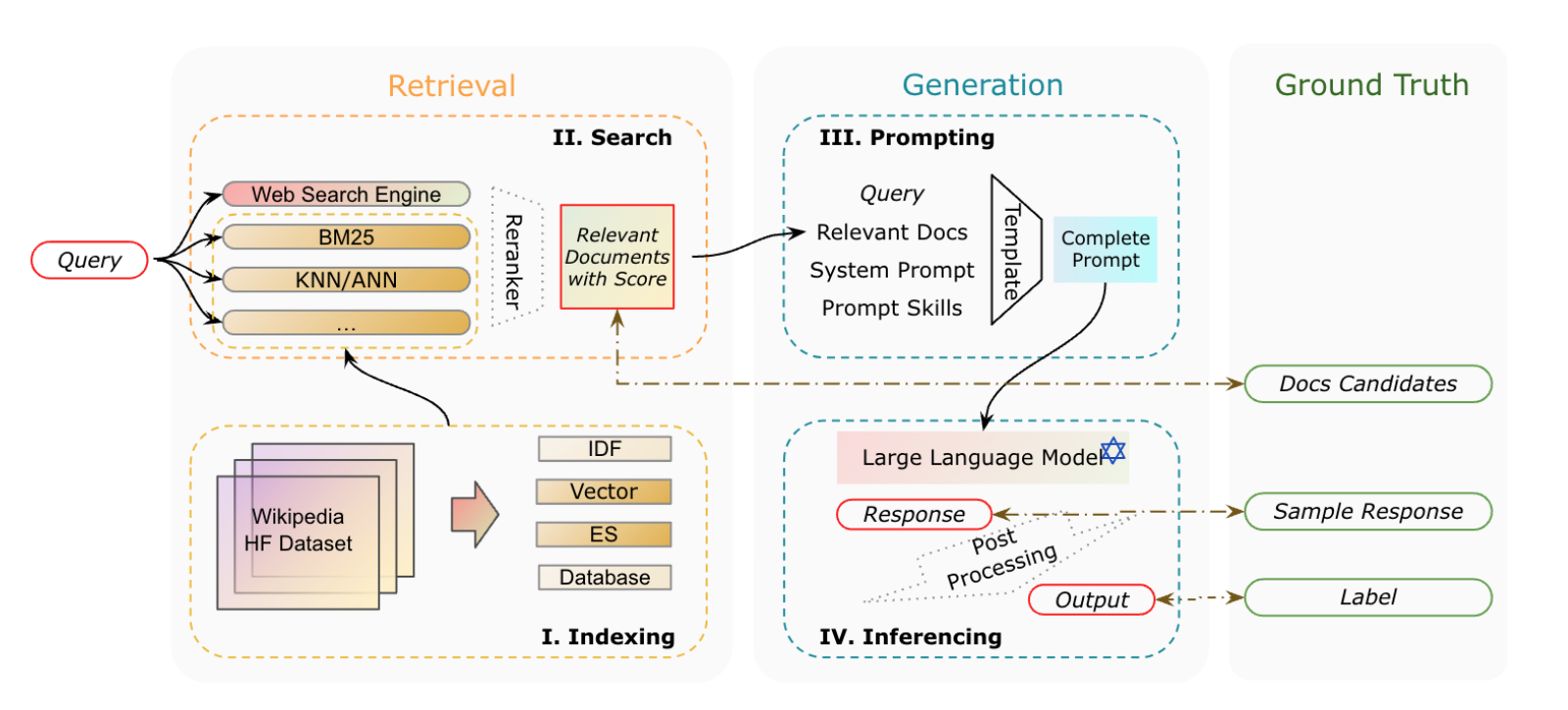
Evaluation target (What to evaluate?)
In evaluating the retrieval component, the evaluable outputs are the relevant documents identified in response to a given query. Two pairwise relationships can be established for this evaluation: one between Relevant Documents and the Query and another between Relevant Documents and Document Candidates.
- Relevance (Relevant Documents ↔ Query) assesses how effectively the retrieved documents meet the information requirements expressed in the query, focusing on the precision and specificity of the retrieval process.
- Accuracy (Relevant Documents ↔ Document Candidates) evaluates the accuracy of the retrieved documents by comparing them to a broader set of candidate documents. This metric reflects the system’s capability to rank truly relevant documents above those that are less relevant or irrelevant.
The generation component involves similar pairwise relationships. Here, the evaluable outputs (EOs) are the generated text and structured content, which are then compared to the provided ground truths (GTs) and labels.
- Relevance (Response ↔ Query) assesses how well the generated response aligns with the intent and content of the original query, ensuring that the response stays on topic and meets the specific requirements of the query.
- Faithfulness (Response ↔ Relevant documents) examines whether the generated response accurately reflects the information found in the relevant documents, measuring the consistency between the response and the source content.
- Correctness (Response ↔ Sample response) evaluates the accuracy of the generated response against a sample response that serves as ground truth. This criterion checks whether the response is factually correct and contextually appropriate for the query.
Evaluation dataset (How to evaluate?)
The dataset structure is key to effectively evaluating RAG systems. Evaluation datasets may be constructed by reusing existing resources like KILT (Natural questions, HotpotQA, FEVER) or creating new datasets that address specific evaluation goals. While established datasets offer a foundation, they often lack adaptability for dynamic, real-world scenarios.
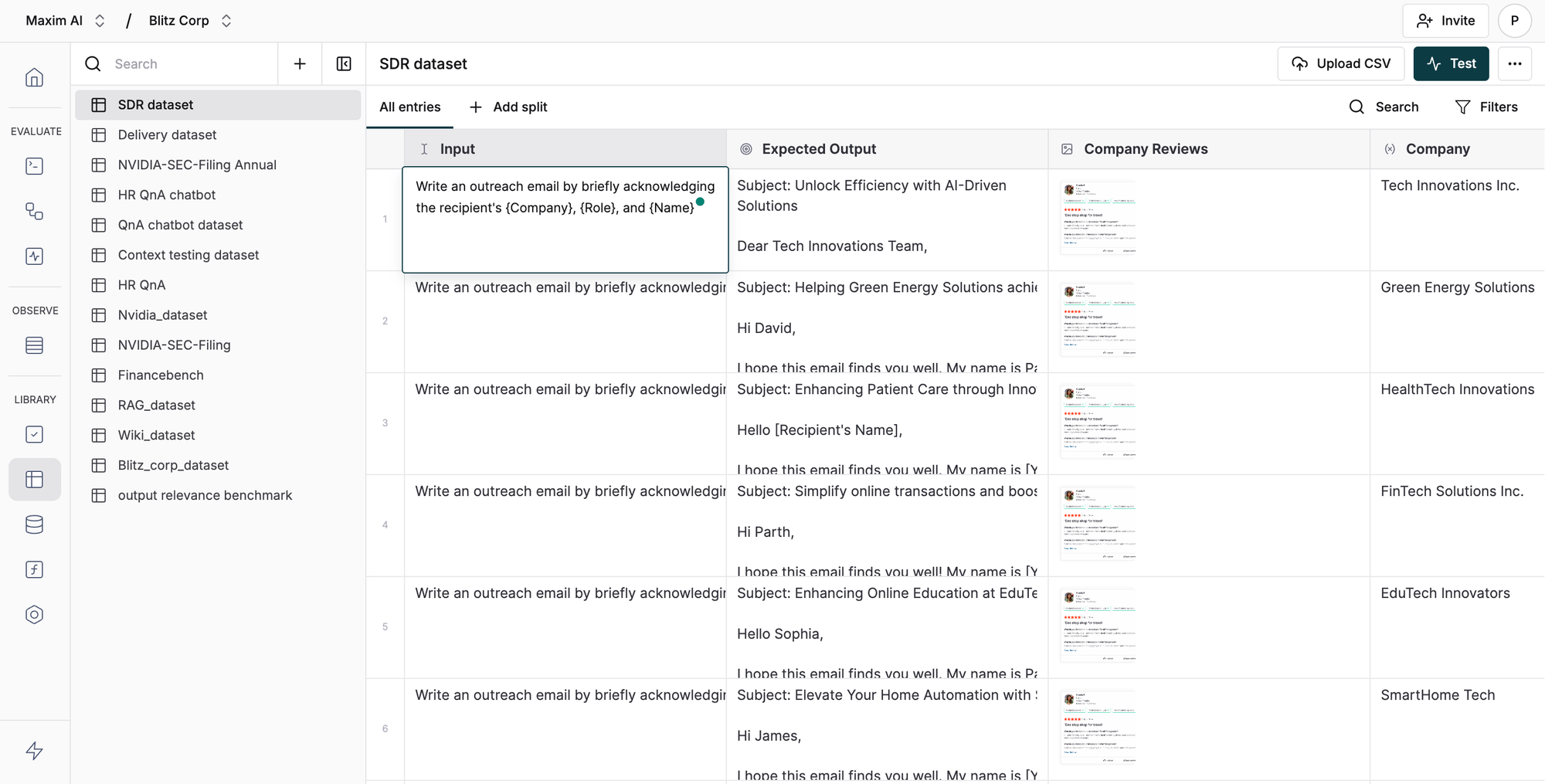
Datasets typically consist of an input, which serves as the query to the RAG system, and a ground truth, which provides the expected output. For example, in a dataset created in Maxim to test an RAG system using an HR policy document, the input includes questions related to the HR policy handbook, while the ground truth provides the corresponding answers. The entire HR policy handbook is the reference document for retrieval in the RAG system.
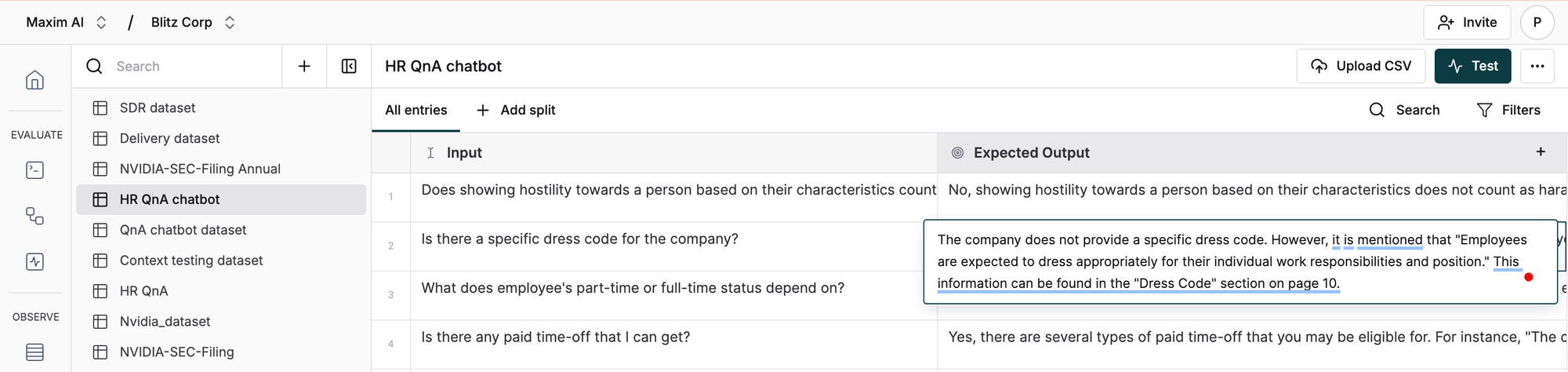
With Maxim, dataset management is streamlined for AI evaluation and minimizes team manual effort. Maxim enables dynamic datasets that adapt over time, updating automatically based on user feedback and metadata. It supports multimodal data, allowing input queries, images, expected outputs, and tool calls to be integrated seamlessly into testing workflows. Maxim’s Excel-like interface ensures easy creation, updating, and management of datasets, with full CSV import support for flexible, efficient handling throughout the development lifecycle.
Evaluation metrics
Evaluating RAG systems requires carefully chosen metrics that capture the diverse needs and nuances of retrieval-augmented generation. Since each RAG component serves a specific function, the evaluation metrics must be tailored to accurately reflect those roles, particularly in retrieval, where factors like relevance, accuracy, and robustness are critical.
For the retrieval component, evaluation typically focuses on both rank-based and non-rank-based metrics, each serving a distinct purpose. Non-rank-based metrics generally evaluate binary outcomes, such as whether an item is relevant, without emphasizing the item's position in the results. Examples include:
- Accuracy measures the proportion of correct results (both true positives and true negatives) out of all cases analyzed.
- Precision quantifies the fraction of relevant instances among the retrieved items.
- Recall@k measures the fraction of relevant instances retrieved within the top-k results, considering only a subset of the ranked list for high relevance.
Rank-based metrics prioritize the position of relevant items in the list, which is essential in scenarios where the ranking order significantly impacts the retrieval performance:
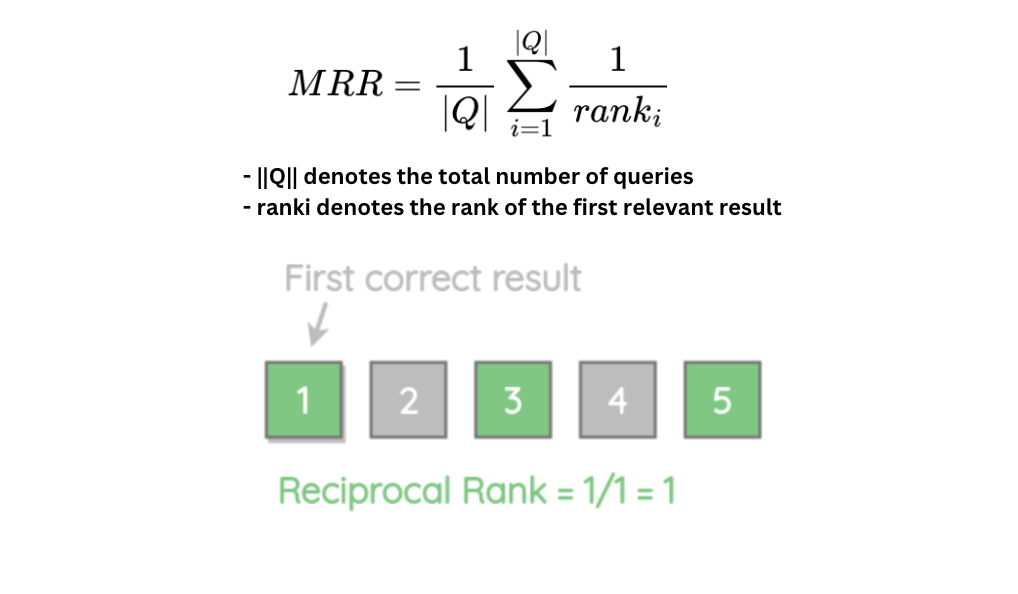
- Mean reciprocal rank (MRR) focuses on the position of the first correct answer, averaging the reciprocal ranks across queries, thus rewarding higher placements of relevant documents.
- Mean average precision (MAP) averages precision scores across ranks for each query, providing a comprehensive view of the system's ability to retrieve relevant documents consistently across various ranking levels.

Generation metrics are essential for evaluating the quality of responses in RAG systems, focusing on aspects like coherence, fluency, relevance, and factual accuracy.
Human evaluation remains a benchmark for comparing generation models to ground truth. Additionally, employing LLMs as evaluative judges has become a popular, automated alternative, offering nuanced scoring based on coherence and relevance when traditional ground truths are unavailable.
Key generation metrics:
- ROUGE: Measures content overlap by comparing generated and reference summaries, focusing on n-gram and sequence matching for relevance.
- BLEU: Used in translation, BLEU calculates n-gram precision and penalizes overly short outputs, though it may lack in measuring fluency.
- BertScore: Uses embeddings from models like BERT to evaluate semantic similarity, making it more robust to paraphrasing.
- LLM as a judge (AI evaluators): LLMs score generated content on coherence, relevance, and fluency, providing detailed quality assessments with scoring guidelines (e.g., 1-5 scale), ensuring standardization across evaluations.
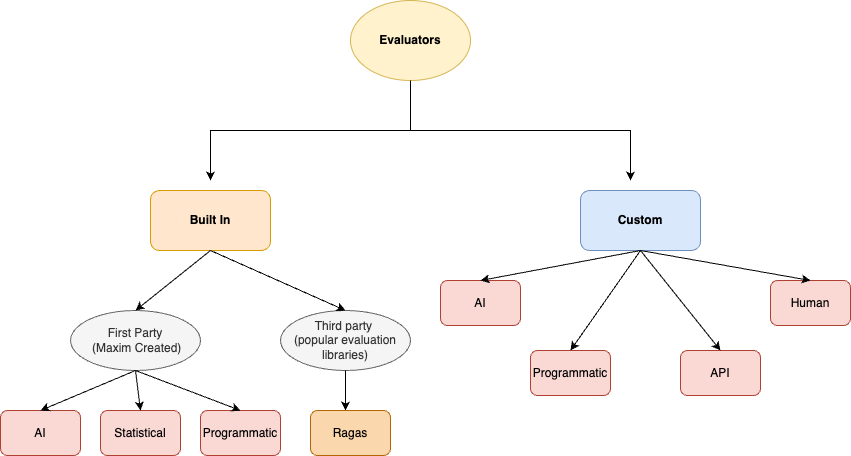
Maxim also provides an evaluation platform offering a robust suite of both pre-built and customizable evaluators to meet diverse quality and safety testing needs. The pre-built evaluators are split into two main categories: Maxim-created evaluators and third-party integrations. Maxim’s in-house evaluators include AI-driven assessments leveraging large language models, statistical metrics like BLEU, ROUGE, and WER, and programmatic evaluators that allow for custom JavaScript logic. Additionally, the platform integrates third-party libraries, such as Ragas, which is popular for RAG pipeline evaluation, with more integrations in progress. Recognizing that each application may have unique evaluation requirements, Maxim also supports custom evaluators, enabling users to define tailored AI evaluators with specific prompts and scoring strategies, programmatic evaluators for custom logic, API-based models, and human evaluation workflows.
RAG benchmarks
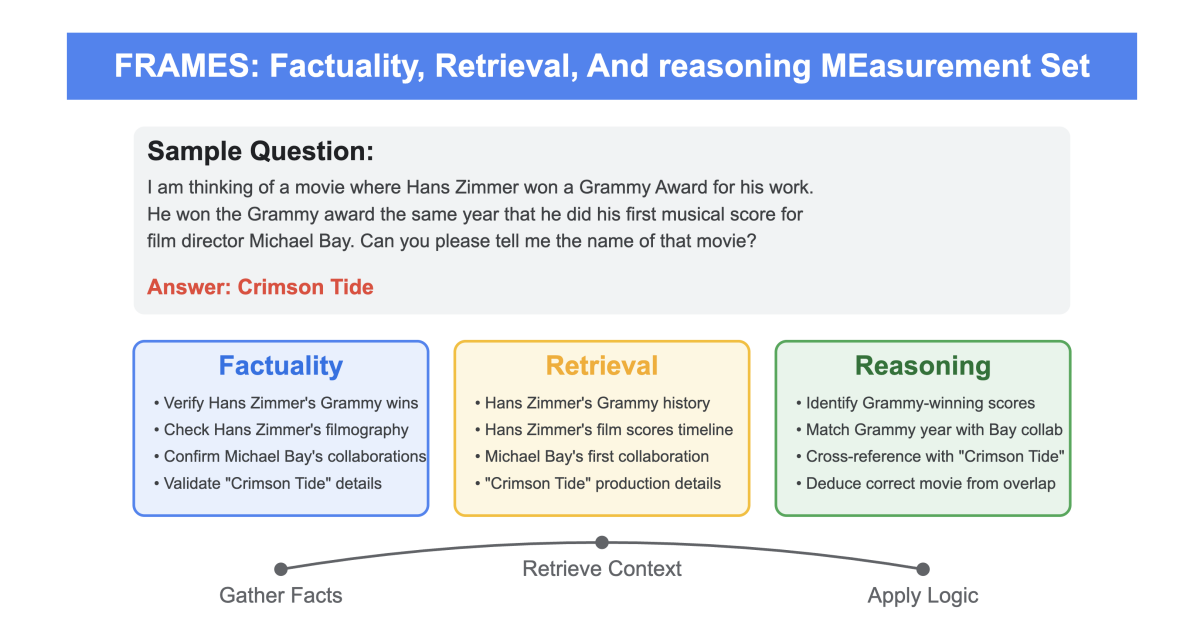
RAG benchmarks play a pivotal role in advancing retrieval-augmented generation by providing datasets that assess and enhance model performance in handling real-world tasks. For instance, RAGTruth targets hallucination detection, with nearly 18,000 annotated responses from various LLMs measuring hallucination at both case and word levels. It enables fine-tuning smaller models to detect and reduce hallucinations effectively, achieving performance comparable to leading LLMs like GPT-4. Meanwhile, FRAMES evaluates LLMs' factual accuracy, retrieval capabilities, and reasoning with multi-hop queries, highlighting how a multi-step retrieval pipeline boosts accuracy by over 50%. Together, these benchmarks help refine LLMs for reliable, fact-based RAG applications.
Conclusion
In summary, the evaluation of RAG systems is a multifaceted process that requires careful consideration of both retrieval and generation components. Effective evaluation not only assesses the accuracy and relevance of retrieved documents but also ensures that generated responses are coherent and aligned with user intent. By leveraging comprehensive evaluation datasets and metrics, including innovative benchmarks, RAG systems can continuously improve their performance in real-world applications.
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your Gen AI application's performance with Maxim.