Improving RAG accuracy with reranking techniques

Introduction
Creating a robust Retrieval Augmented Generation (RAG) application presents numerous challenges. As the complexity of the documents increases, we often encounter a significant decrease in the accuracy of the generated answers. This issue can stem from various factors, such as chunk length, metadata quality, clarity of the document, or the nature of the questions asked. By leveraging extended context lengths and refining our Retrieval-Augmented Generation (RAG) strategies, we can significantly enhance the relevance and accuracy of our responses. One effective strategy is the implementation of a re-ranker to ensure more precise and informative outcomes.
What is a Reranker?

In the context of Retrieval-Augmented Generation (RAG), a re-ranker is a model used to refine and improve the initial set of retrieved documents or search results before they are passed to a language model for generating responses. The process begins with an initial retrieval phase where a set of candidate documents is fetched based on the search query using keyword-based search, vector-based search, or a hybrid approach. After this initial retrieval, a re-ranker model re-evaluates and reorders the candidate documents by computing a relevance score for each document-query pair. This re-ranking step prioritizes the most relevant documents according to the context and nuances of the query. The top-ranked documents from this re-ranking process are then selected and passed to the language model, which uses them as context to generate a more accurate and informative response.
Why Re-Rankers?
Hallucinations, as well as inaccurate and insufficient outputs, often occur when unrelated retrieved documents are included in the output context. This is where re-rankers can be invaluable. They rearrange document records to prioritize the most relevant ones. The current problems with the existing retrieval and generation framework are:
Information loss in vector embeddings: In RAG, we use vector search to find relevant documents by converting them into numerical vectors. Typically, the text is compressed into vectors of 768 or 1536 dimensions. This process can miss some relevant information due to compression. For example, in "I like going to the beach" vs. "I don't like going to the beach," the presence of "don't" completely changes the meaning, but embeddings might place these sentences close together due to their similar structure and content.
Context Window Limit: To capture more relevant documents, we can increase the number of documents returned (top_k) to the LLM (Large Language Model) for generating responses. However, LLMs have a limit on the amount of text they can process at once, known as the context window. Also, stuffing too much text into the context window can reduce the LLM’s performance(needle in a haystack problem) in understanding and recalling relevant information.
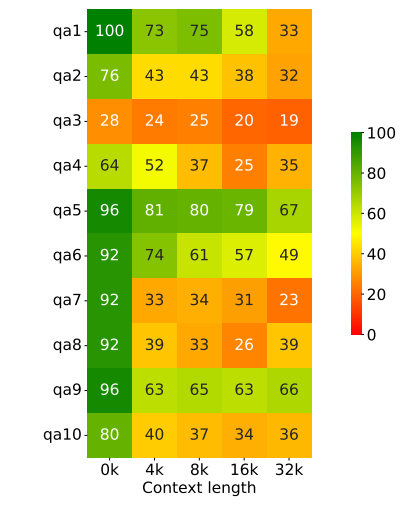
In the research paper "In Search of Needles in a 11M Haystack: Recurrent Memory Finds What LLMs Miss" they found, mistarl-medium model's performance scales only for some tasks but quickly degenerates for majority of others as context grows. Every row shows accuracy in % of solving corresponding BABILong task (’qa1’-’qa10’) and every column corresponds to the task size submitted to mistarl-medium with 32K context window.
How do we incorporate re-rankers in RAG?
To incorporate re-rankers in a Retrieval-Augmented Generation (RAG) system and enhance the accuracy and relevance of the generated responses, we employ a two-stage retrieval system. This system consists of:
Retrieval stage
In the retrieval stage, the goal is to quickly and efficiently retrieve a set of potentially relevant documents from a large text corpus. This is achieved using a vector database, which allows us to perform a similarity search.
- Vector representation: First, we convert the text documents into vector representations. This involves transforming the text into high-dimensional vectors that capture the semantic meaning of the text by using a bi-encoder. Typically, models like BERT or other pre-trained language models are used for this purpose.
- Storing vectors: These vector representations are then stored in a vector database. The vector database enables efficient storage and retrieval of these vectors, making it possible to perform fast similarity searches.
- Query vector: When a query is received, it is also converted into a vector representation using the same model. This query vector captures the semantic meaning of the query.
- Similarity search: The query vector is then compared against the document vectors in the vector database using a similarity metric, such as cosine similarity. This step identifies the top k documents whose vectors are most similar to the query vector.
Reranking stage
The retrieval stage often returns documents that are relevant but not necessarily the most relevant. This is where the reranking stage comes into play. The reranking model reorders the initially retrieved documents based on their relevance to the query. This will minimize the "needle in a haystack" problem and address the context limit issue, as some models have constraints on their context window. Thereby improving the overall quality of the results.
Initial set of documents:
The documents retrieved in the first stage are used as the input for the reranking stage. This set typically contains more documents than will ultimately be used, ensuring that we have a broad base from which to select the most relevant ones.
Reranking model:
There are multiple reranking models that can be used to refine search results by re-evaluating and reordering initially retrieved documents.
- Cross Encoder: It takes pairs of the query and each retrieved document and computes a relevance score. Unlike the bi-encoder used in the retrieval stage, which independently encodes the query and documents, the cross-encoder considers the interaction between the query and document during scoring.
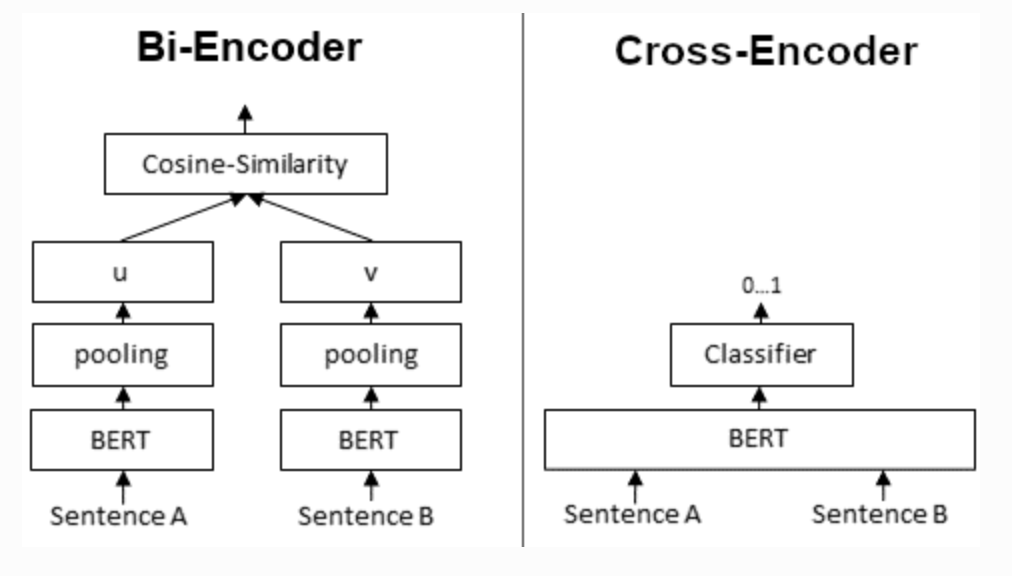
A cross-encoder concatenates the query and documents into a single input sequence and passes this combined sequence through the encoder model to generate a joint representation. While bi-encoders are efficient and scalable for large-scale retrieval tasks due to their ability to precompute embeddings, cross-encoders provide more accurate and contextually rich relevance scoring by processing query-document pairs together. This makes cross-encoders particularly advantageous for tasks where precision and nuanced understanding of the query-document relationship are crucial.
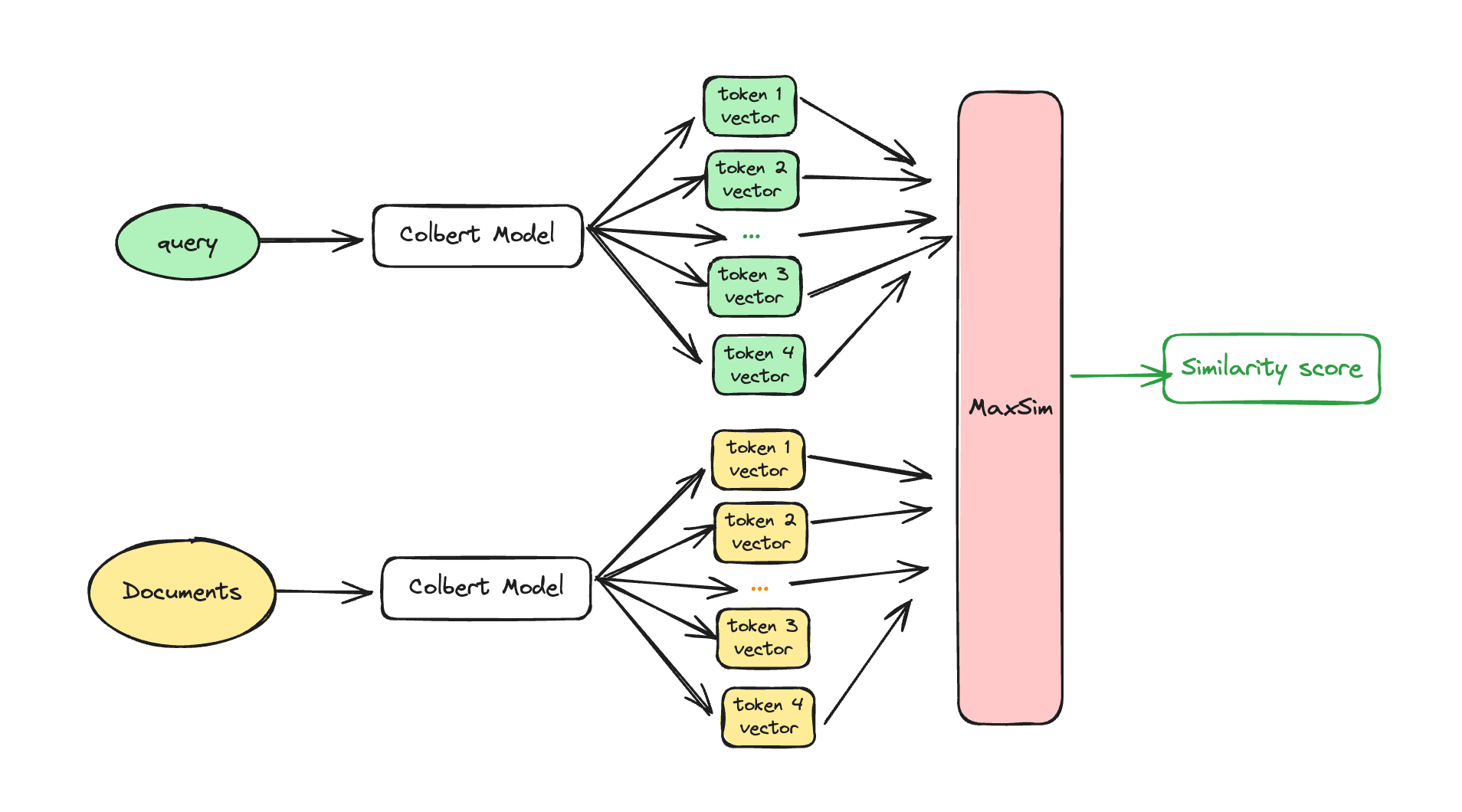
- Multi-Vector Rerankers: Models like ColBERT (Contextualized Late Interaction over BERT) strike a balance between bi-encoder and cross-encoder approaches. Colbert maintains the efficiency of bi-encoders by precomputing document representations while enhancing the interaction between query and document tokens during similarity computation.
Example Scenario
Query: "Impact of climate change on coral reefs"
For the document pre-computation, consider the following documents:
- Document A: "Climate change affects ocean temperatures, which in turn impacts coral reef ecosystems."
- Document B: "The Great Barrier Reef is facing severe bleaching events due to rising sea temperatures."
Each document is precomputed into token-level embeddings without considering any specific query.
When the query "Impact of climate change on coral reefs" is received, it is encoded into token-level embeddings at inference.
For token-level similarity computation, we first calculate the cosine similarity. For each token in the query, such as "Impact", we calculate its similarity with every token in Document A and Document B. This process is repeated for each token in the query ("of", "climate", "change", "on", "coral", "reefs").
Next, we apply the maximum similarity (maxSim) method. For each query token, we keep the highest similarity score. For instance, the highest similarity score for "coral" might come from the word "coral" in Document A, and for "change" from "change" in Document B.
Finally, we sum the maxSim scores to get the final similarity score for each document. Document A receives a final similarity score of 0.85, while Document B receives a score of 0.75. Therefore, Document A would be ranked higher as its final similarity score is greater.
Relevance Scoring: For each query-document pair, the reranking model outputs a similarity score that indicates how relevant the document is to the query. This score is computed using the full transformer model, allowing for a more nuanced understanding of the document's relevance in the context of the query.
Reordering Documents: The documents are then reordered based on their relevance scores. The most relevant documents are moved to the top of the list, ensuring that the most pertinent information is prioritized.
Conclusion
Rerankers offer a promising solution to the limitations of basic RAG pipelines. By reordering retrieved documents based on their relevance to the query, we can improve the accuracy and relevance of generated responses. Additionally, injecting summarization into the context further enhances the LLM's ability to provide accurate answers. While implementing rerankers may introduce additional computational overhead, the benefits in terms of improved accuracy and relevance make it a worthwhile investment.
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your RAG performance with Maxim.