What are Online Evaluations and How to Set Them Up for Your AI System Using Maxim AI

Introduction
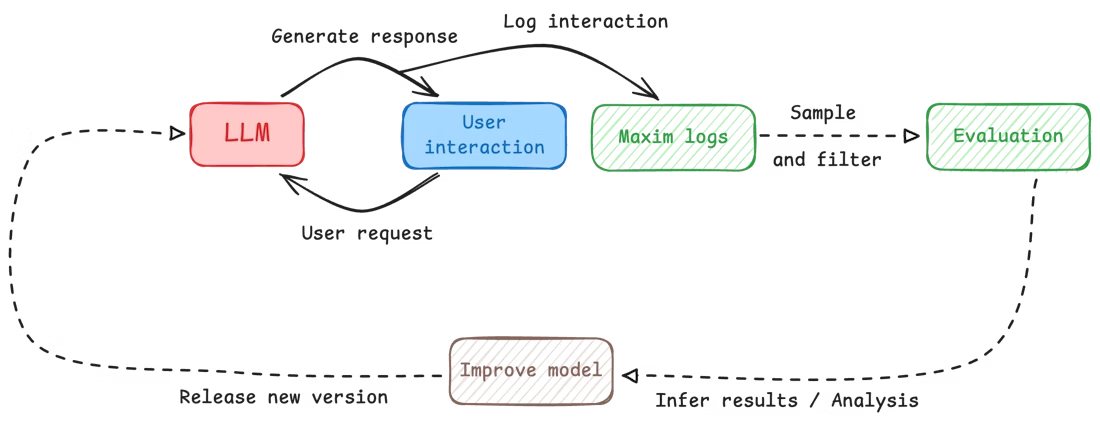
Building an LLM-powered application is one thing; ensuring it performs optimally in production is another challenge entirely. In this blog we will go deeper into Online Evaluations & setting them up for production usecases. Let's start by understanding the difference between Online & Offline Evals.
Online vs. Offline Evaluations
Offline evaluations use curated datasets, scenario simulations, and evaluators to benchmark prompts, workflows, and agents before deployment. They involve running prompt tests or agent tests with predefined datasets and evaluators, comparing versions, and generating reports for regression analysis. Online evaluations, on the other hand, attach evaluators to traces, spans, generations, and retrievals to automatically score real production interactions in real-time. While offline evaluations focus on pre-release testing and experimentation with controlled data, online evaluations provide continuous monitoring and quality checks on live user interactions, helping identify issues that may not have been covered during testing.
Online evaluations allow you to continuously assess your AI application's performance on real production traffic, helping you identify issues early and make necessary adjustments to improve overall performance. In this guide, we'll explore what online evaluations are and how to implement them using Maxim AI's comprehensive evaluation platform.
Why Evaluate Production Logs?
Evaluation on logs helps cover cases or scenarios that might not be covered by test runs, ensuring that the LLM is performing optimally under various real-world conditions. Additionally, it allows for potential issues to be identified early on, which allows for making necessary adjustments to improve the overall performance of the LLM in time.
With Maxim's multi-level evaluation system, you can evaluate at different granularities - from entire conversations (sessions) to individual responses (traces) to specific components (spans) - giving you comprehensive visibility into your AI application's performance.
Understanding Evaluation Levels
Maxim supports evaluating your AI application at three different levels of granularity. This multi-level approach allows you to assess quality at different scopes depending on your use case:
Session-Level Evaluation
Sessions represent multi-turn interactions or conversations. Session-level evaluators assess the quality of an entire conversation flow.
Use session-level evaluation when:
- You want to measure conversation quality across multiple turns
- You need to evaluate multi-turn coherence, context retention, or conversation flow
- You're assessing overall user satisfaction or goal completion
- Your evaluator needs access to the full conversation history
Trace-Level Evaluation
Traces represent single interactions or responses. Trace-level evaluators assess individual completions or responses.
Use trace-level evaluation when:
- You want to measure the quality of individual responses
- You need to evaluate single-turn metrics like helpfulness or accuracy
- You're assessing response-specific attributes like tone or formatting
Span-Level Evaluation
Spans represent specific components within a trace, such as a generation, retrieval, tool call, or custom component. Span-level evaluators assess individual components in isolation.
Use span-level evaluation when:
- You want to evaluate specific components of your agentic workflow
- You need to assess retrieval quality, individual generation steps, or tool usage
- You're optimizing specific parts of your application independently
- You need component-specific metrics for debugging or optimization
As your AI application grows in complexity, it becomes increasingly difficult to understand how it is performing on different flows and components. This granular insight becomes necessary to identify bottlenecks or low quality areas in your application's or agent's flow. By targeting the underperforming areas, you can optimize overall performance more effectively than using brute force approaches.
Setting Up Online Evaluations
Prerequisites
Before you can evaluate your production logs, you need to have your logging set up to capture interactions between your LLM and users. This requires integrating the Maxim SDK into your application.
Method 1: Auto Evaluation via UI
Auto evaluation allows you to automatically run evaluators on your production logs without writing any additional code.
Step 1: Navigate to Your Repository
Access the repository where you want to configure evaluations.
Step 2: Access Evaluation Configuration
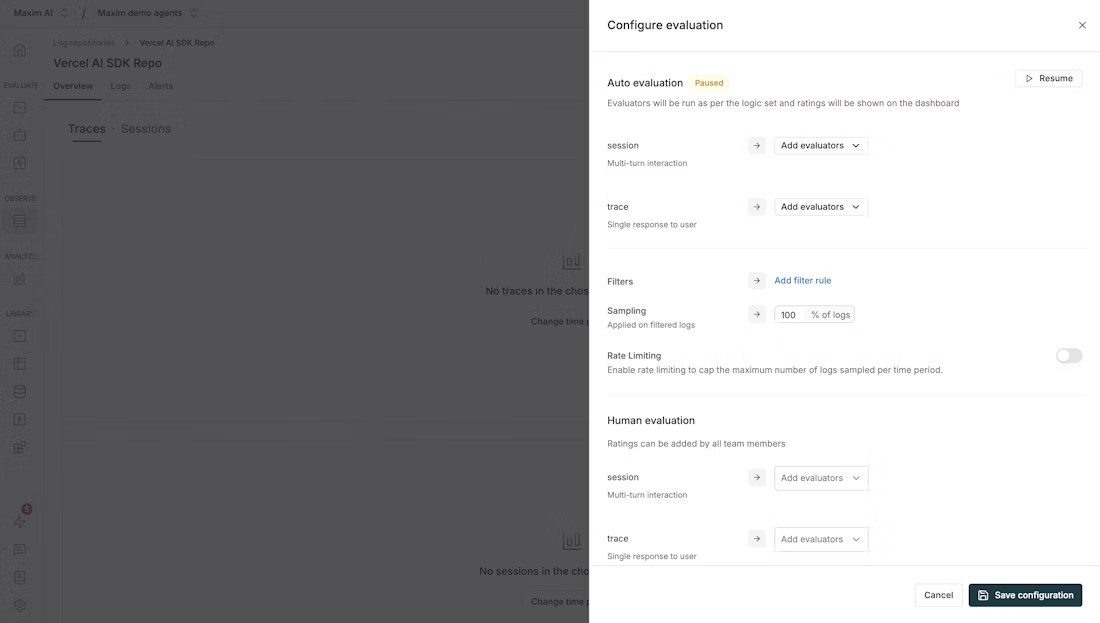
Click the "Configure Evaluation" button in the top right corner of the page. This will open up the evaluation configuration sheet.
Step 3: Configure Evaluators at Each Level
The Auto Evaluation section allows you to configure evaluators at different levels:
- Session: Evaluate multi-turn interactions (conversations) as a whole. Use this when you need to assess the quality of an entire conversation or dialogue flow.
- Trace: Evaluate a single response to a user. Use this for evaluating individual interactions or single completions.
- Span: Evaluate specific components within a trace (configured via the SDK).
Step 4: Add Evaluators
For each level, click "Add evaluators" to select the evaluators you want to run.
Once you select an evaluator, you'll need to map variables to the evaluator's required inputs. For example:
{{input}}might map to the user's input{{output}}might map totrace[*].outputfor session-level ortrace.outputfor trace-level{{context}}might map to retrieved context likeretrieval[*].retrievedChunks[*]
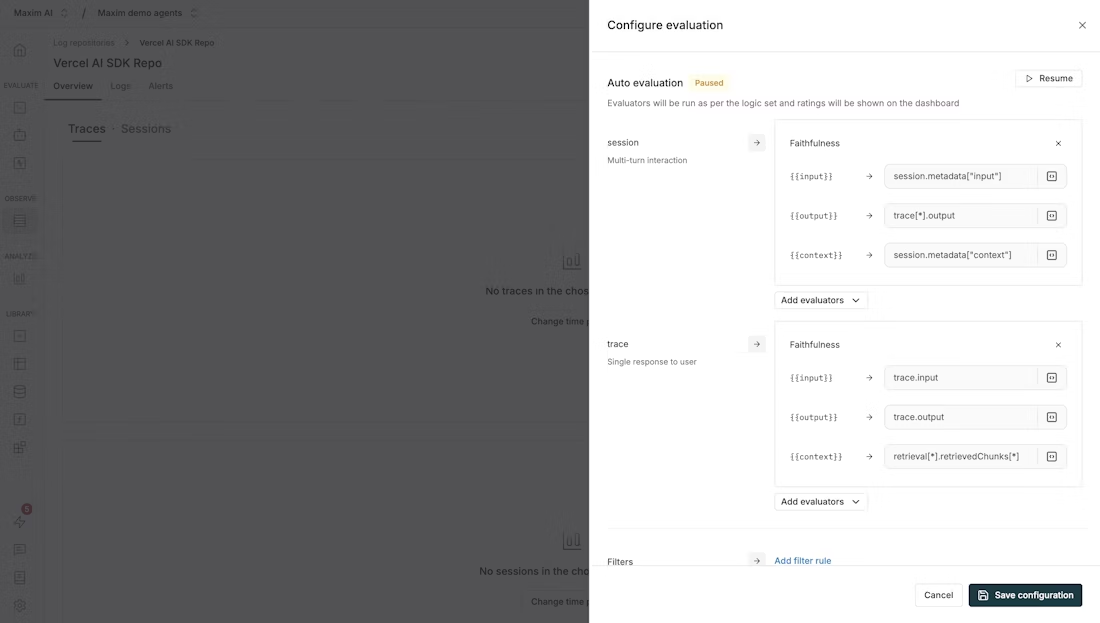
Variable mapping guidelines:
- Use
trace.outputto reference a trace's output - Use
trace[*].outputto reference all outputs in a session - Use
retrieval[*].retrievedChunks[*]to reference retrieved context from retrieval spans - Custom mappings can be created by clicking on the mapping field
Step 5: Configure Filters and Sampling
Click "Add filter rule" to create conditions based on various log properties:
- Trace ID / Session ID: Filter by specific trace or session identifiers
- Input / Output: Filter based on user input or model output content
- Error: Filter logs that have errors or specific error types
- Model: Filter by the LLM model used (e.g., gpt-4, claude-3, etc.)
- Tags: Filter by custom tags you've added to your traces
- Metrics: Filter based on evaluation scores or other metrics
- Cost: Filter by cost thresholds (e.g., only evaluate expensive requests)
- Tokens: Filter by token usage (e.g., evaluate long conversations)
- User Feedback: Filter by user ratings or feedback scores
- Latency: Filter by response time (e.g., evaluate slow requests)
Step 6: Save Configuration
Click "Save configurations" to activate your auto evaluation setup.
Method 2: Node-Level Evaluation via SDK
Node-Level evaluation enables you to evaluate a trace or its component (a span, generation, or retrieval) in isolation. This can be done via the Maxim SDK's logger using a very simple API.
How the Maxim SDK Logger Evaluates
Two actions are mainly required to evaluate a node:
- Attach Evaluators: This action defines what evaluators to run on the particular node. This needs to be called to start an evaluation on any component.
- Attach Variables: Once evaluators are attached on a component, each evaluator waits for all the variables it needs to evaluate to be attached to it. Only after all the variables an evaluator needs are attached, does it start processing.
Important notes:
- The evaluator will not run until all of the variables it needs are attached to it.
- If we don't receive all the variables needed for an evaluator for over 5 minutes, we will start displaying a
Missing variablesmessage (although we will still process the evaluator even if variables are received after 5 minutes).
Attaching Evaluators
Use the with_evaluators method to attach evaluators to any component within a trace or the trace itself:
component.evaluate.withEvaluators("evaluator");
// example
generation.evaluate.withEvaluators("clarity", "toxicity");
If you list an evaluator that doesn't exist in your workspace but is available in the store, Maxim will auto-install it for you. If the evaluator is not available in the store as well, it will be ignored.
Providing Variables to Evaluators
Once evaluators are attached to a component, variables can be passed to them via the with_variables method. This method accepts a key-value pair of variable names to their values.
You also need to specify which evaluators you want these variables to be attached to, which can be done by passing the list of evaluator names as the second argument.
component.evaluate.withVariables(
{ variableName: "value" }, // Key-value pair of variables
["evaluator"], // List of evaluators
);
// example
retrieval.evaluate.withVariables(
{ output: assistantResponse.choices[0].message.content },
["clarity", "toxicity"],
);
You can directly chain the with_variables method after attaching evaluators to any component, allowing you to skip mentioning the evaluator names again:
trace.evaluate
.withEvaluators("clarity", "toxicity")
.withVariables({
input: userInput,
});
Example: Basic Generation Evaluation
import maxim
from maxim.decorators import trace, generation
# Initialize logger
logger = maxim.Logger(api_key="your-api-key")
@logger.trace(name="customer_support_chat")
def handle_customer_query(user_message: str):
# Create a generation for the AI response
generation_config = {
"id": "support-response-001",
"provider": "openai",
"model": "gpt-4",
"messages": [
{"role": "system", "content": "You are a helpful customer support agent."},
{"role": "user", "content": user_message}
],
"model_parameters": {"temperature": 0.7, "max_tokens": 500},
"name": "customer_support_response"
}
generation = logger.current_trace().generation(generation_config)
# Attach evaluators to the generation
generation.evaluate().with_evaluators("clarity", "toxicity", "helpfulness")
# Provide input variable for all evaluators
generation.evaluate().with_variables(
{"input": user_message},
["clarity", "toxicity", "helpfulness"]
)
# Simulate AI response
ai_response = "Thank you for contacting us. I understand your concern about..."
generation.result({
"choices": [{"message": {"content": ai_response, "role": "assistant"}}],
"usage": {"total_tokens": 150}
})
# Provide output variable for evaluation
generation.evaluate().with_variables(
{"output": ai_response},
["clarity", "toxicity", "helpfulness"]
)
return ai_response
Example: RAG System Evaluation
import maxim
from maxim.decorators import trace, generation, retrieval
logger = maxim.Logger(api_key="your-api-key")
@logger.trace(name="rag_question_answering")
def answer_question_with_rag(question: str, knowledge_base: list):
# Step 1: Retrieve relevant documents
@retrieval(name="document_retrieval", evaluators=["Ragas Context Relevancy"])
def retrieve_documents(query: str):
retrieval = maxim.current_retrieval()
retrieval.input(query)
# Attach evaluation variables
retrieval.evaluate().with_variables(
{"input": query},
["Ragas Context Relevancy"]
)
# Simulate document retrieval
relevant_docs = [
{"content": "Document 1 content...", "relevance_score": 0.9},
{"content": "Document 2 content...", "relevance_score": 0.7}
]
retrieval.output(relevant_docs)
# Provide context for evaluation
retrieval.evaluate().with_variables(
{"context": str(relevant_docs)},
["Ragas Context Relevancy"]
)
return relevant_docs
# Step 2: Generate answer using retrieved context
retrieved_docs = retrieve_documents(question)
generation_config = {
"id": "rag-answer-generation",
"provider": "openai",
"model": "gpt-4",
"messages": [
{
"role": "system",
"content": "Answer the question using the provided context. Be accurate and helpful."
},
{"role": "user", "content": f"Question: {question}\nContext: {retrieved_docs}"}
],
"name": "rag_answer_generation"
}
generation = logger.current_trace().generation(generation_config)
# Attach multiple evaluators
generation.evaluate().with_evaluators(
"clarity", "accuracy", "completeness", "relevance"
)
# Provide input variables
generation.evaluate().with_variables(
{
"input": question,
"context": str(retrieved_docs)
},
["clarity", "accuracy", "completeness", "relevance"]
)
# Generate answer
answer = "Based on the provided context, the answer is..."
generation.result({
"choices": [{"message": {"content": answer, "role": "assistant"}}]
})
# Provide output for evaluation
generation.evaluate().with_variables(
{"output": answer},
["clarity", "accuracy", "completeness", "relevance"]
)
return answer
Advanced: Custom Local Evaluators
You can create custom evaluators by inheriting from BaseEvaluator:
from maxim.evaluators import BaseEvaluator
from maxim.models import (
LocalEvaluatorResultParameter,
LocalData,
LocalEvaluatorReturn,
PassFailCriteria,
PassFailCriteriaOnEachEntry,
PassFailCriteriaForTestrunOverall
)
import re
from typing import Dict
class CustomQualityEvaluator(BaseEvaluator):
"""Custom evaluator for assessing response quality"""
def evaluate(self, result: LocalEvaluatorResultParameter, data: LocalData) -> Dict[str, LocalEvaluatorReturn]:
output = result.output
context = result.context_to_evaluate
# Calculate quality score based on multiple factors
clarity_score = self._assess_clarity(output)
completeness_score = self._assess_completeness(output, context)
relevance_score = self._assess_relevance(output, context)
# Weighted average
overall_score = (clarity_score * 0.4 + completeness_score * 0.3 + relevance_score * 0.3)
reasoning = f"Quality assessment: Clarity={clarity_score:.2f}, Completeness={completeness_score:.2f}, Relevance={relevance_score:.2f}"
return {
"quality_score": LocalEvaluatorReturn(
score=overall_score,
reasoning=reasoning
)
}
def _assess_clarity(self, text: str) -> float:
"""Assess text clarity based on readability metrics"""
sentences = len(re.split(r'[.!?]+', text))
words = len(text.split())
avg_sentence_length = words / max(sentences, 1)
if avg_sentence_length > 30:
return 0.3
elif avg_sentence_length > 20:
return 0.6
else:
return 0.9
def _assess_completeness(self, output: str, context: str) -> float:
"""Assess how completely the output addresses the context"""
if not context:
return 0.5
output_words = set(output.lower().split())
context_words = set(context.lower().split())
if len(context_words) == 0:
return 0.5
overlap = len(output_words.intersection(context_words))
return min(overlap / len(context_words), 1.0)
def _assess_relevance(self, output: str, context: str) -> float:
"""Assess relevance of output to context"""
if not context:
return 0.5
output_lower = output.lower()
context_lower = context.lower()
context_terms = context_lower.split()
relevant_terms = [term for term in context_terms if term in output_lower]
if len(context_terms) == 0:
return 0.5
return len(relevant_terms) / len(context_terms)
# Usage with custom evaluator
custom_evaluator = CustomQualityEvaluator(
pass_fail_criteria={
"quality_score": PassFailCriteria(
on_each_entry_pass_if=PassFailCriteriaOnEachEntry(">=", 0.7),
for_testrun_overall_pass_if=PassFailCriteriaForTestrunOverall(">=", 0.8, "average")
)
}
)
generation.evaluate().with_evaluators("clarity", custom_evaluator)
Setting Up Human Evaluation
While automated evaluators can provide baseline assessments, they may not capture nuanced human judgment, context, and emotional understanding. Human evaluation complements automated evaluation by providing qualitative feedback, detailed comments, and rewritten outputs that help refine your AI applications.
Prerequisites
Before setting up human evaluation:
- Integrate the Maxim SDK into your application
- Create a Human Evaluator in your workspace by navigating to the Evaluators tab from the sidebar
Configuration Steps
Step 1: Navigate to Repository and Configure Evaluation
Click the "Configure evaluation" button in the top right corner of the page to open the evaluation configuration sheet.
Step 2: Select Human Evaluators
In the Human Evaluation section, click "Add evaluator" and choose from:
- Session evaluators: For multi-turn interactions (sessions)
- Trace evaluators: For single responses (traces)
Step 3: Save Configuration
Click "Save configurations" at the bottom of the sheet to save your human evaluation setup.
Annotating Logs
You can annotate logs from two places:
From the Logs Table
When human evaluators are configured, columns for each evaluator appear in the logs table:
- Click on any cell in a human evaluator column
- In the annotation form, provide a rating for that evaluator
- Optionally add comments or provide a rewritten output
- Click Save to submit your annotation
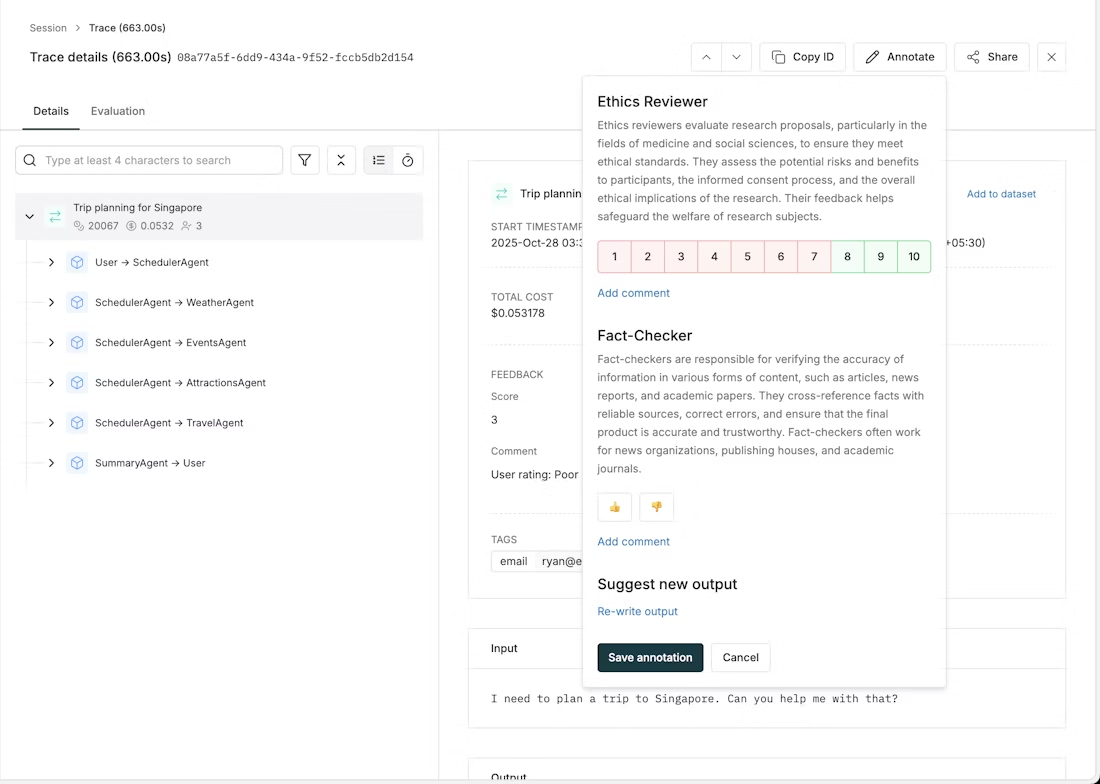
From Trace Details
- Open any trace from the logs table
- Click the Annotate button in the top right corner of the trace details sheet
- In the annotation form, provide ratings for all configured human evaluators at once
- Optionally add comments for each evaluator or provide a rewritten output
- Save your annotations
Using Saved Views for Annotation Queues
To make specific views based on filters for raters to annotate, you can use saved views. This allows you to create filtered queues of logs that need annotation. Raters can:
- Apply filters to narrow down logs that need annotation (e.g., unannotated logs, specific time ranges, or certain criteria)
- Save these filtered views for quick access
- Use saved views to work through annotation queues systematically
Understanding Annotation Scores
- Average scores: When multiple team members annotate the same log, the average score is shown in the table columns
- Individual breakdown: Click on any annotation to see individual scores, comments, and rewritten outputs from each annotator
- Pass/fail: Scores are evaluated against pass/fail criteria defined in the evaluator configuration
- Rewritten outputs: Multiple team members can provide rewritten outputs; all versions are visible in the trace details view
Viewing Evaluation Results
In the Logs Table View
In the logs' table view, you can find the evaluations on a trace in its row towards the left end, displaying the evaluation scores. You can sort the logs by evaluation scores as well by clicking on either of the evaluators' column header.
In the Trace Details
Click on a trace to open its details sheet, then navigate to the Evaluation tab, wherein you can see the evaluation in detail.
Evaluation Summary
The evaluation summary displays the following information (top to bottom, left to right):
- How many evaluators passed out of the total evaluators across the trace
- How much did all the evaluators' evaluation cost
- How many tokens were used across all evaluators' evaluations
- What was the total time taken for the evaluation to process
Evaluation Cards by Level
Depending on what levels you configured evaluators for, you'll see separate evaluation cards:
- Session evaluation card: Shows evaluators that ran on the entire session (multi-turn conversation)
- Trace evaluation card: Shows evaluators that ran on the individual trace (single interaction)
- Span evaluation cards: Shows evaluators that ran on specific components within the trace (configured via SDK)
Overview Tab
Shows a summary of all evaluators and their results at the current level.
Individual Evaluator's Tab
Each evaluator has its own tab showing:
- Result: Shows whether the evaluator passed or failed
- Score: Shows the score of the evaluator
- Reason (shown where applicable): Displays the reasoning behind the score of the evaluator, if given
- Cost (shown where applicable): Shows the cost of the individual evaluator's evaluation
- Tokens used (shown where applicable): Shows the number of tokens used by the individual evaluator's evaluation
- Model latency (shown where applicable): Shows the time taken by the model to respond back with a result for an evaluator
- Time taken: Shows the time taken by the evaluator to evaluate
- Variables used to evaluate: Shows the values that were used to replace the variables with while processing the evaluator
- Logs: These are logs that were generated during the evaluation process. They might be useful for debugging errors or issues that occurred during the evaluation
Tree View on the Left Panel
The tree view shows the hierarchical structure of your trace, with evaluation results displayed at each level.
Dataset Curation from Evaluations
Once you have logs and evaluations in Maxim, you can easily curate datasets by filtering and selecting logs based on different criteria.
Steps to Curate Datasets
- Filter logs with specific evaluation scores (e.g., bias score greater than 0)
- Select all filtered logs using the top-left selector
- Click the "Add to dataset" button that appears
- Choose to add logs to an existing dataset or create a new dataset
- Map the columns and click "Add entries"
This workflow allows you to systematically build datasets from your production logs based on evaluation results, which can be used for further testing, fine-tuning, or analysis.
Setting Up Alerts and Notifications
Maxim allows you to set up alerts and notifications to stay informed about your AI application's performance in real-time.
Notification Channels
Maxim supports multiple notification channels:
- Slack: Receive alerts directly in your Slack workspace
- PagerDuty: Integrate with your incident management workflow
Managing Integrations
You can manage your notification channel integrations in the following ways:
- Edit an integration: Hover over the integration on the Integrations page and click the edit icon
- Delete an integration: Hover over the integration and click the delete icon
- View integration details: Click on the integration to see its configuration and usage
Performance Metrics Alerts
Monitor your application's performance by setting up alerts for latency, token usage, and cost metrics.
Available Performance Metrics
Set up alerts for:
- Latency: Response times for API calls
- Token Usage: Token consumption per request
- Cost: API usage expenses
Creating Performance Alerts
- Navigate to repository and access the repository where you want to set up alerts
- Access alerts tab within the repository
- Configure alert settings:
- Select Log metrics as the type of alert
- Select a metric (Latency, Token Usage, or Cost)
- Choose an operator (greater than, less than)
- Enter the threshold value
- Set minimum occurrence count
- Define evaluation time range
- Select notification channels: Choose where you want to receive alerts
- Save your alert
Performance Alert Examples
Monitor Response Time:
- Metric: Latency
- Operator: Greater than
- Threshold: 2000ms
- Occurrences: 5 times
- Time range: Last 15 minutes
Monitor Token Consumption:
- Metric: Token Usage
- Operator: Greater than
- Threshold: 10000 tokens
- Occurrences: 3 times
- Time range: Last hour
Monitor Daily Costs:
- Metric: Cost
- Operator: Greater than
- Threshold: $100
- Occurrences: 1 time
- Time range: Last 24 hours
Quality Metrics Alerts
Monitor your AI application's quality with alerts for evaluation scores and quality checks.
Available Quality Metrics
Set up alerts for various evaluation scores, such as:
- Bias-check: Monitor potential biases in AI responses
- Toxicity: Check for inappropriate or harmful content
- Clarity: Validate clear and understandable output
- Factual accuracy: Verify generated information accuracy
- Custom evaluators: Monitor your defined evaluation metrics
Creating Quality Alerts
- Navigate to repository and access the repository
- Access alerts tab within the repository
- Select alert type as Evaluation metrics
- Configure alert settings:
- Choose an evaluation metric (e.g., "Bias-check")
- The violation criteria is based on your evaluator's type and configuration
- Specify how many times this should occur
- Set the evaluation time range
- Choose notification channels: Select where you want to receive alerts
- Save your alert
Quality Alert Examples
Bias Check Alert:
- Evaluator: Bias-check
- Condition: Score > 0.7
- Occurrences: 2 times
- Time range: Last hour
Toxicity Alert:
- Evaluator: Toxicity
- Condition: Failed
- Occurrences: 1 time
- Time range: Immediate
Managing Alerts
Manage your alerts in the following ways:
- Edit an alert: Click the options icon (three dots) on the alert card and select "Edit alert"
- Delete an alert: Click the options icon and select "Delete alert"
- Pause/Resume an alert: Click the options icon and select "Pause alert" or "Resume alert"
Conclusion
Online evaluations are essential for maintaining and improving the quality of AI applications in production. Maxim AI provides a comprehensive platform for implementing multi-level evaluations, from high-level session assessments to granular component-level analysis.
By combining automated evaluations with human annotations and real-time alerting, you can ensure your AI system maintains high quality standards while identifying and addressing issues before they impact users. The flexibility to evaluate at different levels - sessions, traces, and spans - allows you to optimize your application systematically and effectively.
Start implementing online evaluations today to gain deeper insights into your AI application's performance and take your production quality monitoring to the next level.


