Synthetic data generation, Retro evals, Workspace-level RBAC and more

🎙️ Feature spotlight
🔢 Synthetic Data Generation
You can now generate synthetic datasets in Maxim to simplify and accelerate the testing and simulation of your Prompts and Agents. Use this to create inputs, expected outputs, simulation scenarios, personas, or any other variable needed to evaluate single and multi-turn workflows across Prompts, HTTP endpoints, Voice, and No-code agents on Maxim.
You can generate datasets from scratch by defining the required columns and their descriptions, or use an existing dataset as a reference context to generate data that follows similar patterns and quality.
You can include the description of your agent (or its system prompts) or add a file as a context source to guide generation quality and ensure the synthetic data remains relevant and grounded. (Read more on Synthetic data generation)
Generate synthetic test data in Maxim
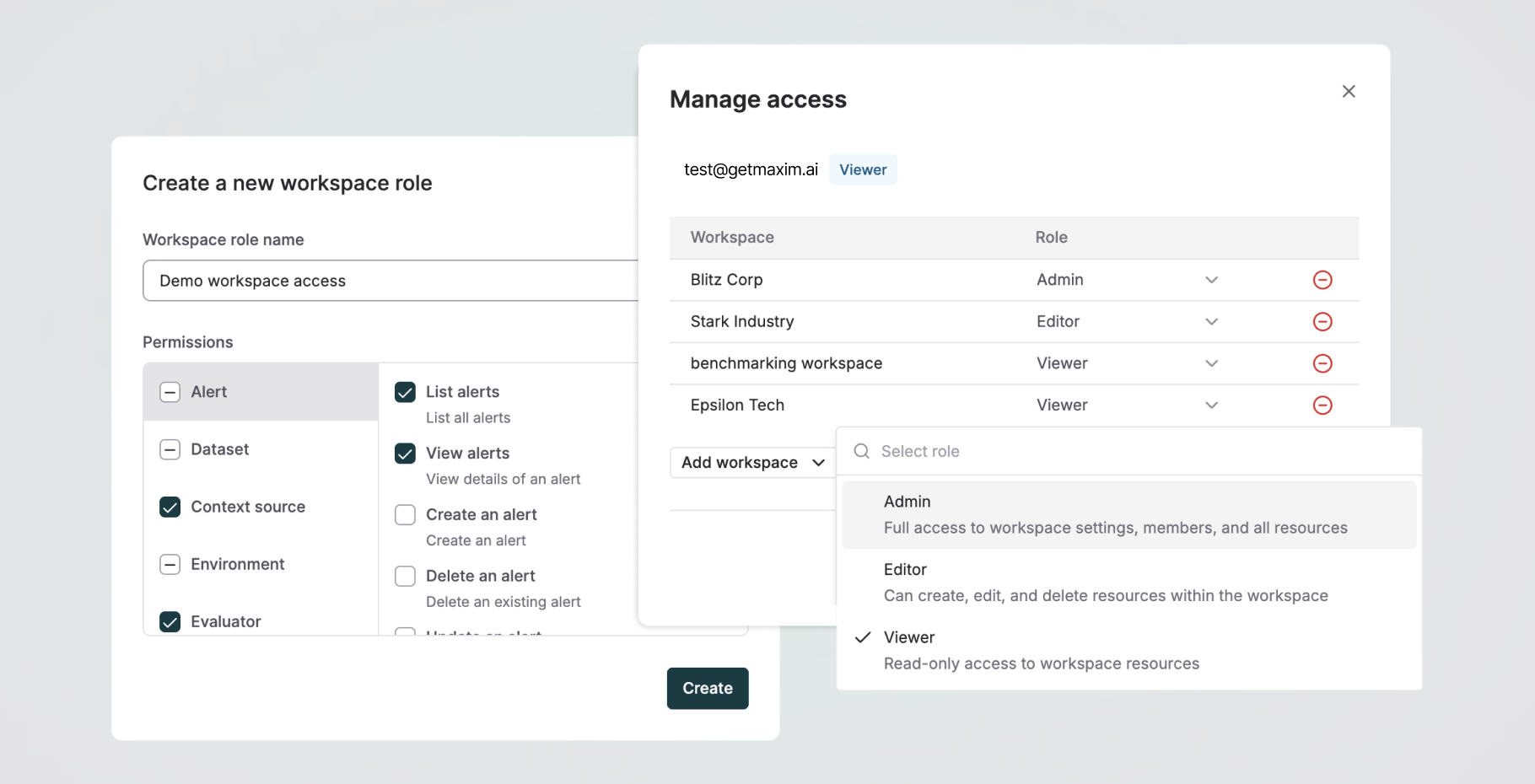
👥 Workspace-level RBAC
We’ve enhanced Role-Based Access Control (RBAC) in Maxim to give you finer control over access management.
Previously, roles were assigned only at the organization level, giving users the same scope of access across all workspaces they were part of. Now, you can assign different roles to users per workspace and also create custom roles with precise permissions for the resources and actions a member can access, specific to a workspace.
This gives teams granular, functional control over what users can view or do – e.g., allowing someone to create, deploy, or delete a prompt in one workspace while granting read-only access in another – making collaboration more secure, flexible, and scalable.
♻️ Retroactive evals on Logs
You can now attach evaluations to any log, trace, or session in Maxim. Instead of only evaluating new logs after setup, you can now run evals on historical logs – even if online evals weren’t previously configured. This enables you to analyze past data and gain granular, node-level insights into agent performance. Key highlights:
- Run evals on past logs by simply selecting those traces/sessions and adding evaluators based on the key metrics you wish to track.
- This helps you track agent performance over an extended timeframe to get a clear, metric-driven view of quality improvements or degradations.
- Filter logs by failure scenarios and re-run or attach additional evals for iterative debugging and deeper analysis.
Attach and run evals on historical logs
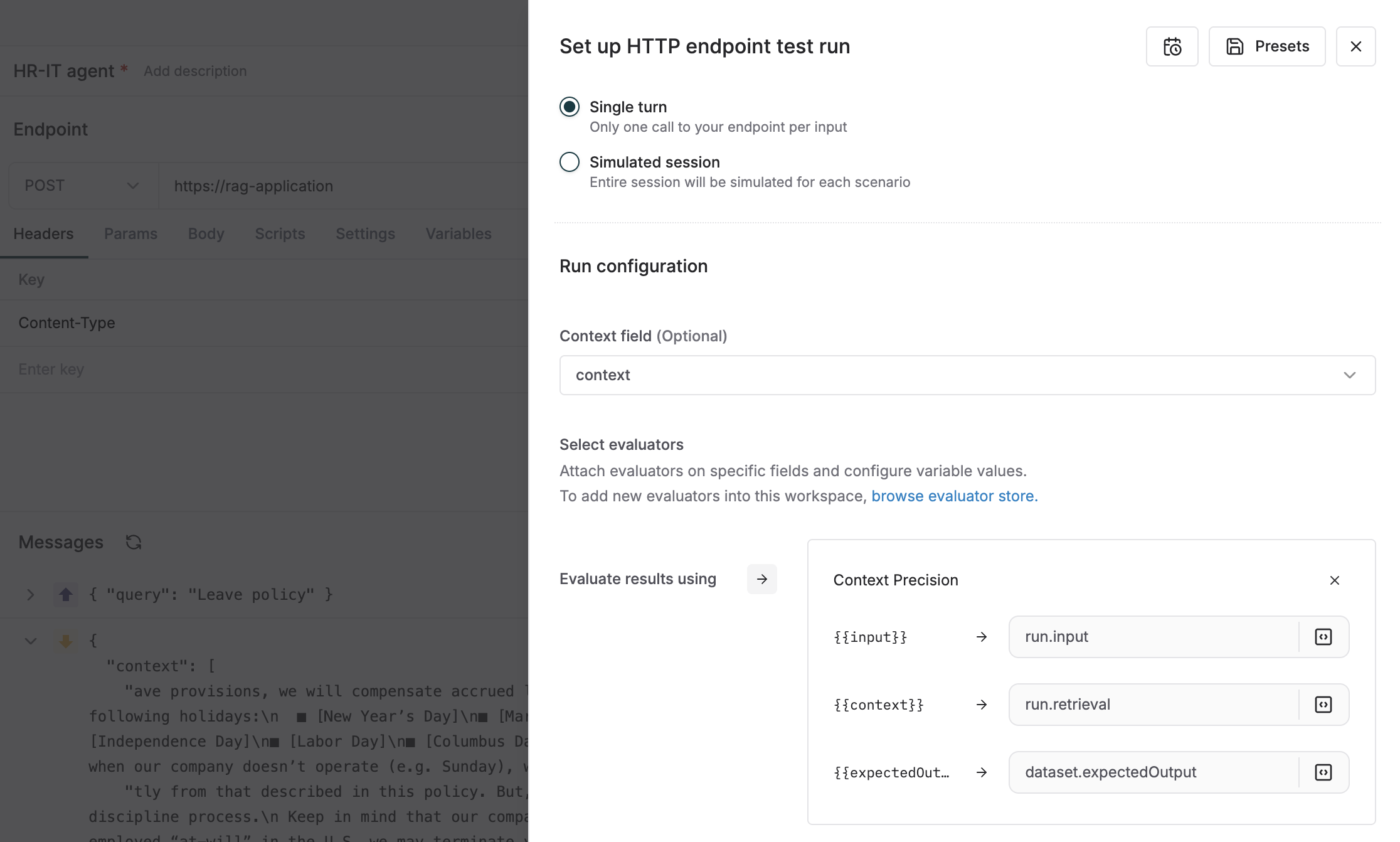
⚙️ Flexible evaluators on all test run entities
Running evals across Maxim is now fully configurable. We've extended the Flexi eval capability beyond logs to include Prompt, No-code, HTTP and Voice agent testing and simulations.
Instead of being limited to predefined parameters like input, output, context, etc, you can now decide exactly which value in the user query, agent response, or test dataset should be mapped to the corresponding field for your evaluators. This makes your evaluators highly reusable and helps eliminate noise from evaluation parameters.
🚅 LiteLLM support
We’ve added LiteLLM as a provider in Maxim, enabling you to use models already configured in LiteLLM without needing to add them separately in Maxim. This ensures unified model access, governance, and load balancing through a single configuration.
On that point, let me introduce you to a faster (50x), more scalable, and feature-packed alternative to LiteLLM...
⚡ Bifrost: The fastest LLM gateway
Written in Go, Bifrost adds just 11μs of latency at 5k RPS. When benchmarked at 500 RPS on identical hardware, Bifrost came out ~50x faster than LiteLLM (P99 Latency- Benchmarks). Beyond this, LiteLLM breaks with latency going up to 4 minutes.

🧩 Dynamic plugins
We’ve introduced Dynamic plugins in Bifrost, giving you the flexibility to create and manage your own custom plugins without needing to raise a PR or wait for new releases. You can build plugins tailored to your specific needs, and we've optimized the performance to ensure latency remains unchanged even when plugins are enabled.
With Pre-hooks and Post-hooks, you can run custom logic before or after an LLM call, and use the data being sent to or received from the model in any way your workflow or use case requires.
👨💻 Tools & CLI agent integration
You can now use Bifrost seamlessly with tools like LibreChat, Claude Code, Codex CLI, and Qwen Code by simply changing the base URL and unlock Bifrost's advanced capabilities, such as universal model access, MCP tool integration, real-time observability, load balancing, and built-in governance, caching, and failover. (Read docs)
🎁 Upcoming releases
🔢 Insights
Insights is Maxim’s new analytics agent that lets you converse with your logs. Instead of searching through dashboards or writing complex queries, you can simply ask questions in natural language to get relevant sessions, traces, and reasoning of agent behavior – helping you debug faster and understand performance more intuitively.
🧠 Knowledge nuggets
🤖 Choosing the right AI agent framework: A guide
Selecting the right open-source AI agent framework is key to building systems that are both reliable and scalable. Each framework, LangGraph, CrewAI, Smolagents, and LlamaIndex, has its own strengths in terms of how agents plan, remember, and coordinate complex tasks.
The trade-offs often come down to state management, composability, and how well the framework integrates into your existing stack. If you’re evaluating which framework best fits your goals, here’s a guide to help you decide.



