Speculative Speculative Decoding: How Researchers Are Teaching LLMs to Think Ahead of Themselves

The Problem Nobody Talks About Enough
You've probably noticed that ChatGPT, Claude, or any large language model streams text to you token by token, one word (or part of a word) at a time. This is a fundamental constraint of how these models work.
Every time a transformer generates a token, it has to run a full forward pass through the entire model. For a 70-billion-parameter model, that's an enormous amount of computation, just to produce one token. And then it has to do it again. And again. Each step sequentially depends on the last. You can't generate token 10 until you have token 9.
This is the autoregressive bottleneck, and it's one of the central unsolved problems in making LLM inference fast enough to be cheap and widely accessible.
The frustrating part? Modern GPUs are incredibly parallel machines. Thousands of cores, capable of doing massive matrix multiplications simultaneously. But the token-by-token nature of language generation leaves most of that hardware sitting idle most of the time. We've built sports cars and we're stuck in a school zone.
Enter Inference Optimization
The research community has attacked this problem from several angles.
Hardware-level tricks like FlashAttention restructure how attention computation reads and writes to GPU memory, dramatically reducing the memory bottleneck without changing model outputs at all. PagedAttention does something similar for the KV cache (the big block of intermediate state that grows as sequences get longer).
Quantization shrinks model weights from 32-bit or 16-bit floats down to 8-bit or even 4-bit integers, trading a small amount of precision for big reductions in memory and compute.
Batching lets you process many user requests simultaneously so the GPU stays busy. But for latency-sensitive applications (think: real-time chatbots), you can't afford to wait for a full batch to accumulate.
All of these help. None of them fundamentally change the sequential nature of generation.
That's where speculative decoding comes in.
Speculative Decoding
The insight behind speculative decoding is this: what if we could guess what the big model is going to say, and then verify those guesses in one shot?
Here's how it works in practice. You have two models:
- A target model: the big, expensive, high-quality model you actually care about (say, Llama-3.1-70B)
- A draft model: a much smaller, faster model (say, Llama-3.2-1B) that tries to predict what the target would say
Instead of asking the target model to generate one token at a time, you let the draft model sprint ahead and propose the next K tokens (say, 5 tokens) all at once. Then you ask the target model to verify all 5 of those tokens in a single forward pass. Because the target model can attend to all positions in parallel, verifying 5 tokens costs only slightly more than generating 1.
If the draft got all 5 right, you've effectively generated 5 tokens for the price of ~1. If it got the first 3 right and the 4th wrong, you take the first 3, throw away 4 and 5, and sample a corrected token from the target. Either way, the outputs are mathematically identical to what the target model would have generated on its own. This is lossless, since you're not approximating anything.
The efficiency gain depends on the acceptance rate: how often the draft model's guesses are accepted by the target. If the draft is pretty good and the target tends to agree with it, acceptance rates can be 70–85%, which translates to meaningful end-to-end speedups of 2–3x in practice. Draft models from the same family as the target (same pretraining data, just smaller) tend to work well because they've learned similar patterns.
This has become a widely deployed technique. vLLM, SGLang, and other production inference engines support it out of the box.
The Sitch: Speculative Decoding Is Also Sequential
Here's the thing that the new paper points out, and once you see it you can't unsee it.
Speculative decoding has its own sequential bottleneck.
The flow looks like this:
Draft speculates 5 tokens
→ Target verifies those 5 tokens
→ Draft speculates the next 5 tokens
→ Target verifies those 5 tokens
→ ...
While the target is verifying, the draft model is just... sitting there. Idle. And while the draft is speculating, the target model is sitting there. Idle.
The draft and target are taking turns, not working together. It's like two people trying to assemble IKEA furniture where one person holds the manual and the other holds the screwdriver, and they can only hand things off one at a time.
This is the gap that the new paper, Speculative Speculative Decoding, aims to close.
Speculative Speculative Decoding: The Key Idea
The paper from Stanford and Together AI, introduces SSD: a framework for running drafting and verification in parallel, on separate hardware.
The core idea is beautifully simple: while the target model is busy verifying the current round's speculation, don't let the draft model sit idle. Instead, have it preemptively speculate for what happens next across all the possible ways the current verification might turn out.
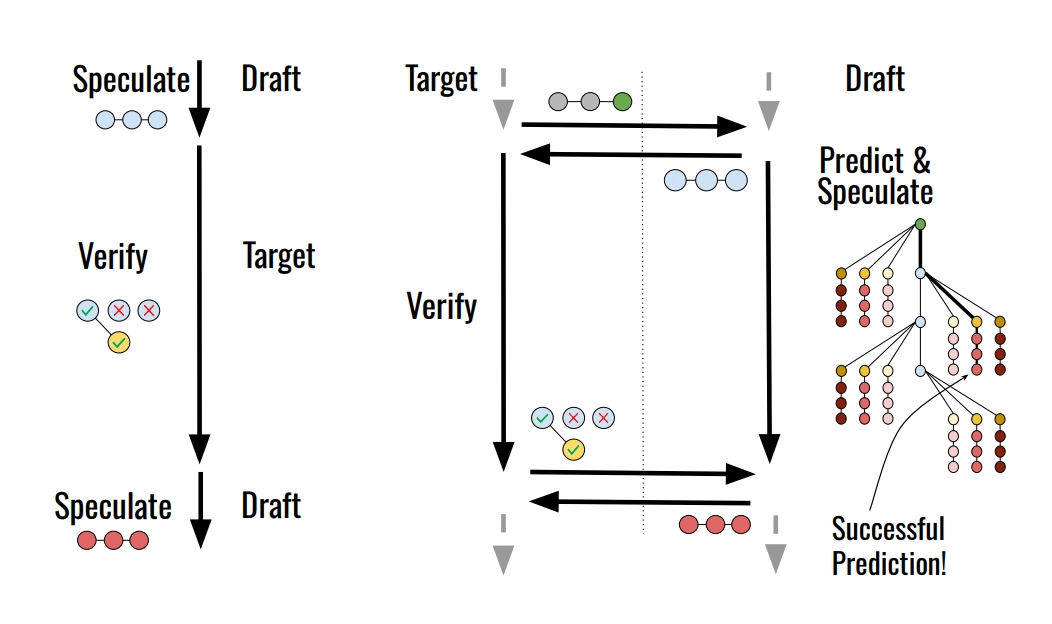
This requires solving a genuinely hard subproblem: the draft doesn't know yet what the target is going to accept or reject. So it has to predict the verification outcome and pre-generate speculations for the most likely outcomes in advance.
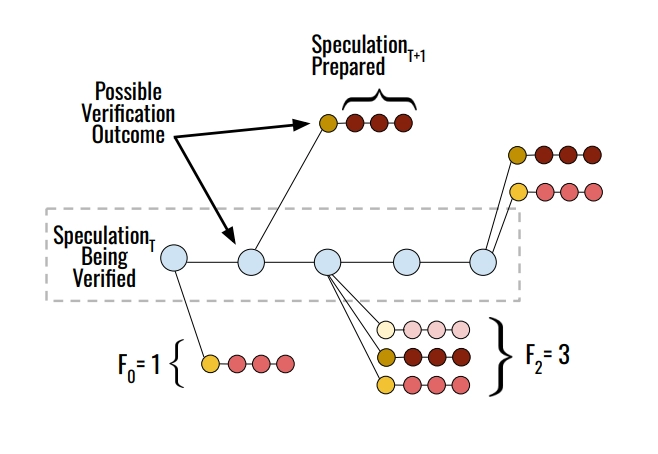
The draft stores these pre-generated continuations in a speculation cache, which is a lookup table keyed by verification outcomes. When the target finishes verifying and sends back the result, the draft checks: "did I already pre-compute a speculation for this outcome?" If yes, cache hit: it can immediately send those tokens to the target for the next round, with essentially zero latency. If no, cache miss: it falls back to generating just-in-time, like regular speculative decoding.
The analogy the paper draws is apt: this is basically speculative execution from CPU architecture, where processors pre-execute both branches of an if statement before they know which branch will be taken, then discard the wrong one. Same philosophy, applied to language model inference.
Critically, SSD is also lossless. Because the verified tokens still go through the same acceptance/rejection algorithm, the distribution of outputs is identical to what the target model would generate on its own.
Three Problems to Solve
This is a lovely idea, but making it actually work requires tackling three tricky challenges. The paper's main contribution, which they call Saguaro, is an optimized SSD algorithm that handles each one.
1. Predicting Verification Outcomes
The space of possible verification outcomes is huge. The verifier could accept anywhere from 0 to K tokens, and then sample any token from the vocabulary as the "bonus" token. You can't precompute speculations for all of them.
Saguaro frames this as a constrained optimization problem: given a limited budget (how many branches can the draft compute before verification finishes?), how should you allocate that compute across different possible outcomes?
The key insight is that the probability of a particular outcome follows the acceptance rate of the draft. If your draft has an 80% acceptance rate per token, then the outcome "5 tokens accepted" is roughly 80%⁵ ≈ 33% likely, "4 tokens accepted" is ~16% likely, and so on. You want to put more guesses where outcomes are more probable, and fewer where they're rare.
The paper derives that the optimal strategy is a geometric fan-out: allocate more guesses to positions that are more likely to be the rejection point, weighted by the acceptance rate distribution. This turns out to improve cache hit rates and end-to-end speed, especially at higher temperatures where verification outcomes are harder to predict.
2. The Acceptance Rate vs. Cache Hit Rate Tradeoff
Here's a subtle tension the paper uncovers. To maximize cache hit rates, the draft model wants to make the bonus token easier to predict. The bonus token is sampled from something called the residual distribution, ie. roughly, the part of the target's probability mass that isn't covered by the draft. If the draft covers the top-probability tokens heavily, the residual falls on low-probability tokens, which are hard to guess.
But if you deliberately under-sample the top draft tokens, you push more residual mass back onto those same tokens, making them easier to predict. The catch is that doing this also moves the draft distribution further from the target, which reduces the acceptance rate.
Saguaro introduces a novel sampling scheme to navigate this tradeoff. It works by downweighting the draft probabilities on the cached tokens by a factor C (a tunable hyperparameter). Setting C close to 0 maximizes cache hit rate at the expense of acceptance rate; setting C=1 is standard speculative decoding. The paper proves this monotonically increases cache hit rates as C decreases, and demonstrates empirically that the sweet spot for end-to-end speed is somewhere in the middle.
3. Handling Cache Misses Gracefully
Cache misses happen. At higher temperatures, at larger batch sizes, when the draft just guesses wrong, you need a fallback.
The naive fallback is to just do regular speculative decoding (generate just-in-time). But here's the batch size problem: in a batch of requests, if any single sequence has a cache miss, the entire batch has to wait for the fallback speculator to finish before the target can verify. The more sequences you're processing, the more likely at least one of them misses. At large batch sizes, misses become near-certain, and the whole batch stalls on the fallback latency.
This leads to Saguaro's adaptive fallback strategy: at small batch sizes, use the high-quality primary speculator as the fallback (slower but better). At large batch sizes, switch to an ultra-fast, low-quality fallback. The paper uses random tokens, but notes n-gram models would work well here because the priority is minimizing the stall time, not maximizing acceptance rate. The paper derives the exact crossover batch size b* mathematically, which turns out to depend on the draft latency, the acceptance rate, and the expected tokens per round.
But How Well Does It Actually Work?
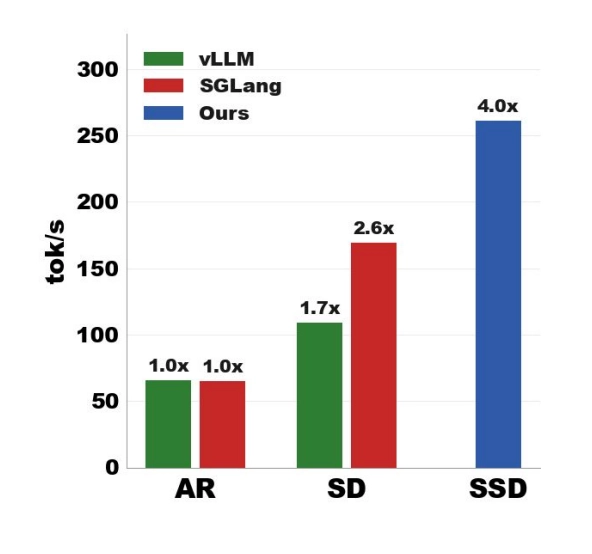
Quite well. The paper benchmarks Saguaro on Llama-3.1-70B (using a Llama-3.2-1B draft) and Qwen-3-32B (using a Qwen-3-0.6B draft), across four datasets spanning math (GSM8k), code (HumanEval), chat (Alpaca), and instruction following (UltraFeedback).
The headline numbers:
| Setup | Speed |
|---|---|
| Autoregressive (baseline) | 54.7 tok/s |
| Speculative Decoding | 161.8 tok/s (~3x) |
| Saguaro (SSD) | 255.8 tok/s (~4.7x) |
That's roughly 1.58x faster than speculative decoding and 4.7x faster than autoregressive on average, for Llama-70B at batch size 1. On math and code tasks where drafts are especially good, SSD hits over 5x autoregressive speed.
The Pareto frontier result is also notable: SSD doesn't just improve latency: it also improves the throughput-latency tradeoff curve across batch sizes. You're getting more out of the hardware, not just shuffling compute around.
The implementation runs on 5 H100s total: 4 for the target model (via tensor parallelism, as you'd need for a 70B model) and 1 dedicated to the draft model running asynchronously. The draft GPU is the price you pay for the speedup.
How This Connects to Broader Ideas
There's something philosophically interesting about the recursion here. Speculative decoding already involves one level of "cheap model guesses what expensive model would say." Speculative speculative decoding adds another layer: the cheap model also guesses what the verification outcome will be and pre-computes the response to that too. You're speculating about speculation.
The paper explicitly draws the connection to speculative execution in CPUs, a decades-old hardware trick where processors pre-execute both branches of a conditional to avoid pipeline stalls. The same idea that made CPUs dramatically faster in the 1990s is now being applied to LLM inference in 2026.
The approach also fits into a broader trend of disaggregating the inference pipeline. Just as prefill and decode are increasingly run on separate hardware (prefill is compute-bound; decode is memory-bandwidth-bound), SSD separates drafting and verification onto different GPUs so they can run simultaneously without fighting over the same resources.
What's Left to Figure Out
The paper is upfront about limitations and open directions.
The biggest one: SSD is great for latency-bound workloads (batch size 1, interactive applications) but less helpful for throughput-bound ones (large-scale offline generation, RL training). When you're already compute-bound, adding more parallel speculation overhead doesn't help much, though the paper shows SSD still improves the Pareto frontier even at larger batch sizes.
There's also a natural question of how SSD composes with tree-based speculative decoding methods like EAGLE. These methods have the draft propose a tree of possible continuations rather than a linear sequence, increasing the chance the target accepts more tokens. Combining tree speculation with parallel verification prediction is theoretically possible but opens up a large, mostly unexplored design space.
Finally, the paper notes an interesting cluster-level idea: sharing a speculation "endpoint" (the draft model) across multiple target model deployments , similar to how prefill servers are shared in some production systems today. If many instances of the same target model are serving traffic, they could share a draft model that pre-speculates for all of them.
The Takeaway
Speculative speculative decoding is one of those ideas that feels obvious in retrospect, but required the right framing to see clearly. The sequential dependence between drafting and verification was hiding in plain sight inside speculative decoding, and this paper cracks it open.
The practical upside is significant: nearly 5x faster inference for large models, with no changes to model weights or outputs, using hardware that's becoming cheaper. The algorithmic insights (geometric fan-out for cache allocation, the sampling trick to control the residual distribution, adaptive fallback by batch size) are each independently elegant and well-motivated.
For anyone building or deploying inference infrastructure, this is worth paying close attention to. The code is open-sourced at github.com/tanishqkumar/ssd, and the framework is designed to compose with existing improvements like EAGLE and tree-based drafting.
The game of squeezing more speed out of LLM inference is far from over.
Paper: Speculative Speculative Decoding - Kumar, Dao, May (2026)


