Skipping the "Thinking": How Simple Prompts Can Outperform Complex Reasoning in AI

Introduction
In the realm of AI, especially with large language models, the prevailing belief is that complex reasoning tasks require detailed, step-by-step "thinking" processes. These processes often involve generating extensive intermediate steps before arriving at a solution, consuming significant computational resources.
However, the paper titled "Reasoning Models Can Be Effective Without Thinking" challenges this notion. The authors propose a method where the model bypasses the elaborate reasoning steps, yet still delivers accurate results. This blog delves into their findings and explores the implications of this approach.
The Problem with Traditional "Thinking" in AI
Traditional LLM reasoning uses chain of thought (CoT) prompting—a sequence of intermediate steps leading to the final answer. This enhances transparency and interpretability but increases token usage and latency. In scenarios with limited computational resources or time constraints, this can be a significant drawback.
Introducing "NoThinking": A Simpler Approach
The authors introduce the NoThinking prompting strategy, omitting explicit reasoning steps. See the research paper here: Reasoning Models Can Be Effective Without Thinking.
Instead of guiding the model through a detailed thought process, the prompt directly leads it to generate the final answer.
| Traditional (CoT) Prompt | "NoThinking" Prompt |
|---|---|
| "Let's think step by step. First, calculate X, then use it to find Y, and finally Z." | "Provide the final answer directly." |
The researchers demonstrate that the model doesn't necessarily require explicit step-by-step reasoning to internally arrive at accurate solutions. In other words, "thinking" still occurs implicitly within the model’s internal processes—even without detailed externalization of these intermediate steps.
This surprising finding challenges a widely held belief in the AI research community—that explicit reasoning steps are necessary for models to achieve high accuracy on complex tasks.
How Does "NoThinking" Work?
The intuition behind "NoThinking" is quite elegant:
- Less Complexity: By explicitly instructing the model to avoid generating intermediate reasoning steps, the model naturally skips internal thought generation.
- Direct Output: The model focuses entirely on reaching the end result, leveraging internal reasoning implicitly without verbose explanations.
- Reduced Token Usage: With fewer intermediate steps, significantly fewer tokens are required, speeding up responses and cutting computational costs.
Practical Example of "NoThinking”
Consider solving a simple math problem like:
"A coffee shop sells muffins at $2 each. If John buys 7 muffins, how much does he pay?"
- Traditional CoT Prompt:"Let’s think step by step. Each muffin costs $2, and John buys 7 muffins. Multiplying these, 7 × 2 equals 14. Thus, John pays $14."
- "NoThinking" Prompt:"Provide the final answer directly."
The model directly outputs: "$14".
This direct approach maintains accuracy while reducing unnecessary verbosity.
Key Findings
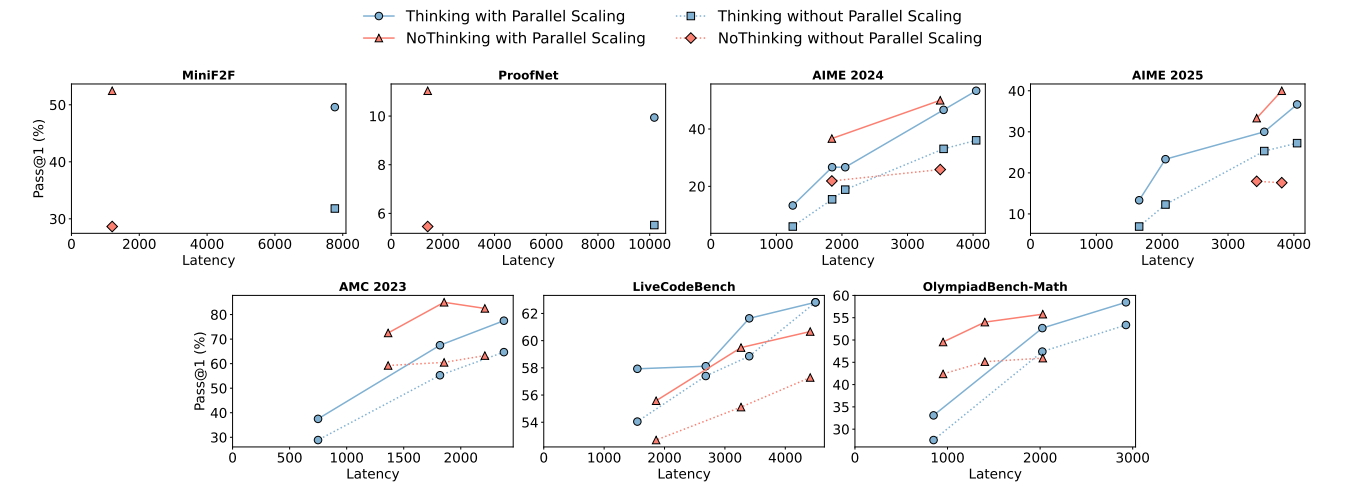
Through extensive evaluation on seven diverse benchmarks including AMC 2023, AIME 2024/25, OlympiadBench (math subset), LiveCodeBench (coding), and Lean theorem proving, NoThinking delivers substantial and measurable gains:
- Token Efficiency (2.0–5.1× fewer tokens)By bypassing explicit CoT traces, NoThinking reduces token usage by 2.0–5.1× across budgets from 400 to 3 500 tokens, shrinking the “thinking” overhead to just a dummy 8-token block.
- Accuracy Uplift in Low-Budget RegimesUnder a 700-token cap on AMC 2023, NoThinking achieves 51.3 % pass@1 versus 28.9 % for standard CoT—a 22.4-point absolute improvement. Comparable gains are seen on AIME 2024/25 (e.g., a jump from ~35 % to ~48 % pass@1) and on OlympiadBench, where NoThinking matches or exceeds CoT at k = 1 and rapidly pulls ahead as k increases.
- Scalable Speed–Quality Trade-offEmploying best-of-16 parallel sampling with task-specific verification (or confidence-based selection), NoThinking:
- Cuts latency by up to 9× on OlympiadBench and 7× on formal theorem proving tasks,
- Uses 4× fewer tokens than sequential CoT,
- And still matches or surpasses CoT’s pass@k accuracy across k = 1…64.
Together, these results demonstrate that a simple dummy-thinking prompt unlocks dramatic efficiency and performance improvements—especially in low-budget or low-latency settings—without any additional model training.
Real-World Implications
The NoThinking approach holds significant promise for various applications:
- Resource-Constrained Environments: Devices with limited computational power can benefit from efficient reasoning without sacrificing accuracy.
- Real-Time Applications: Scenarios requiring quick responses, such as chatbots or real-time translation, can leverage NoThinking for faster outputs.
- Cost Reduction: By reducing token usage, organizations can lower operational costs associated with AI deployments.
Final Thoughts
The study challenges the conventional wisdom that explicit reasoning steps are essential for accurate LLM performance.
By rigorously evaluating NoThinking on seven benchmarks, from AMC 2023 math problems (51.3 % vs 28.9 % pass@1 under a 700-token cap) to Lean theorem proofs and LiveCodeBench coding tasks.
The authors show that a simple 8-token dummy prompt can slash token usage by 2–5×, cut inference latency by up to 9× (with best-of-16 parallel sampling), and still match or exceed traditional chain-of-thought accuracy, proving that explicit “thinking aloud” is not only unnecessary but often counterproductive for efficient, high-quality AI performance.
As AI continues to evolve, approaches like NoThinking highlight the importance of re-evaluating our assumptions and exploring innovative methods to enhance performance.
Further Reading
- Original Paper: Reasoning Models Can Be Effective Without Thinking
- Related Research: Using Attention Sinks to Identify and Evaluate Dormant Heads in Pretrained LLMs