RAGEval: Scenario-specific RAG evaluation dataset generation framework
Introduction
Evaluating Retrieval-Augmented Generation (RAG) systems in specialized domains like finance, healthcare, and legal presents unique challenges that existing benchmarks, focused on general question-answering, fail to address. In this blog, we will explore the research paper "RAGEval: Scenario Specific RAG Evaluation Dataset Generation Framework," which introduces RAGEval. RAGEval offers a solution that automatically generates domain-specific evaluation datasets, reducing manual effort and privacy concerns. By focusing on creating scenario-specific datasets, RAGEval provides a more accurate and reliable assessment of RAG systems in complex, data-sensitive fields.
Limitations of existing benchmarks for RAG
Focus on general domains: Existing RAG benchmarks primarily evaluate factual correctness in general question-answering tasks, which may not accurately reflect the performance of RAG systems in specialized or vertical domains like finance, healthcare, and legal.
Manual data curation: One limitation is that evaluating or benchmarking RAG systems requires manually curating a dataset with input queries and expected outputs (golden answers). This necessity arises because domain-specific benchmarks are not publicly available due to concerns over safety and data privacy.
Data leakage: Challenges in evaluating RAG systems include data leakage from traditional benchmarks such as HotpotQA, TriviaQA, MS Marco, Natural Questions, 2WikiMultiHopQA, and KILT. Data leakage occurs when information from the answers inadvertently appears in the training data, allowing systems to achieve inflated performance metrics by memorizing rather than genuinely understanding and retrieving information.
What is RAGEval?
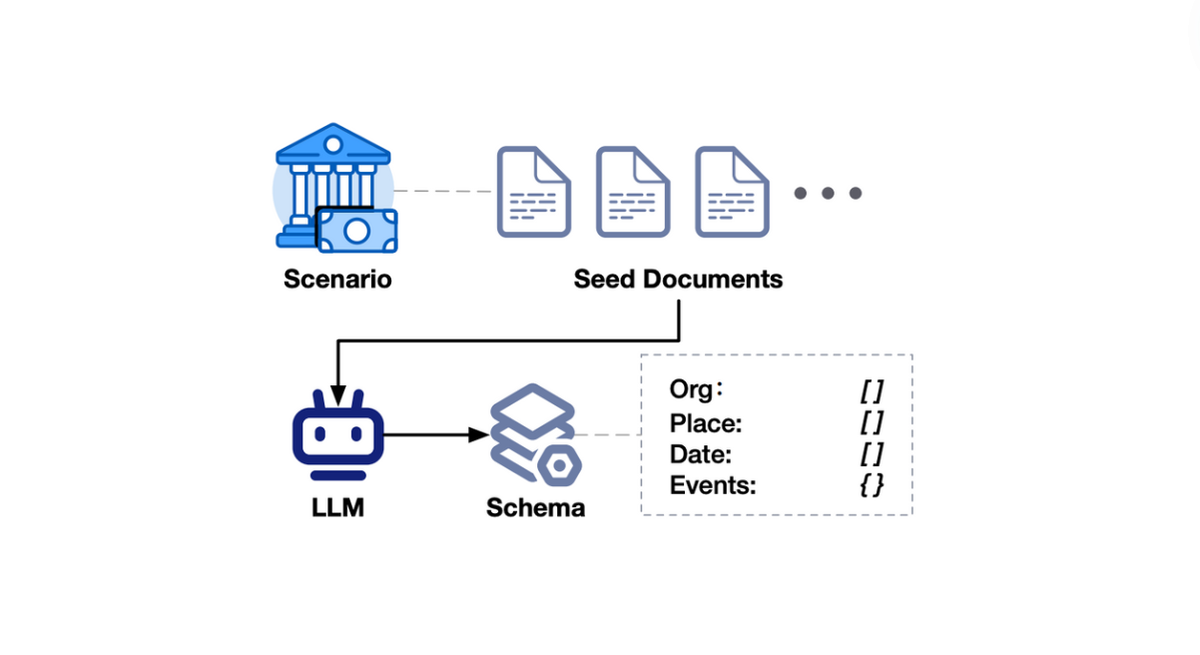
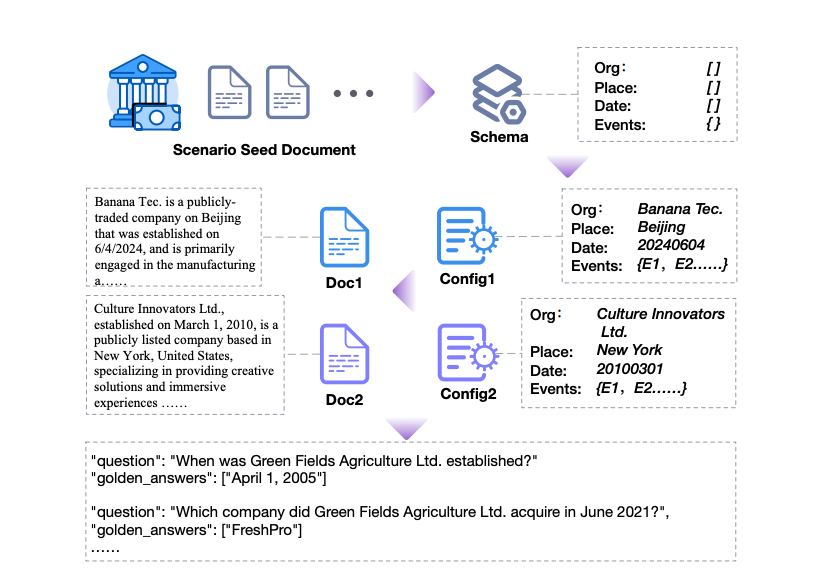
RAGEval is a framework that automatically creates evaluation datasets for assessing RAG systems. It generates a schema from seed documents, applies it to create diverse documents, and constructs question-answering pairs based on these documents and configurations.
Challenges addressed by RAGEval
- RAGEval automates dataset creation by summarizing schemas and generating varied documents, reducing manual effort.
- By using data derived from seed documents and specific schemas, RAGEval ensures consistent evaluation and minimizes biases and privacy concerns.
- Additionally, RAGEval tackles the issue of general domain focus by creating specialized datasets for vertical domains like finance, healthcare, and legal, which are often overlooked in existing benchmarks.
Components of RAGEval
Building a close-domain RAG evaluation dataset presents two major challenges: the high cost of collecting and annotating sensitive vertical documents and the complexity of evaluating detailed, comprehensive answers typical in vertical domains. To tackle these issues, RAGEval uses a “schema-configuration-document-QAR-keypoint” pipeline. This approach emphasizes factual information and improves answer estimation accuracy and reliability. The following sub-sections will detail each component of this pipeline.
Stage 1: Schema summary
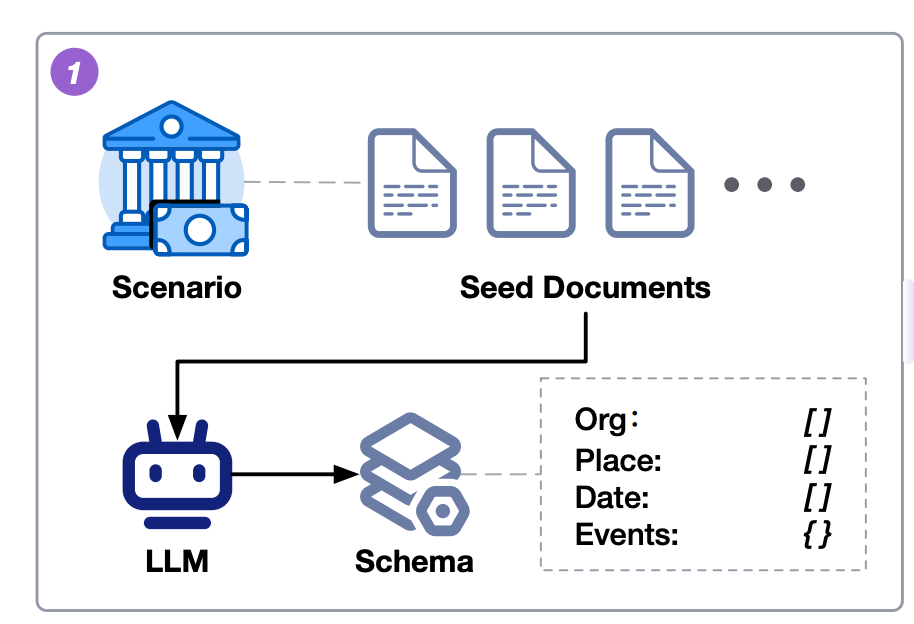
In domain-specific scenarios, texts follow a common knowledge framework, represented by schema S, which captures the essential factual information such as organization, type, events, date, and place. This schema is derived by using LLMs to analyze a small set of seed texts, even if they differ in style and content. For example, financial reports can cover various industries. This method ensures the schema's validity and comprehensiveness, improving text generation control and producing coherent, domain-relevant content.
Example
From seed financial reports, such as:
- Report A: "Tech Innovations Inc. in San Francisco released its annual report on March 15, 2023."
- Report B: "Green Energy Ltd. in Austin published its quarterly report on June 30, 2022."
The schema captures essential elements like:
- Company name
- Report type (annual, quarterly)
- Key events
- Dates
- Location
Using this schema, new content can be generated, such as:
- "Global Tech Solutions in New York announced its quarterly earnings on July 20, 2024."
Stage 2: Document generation
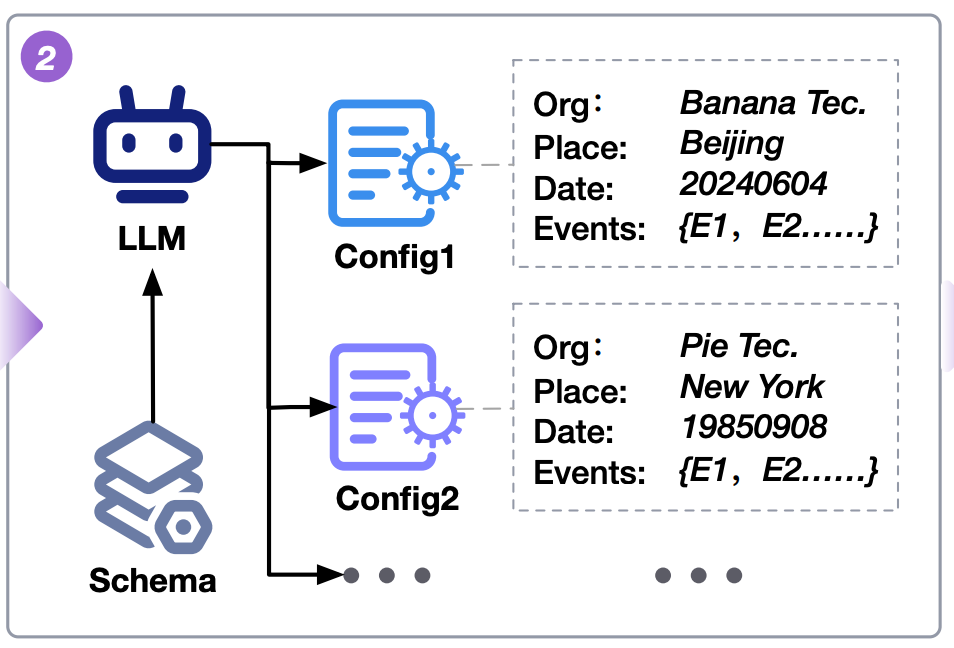
To create effective evaluation datasets, RAGEval first generates configurations derived from a schema, ensuring consistency and coherence in the virtual texts. We use a hybrid approach: rule-based methods for accurate, structured data like dates and categories and LLMs for more complex, nuanced content. For instance, in financial reports, configurations cover various sectors like “agriculture” and “aviation,” with 20 business domains included. The configurations are integrated into structured documents, such as medical records or legal texts, following domain-specific guidelines. For financial documents, we divide content into sections (e.g., “Financial Report,” “Corporate Governance”) to ensure coherent and relevant outputs.
Stage 3: QRA generation
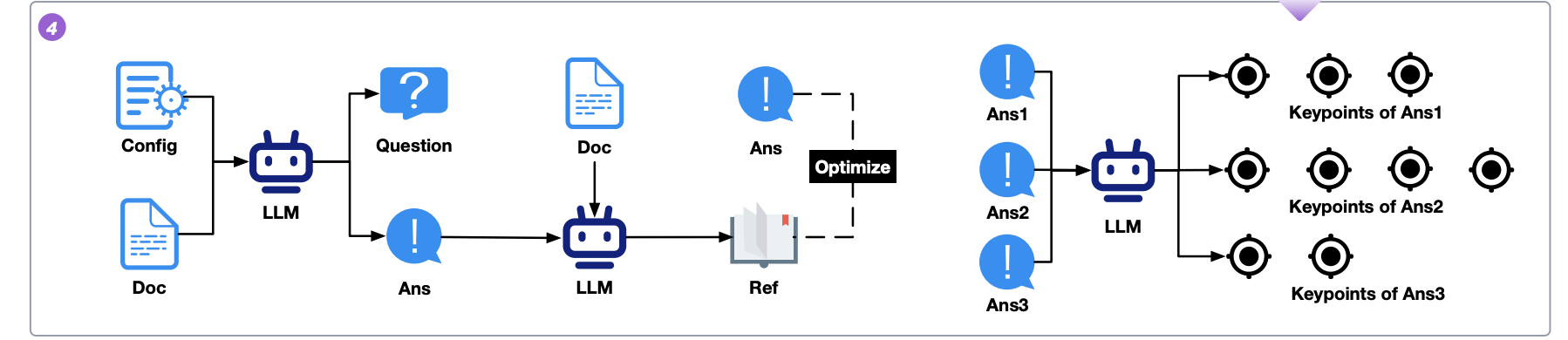
QRA Generation involves creating Question-Reference-Answer (QRA) triples from given documents ( D ) and configurations ( C ). This process is designed to establish a comprehensive evaluation framework for testing information retrieval and reasoning capabilities. It includes four key steps: first, formulating questions ( Q ) based on the documents; second, extracting relevant information fragments ( R ) from the documents to support the answers; third, generating initial answers ( A ) to the questions using the extracted references; and fourth, optimizing the answers and references to ensure accuracy and alignment, addressing any discrepancies or irrelevant content.
Utilizing configurations for questions and initial answers generation involves using specific configurations (C) to guide the creation of questions and initial answers. These configurations are embedded in prompts to ensure that generated questions are precise and relevant, and the answers are accurate. The configurations help generate a diverse set of question types, including factual, multi-hop reasoning, summarization, etc. The GPT-4o model produces targeted and accurate questions (Q) and answers (A) by including detailed instructions and examples for each question type. The approach aims to evaluate different facets of language understanding and information processing.

Extracting references, given the constructed questions ( Q ) and initial answers ( A ), the process involves extracting pertinent information fragments (references) ( R ) from the articles using a tailored extracting prompt. This prompt emphasizes the importance of grounding answers in the source material to ensure their reliability and traceability. Applying specific constraints and rules during the extraction phase ensures that the references are directly relevant and supportive of the answers, resulting in more precise and comprehensive QRA triples.
Optimizing answers and references involves refining answer A to ensure accuracy and alignment with the provided references R. If R contains information not present in A, the answers are supplemented accordingly. Conversely, if A includes content not found in R, the article is checked for overlooked references. If additional references are found, they are added to R while keeping A unchanged. If no corresponding references are found, irrelevant content is removed from A. This approach helps address hallucinations in the answer-generation process, ensuring that the final answers are accurate and well-supported by R.
Generating key points focuses on identifying critical information in answers rather than just correctness or keyword matching. Key points are extracted from standard answers ( A ) for each question ( Q ) using a predefined prompt with the GPT-4o model. This prompt, supporting both Chinese and English, uses in-context learning and examples to guide key point extraction across various domains and question types, including unanswerable ones. Typically, 3-5 key points are distilled from responses, capturing essential facts, relevant inferences, and conclusions. This method ensures that the evaluation is based on relevant and precise information, enhancing the reliability of subsequent metrics.
Quality assessment of RAGEval
In this section, the authors of the paper-"RAGEval: Scenario Specific RAG Evaluation Dataset Generation Framework" introduce the human verification process used to assess the quality of the generated dataset and the evaluation within the RAGEval framework. This assessment is divided into three main tasks: evaluating the quality of QARs and generated documents and validating the automated evaluation.
QAR quality assessment involves having annotators evaluate the correctness of the Question-Answer-Reference (QAR) triples generated under various configurations. Annotators score the QARs ranging from completely correct and fluent responses (5) to irrelevant or completely incorrect responses (0).

For annotation, 10 samples per question type were randomly selected for each language and domain, totaling 420 samples. Annotators were provided with the document, question, question type, generated response, and references.
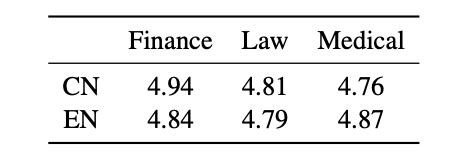
Results show that QAR quality scores are consistently high across different domains, with only slight variations between languages. The combined proportion of scores 4 and 5 is approximately 95% or higher across all domains, indicating that the approach upholds a high standard of accuracy and fluency in QARs.
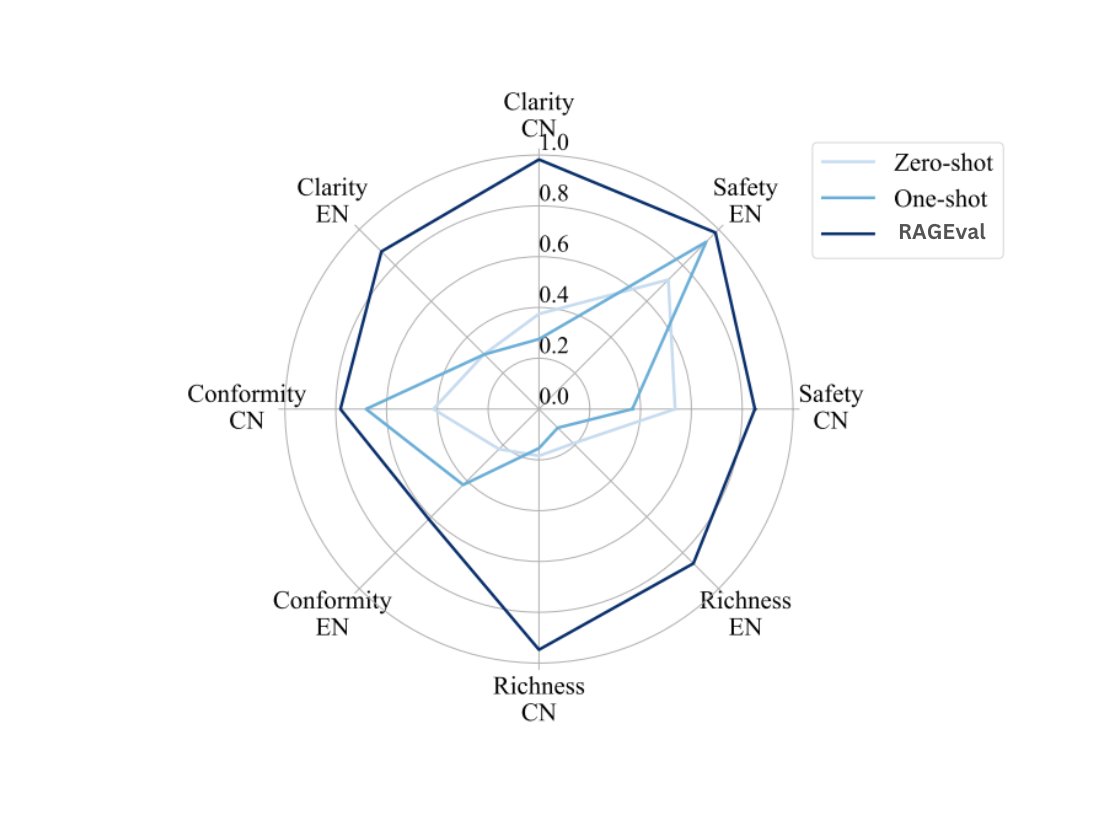
Generated document quality assessment involves comparing documents generated using RAGEval with those produced by baseline methods, including zero-shot and one-shot prompting. For each domain—finance, legal, and medical—20 or 19 documents were randomly selected and grouped with two baseline documents for comparison. Annotators ranked the documents based on clarity, safety, richness, and conformity.

Results indicate that RAGEval consistently outperforms both baseline methods, particularly excelling in safety, clarity, and richness. For Chinese and English datasets, RAGEval ranked highest in over 85% of cases for richness, clarity, and safety, demonstrating its effectiveness in generating high-quality documents.
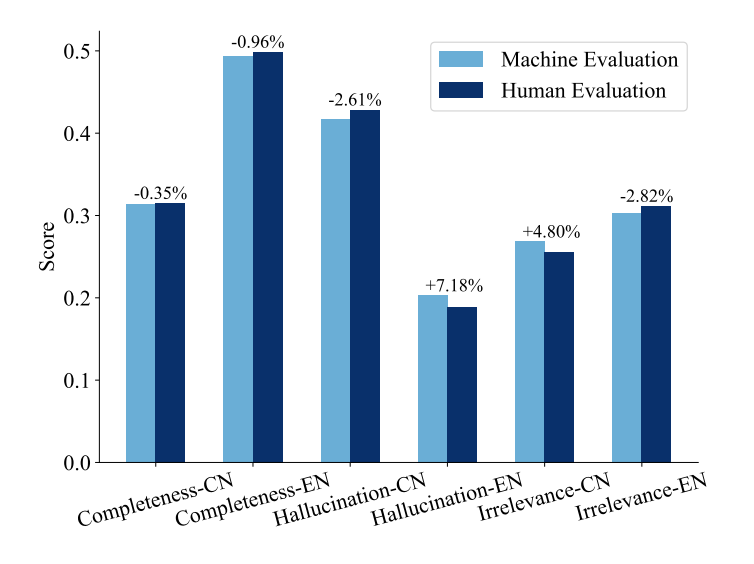
Validation of automated evaluation involves comparing LLM-reported metrics for completeness, hallucination, and irrelevance with human assessments. Using the same 420 examples from the QAR quality assessment, human annotators evaluated answers from Baichuan-2-7B-chat, and these results were compared with LLM metrics. Figure 6 shows that machine and human evaluations align closely, with absolute differences under 0.015, validating the reliability and consistency of the automated evaluation metrics.
Conclusion
In conclusion, RAGEval represents a significant advancement in evaluating Retrieval-Augmented Generation (RAG) systems by automating the creation of scenario-specific datasets that emphasize factual accuracy and domain relevance. This framework addresses the limitations of existing benchmarks, particularly in sectors requiring detailed and accurate information such as finance, healthcare, and legal fields. The human evaluation results demonstrate the robustness and effectiveness of RAGEval in generating content that is accurate, safe, and rich. Furthermore, the alignment between automated metrics and human judgment validates the reliability of the evaluation approach.
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your RAG performance with Maxim.