RAGChecker
Introduction
In this blog, we explore the RAGChecker framework for its effectiveness in evaluating Retrieval-Augmented Generation (RAG) systems. RAGChecker addresses significant challenges in RAG evaluation, including the modular complexity of RAG systems, the assessment of long-form responses, and the reliability of measurements. Meta-evaluation has shown that RAGChecker aligns more closely with human judgments compared to existing metrics.
Challenges in evaluating RAG systems
- Metric reliability: The reliability of current RAG metrics is still unclear. To be effective, evaluation metrics must accurately reflect system performance and align with human judgments to be practical in real-world use.
- Metric limitations: Existing metrics, such as recall@k and BLEU, precision@k, etc, are often coarse-grained and fail to capture the full semantic scope of the knowledge base or the nuanced quality of generated responses.
- Modular complexity: The dual nature of RAG systems, with separate retriever and generator components, complicates the design of holistic evaluation metrics that can assess the entire system and its individual parts.
What challenges are solved by RAGChecker?
RAGChecker solves key challenges in evaluating RAG systems by providing:
- Fine-grained evaluation: It offers detailed, claim-level analysis instead of broad, response-level assessments.
- Comprehensive metrics: RAGChecker covers overall system performance, retriever effectiveness, and generator accuracy, offering a complete view of the system.
- Human alignment: RAGChecker's metrics are validated against human judgments, ensuring accurate and practical evaluations.
How RAGChecker works?
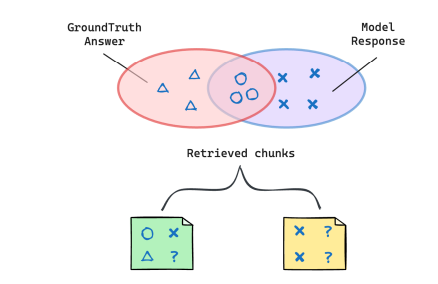
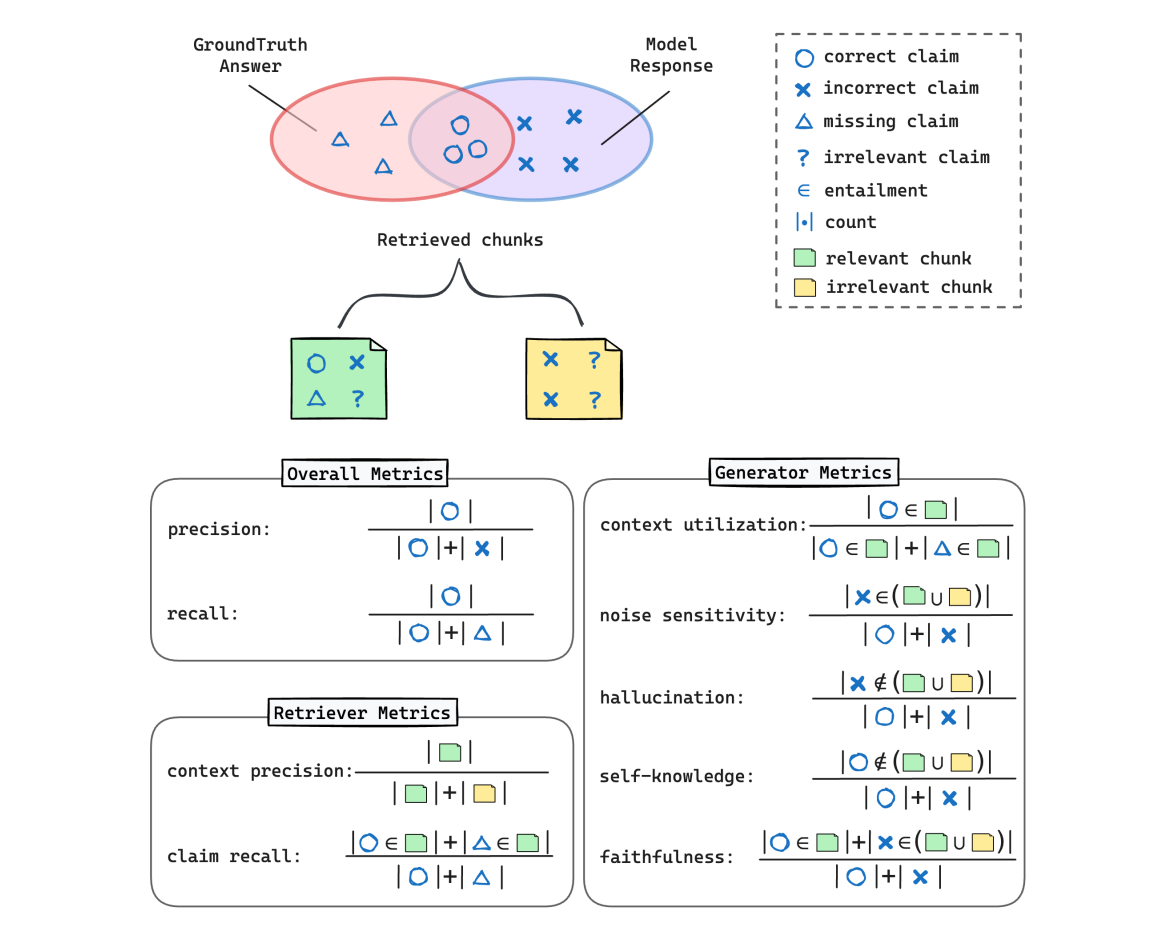
RAGChecker starts by preparing a benchmark dataset in the format of a tuple ⟨q, D, gt⟩ representing a query, documents, and ground-truth answer. To evaluate responses, RAGChecker decomposes response answers "T" into a set of claims {ci} and checks whether each claim c is entailed (∈) in a reference text or not, allowing for fine-grained analysis. It offers overall metrics, like a single F1 score for general users, and detailed modular metrics for developers to diagnose errors in the system's retriever and generator components.
Overall metrics
To evaluate the overall quality of an RAG system's responses from a user’s perspective, precision and recall are computed at the claim level by comparing each model-generated response with its corresponding ground-truth answer. First, claims are extracted from the model response "m" and the ground-truth answer "gt" as sets c_{m} and c_{gt}, respectively. Precision is calculated as the proportion of correct claims in all response claims, and recall is the proportion of correct claims in all ground-truth answer claims. Further, the harmonic average of precision and recall gives the F1 score as the overall performance metric.
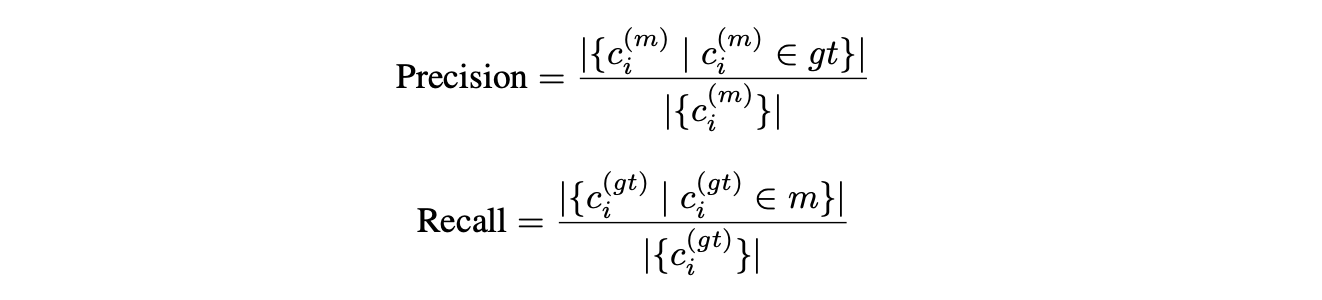
Retriever metrics
Ideally, a perfect retriever would return exactly the claims needed to generate the ground-truth answer. To assess completeness, one can measure how many claims from the ground-truth answer are covered by the retrieved chunks. Using the retrieved chunks as the reference text, claim recall is calculated as the proportion of ground-truth claims present within those chunks.
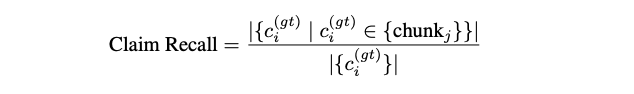
Retriever precision, however, is defined at the chunk level rather than the claim level. A retrieved chunk is considered a relevant chunk (r-chunk) if it contains any ground-truth claim. In other words, a chunk is deemed relevant if at least one ground-truth claim is found within it. The remaining retrieved chunks are classified as irrelevant chunks (irr-chunks). The retriever’s context precision is then defined as the ratio of relevant chunks to the total number of retrieved chunks.
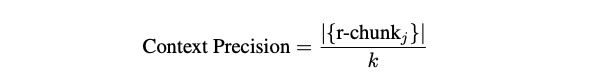
Chunk-level precision offers better interpretability than claim-level precision, as RAG systems typically operate with documents divided into fixed-size text chunks.
Generator metrics
For a given set of "k" retrieved chunks, a perfect generator would correctly identify and include all relevant claims from the ground-truth answer while disregarding irrelevant ones. Since the generator's output relies on these retrieved chunks, six key metrics are used to evaluate its performance based on a model response "m" and its claims {c_m}:
- Faithfulness: This measures how closely the generator’s claims align with the retrieved chunks. Higher faithfulness indicates that the generator is more accurate in using the provided context.
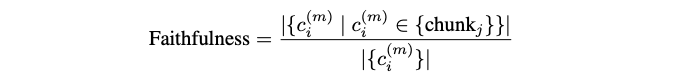
- Relevant noise sensitivity: This refers to the proportion of incorrect claims that come from relevant chunks, indicating the generator’s susceptibility to noise mixed with useful information.
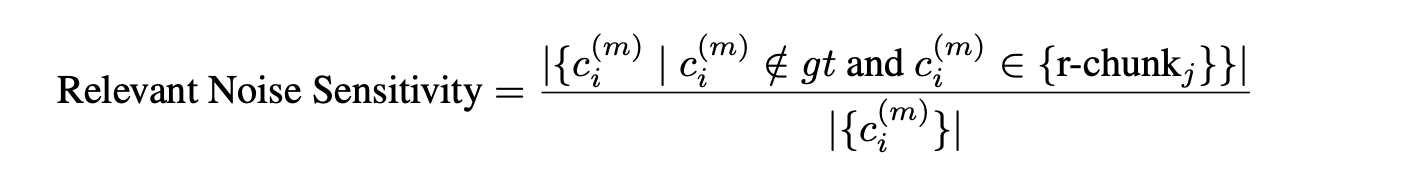
- Irrelevant noise sensitivity: This measures the proportion of incorrect claims originating from irrelevant chunks, showing the generator's sensitivity to noise even when the context is not relevant.
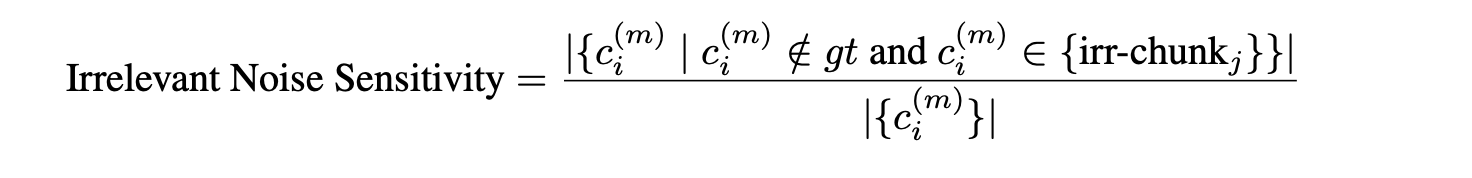
- Hallucination: This metric captures the proportion of incorrect claims that are not supported by any retrieved chunk, meaning they were generated entirely by the model without context.
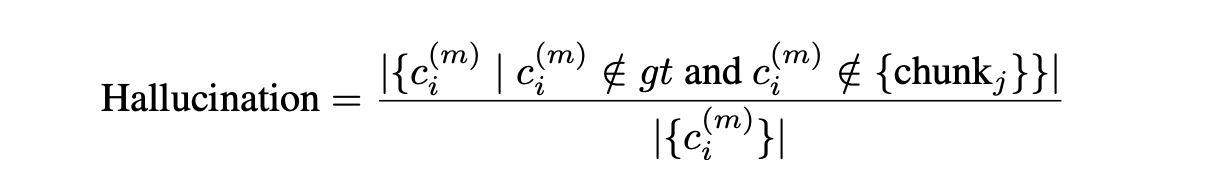
- Self-knowledge: This evaluates the proportion of correct claims generated by the model independently, without relying on the retrieved context. A lower self-knowledge score is preferred when the generator should fully depend on the retrieved context.
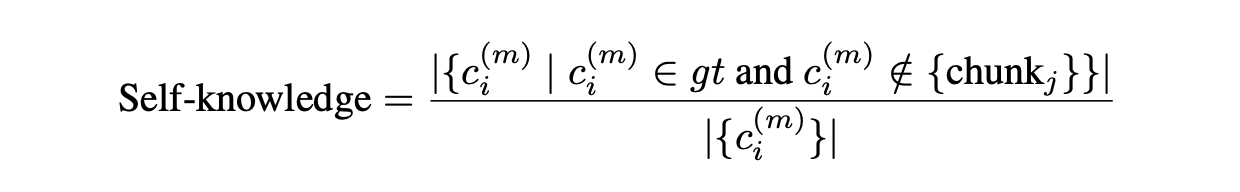
- Context utilization: This measures how effectively the generator uses relevant information from the retrieved chunks to produce correct claims. Higher context utilization is desirable as it indicates better use of the provided context.
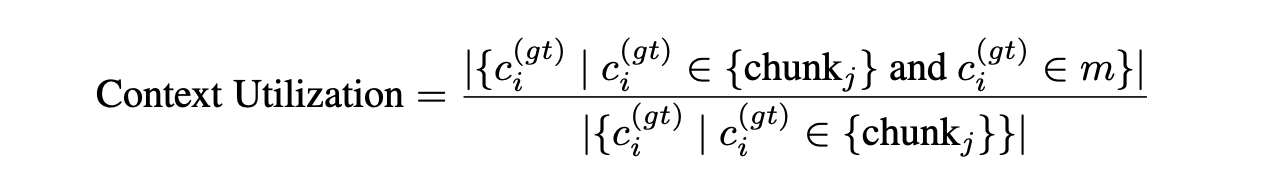

The averaged evaluation results for different RAG systems across 10 datasets (discussed in the later section) are presented, highlighting key performance metrics. Overall system performance is measured using precision (Prec.), recall (Rec.), and F1 scores. The retriever component's effectiveness is assessed through claim recall (CR) and context precision (CP), while the generator's performance is evaluated using context utilization (CU), relevant noise sensitivity (NS(I)), irrelevant noise sensitivity (NS(II)), hallucination (Hallu.), self-knowledge (SK), and faithfulness (Faith.). The average number of response claims generated by each RAG system is also included.
Human alignment experiment and results
The authors aimed to assess how well RAGChecker correlates with human annotations compared to other evaluation frameworks. To achieve this, they conducted a meta-evaluation to validate RAGChecker's effectiveness and compare its performance with existing baseline RAG evaluation frameworks.
Baseline RAG systems: Eight customized RAG systems are used, combining two retrievers (BM25 and E5-Mistral) with four generators (GPT-4, Mixtral8x7B, Llama3-8B, and Llama3-70B) for meta-data generation and evaluation.
Baseline RAG evaluation frameworks: The meta-evaluation includes 10 metrics from Trulens, RAGAS, ARES, and CRUD-RAG, chosen for their ability to evaluate end-to-end performance with long answers. For a fair comparison, the Llama3-70B-Instruct LLM backbone is used when applicable. Since the Llama3 family does not provide an embedding model, metrics requiring embedding capabilities utilize the default LLM backbones. Additionally, BLEU, ROUGE-L, and BERTScore are included to assess the alignment between generated responses and ground-truth answers.
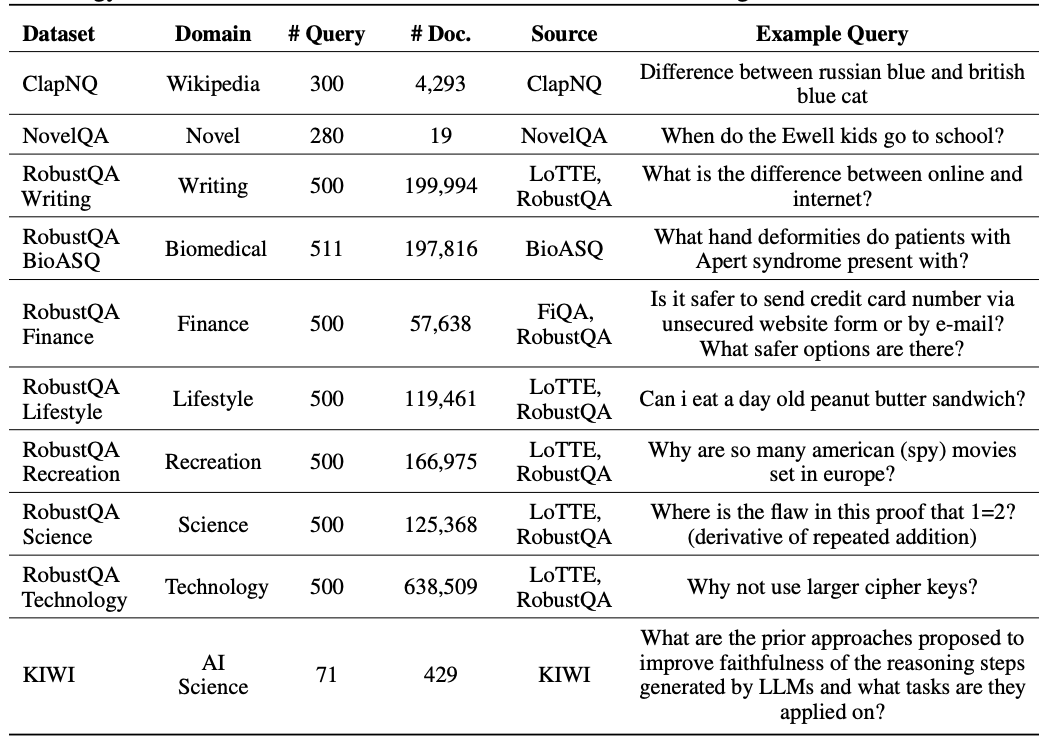
Meta-evaluation dataset: The meta-evaluation dataset comprises 280 response pairs generated by eight different RAG systems spanning 10 domains.
Each meta-evaluation instance is a pair of responses from two baseline RAG systems given the same query. It is designed to compare how well different metrics reflect human preferences across various RAG systems. Human annotators assess these pairs, and each pair is evaluated by two annotators to ensure reliability, with their agreement and correlation carefully measured. This dataset aims to identify which metrics most accurately align with human judgments, thereby improving the evaluation of RAG systems in real-world scenarios.
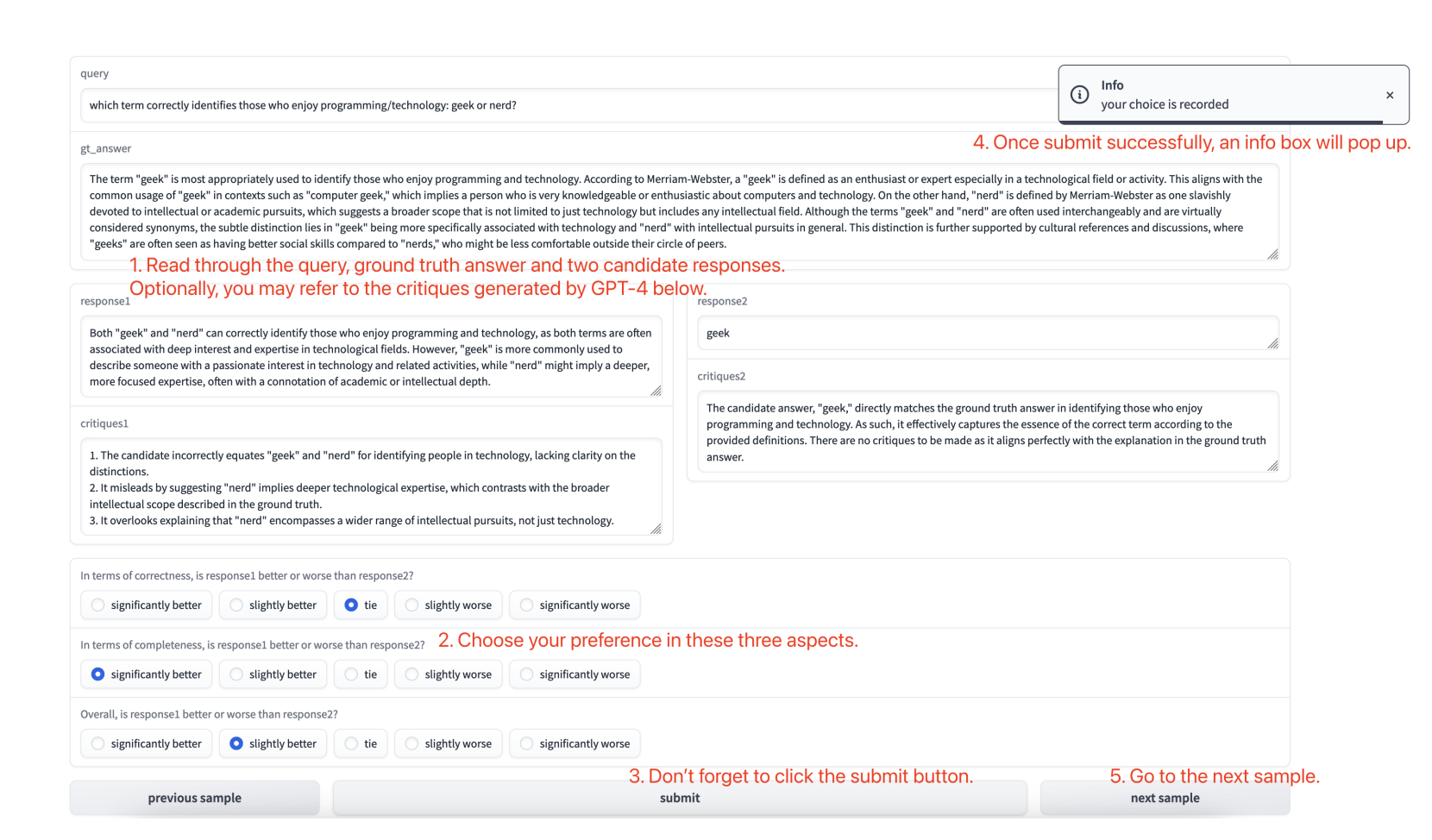
Meta-evaluation: In the meta-evaluation process, human annotators evaluate pairs of responses by assigning preference scores ranging from -2 to 2 for factors such as correctness, completeness, and overall assessment. The baseline RAG evaluation model calculates a score for each response pair, which is then normalized to fall within the same range [-2,2]. Then, the Pearson and Spearman correlation between the model’s normalized scores and human preference scores is analyzed across 280 instances to determine how well the model reflects human judgments.
Results:
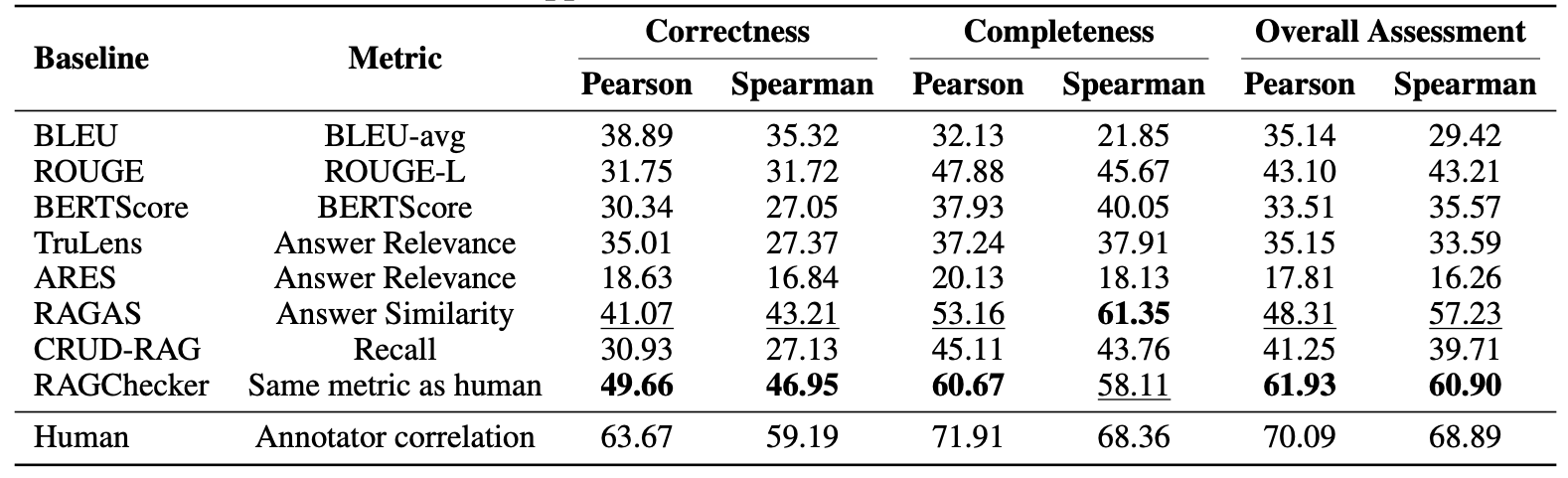
The meta-evaluation revealed that RAGChecker demonstrated the strongest correlation with human preferences across all three evaluated aspects. The correlation between the preferences of two annotators used as an upper-bound reference confirmed that RAGChecker aligns more closely with human judgments than other frameworks.
Conclusion
RAGChecker, a novel evaluation framework, addresses key challenges such as modular complexity, long-form response assessment, and metric reliability. It provides a comprehensive suite of metrics—both overall and modular. The meta-evaluation confirms that RAGChecker outperforms existing metrics in reflecting human preferences for correctness, completeness, and overall quality. Through rigorous human assessments, RAGChecker demonstrates a strong correlation with evaluations conducted by human annotators, making it a valuable tool for enhancing RAG systems and guiding their development.
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your RAG performance with Maxim.