The role of retrieval in improving RAG performance

Introduction
In part one of the "Understanding RAG" series, we covered the basics and advanced concepts of Retrieval-Augmented Generation (RAG). This part delves deeper into the retrieval component and explores enhancement strategies.
In this blog, we will explore techniques to improve retrieval and make pre-retrieval processes, such as document chunking, more efficient. Effective retrieval requires accurate, clear, and detailed queries. Even with embeddings, semantic differences between queries and documents can persist. Several methods enhance query information to improve retrieval. For instance, Query2Doc and HyDE generate pseudo-documents from original queries, while TOC decomposes queries into subqueries, aggregating the results. Document chunking significantly influences retrieval performance. Common strategies involve dividing documents into chunks, but finding the optimal chunk length is challenging. Small chunks may fragment sentences, while large chunks can include irrelevant context.
What is document chunking?
Chunking is the process of dividing a document into smaller, manageable segments or chunks. The choice of chunking techniques is crucial for the effectiveness of this process. In this section, we will explore various chunking techniques mentioned in the research paper and look at their findings to determine the most effective method.

Levels of chunking
- Token-level chunking: Token-level chunking involves splitting the text at the token level. This method is simple to implement but has the drawback of potentially splitting sentences inappropriately, which can affect retrieval quality.
- Semantic-level chunking: Semantic-level chunking involves using LLMs to determine logical breakpoints based on context. This method preserves the context and meaning of the text but is time-consuming to implement.
- Sentence-level chunking: Sentence-level chunking involves splitting the text at sentence boundaries. This method balances simplicity and the preservation of text semantics. However, it is potentially less precise than semantic-level chunking, though this drawback is not explicitly mentioned.
Chunk size and its impact
- Larger chunks:
- Pros: Provide more context, enhancing comprehension.
- Cons: Increase processing time.
- Smaller chunks:
- Pros: Improve retrieval recall and reduce processing time.
- Cons: It may lack sufficient context.
Finding the optimal chunk size involves balancing metrics such as faithfulness and relevancy.
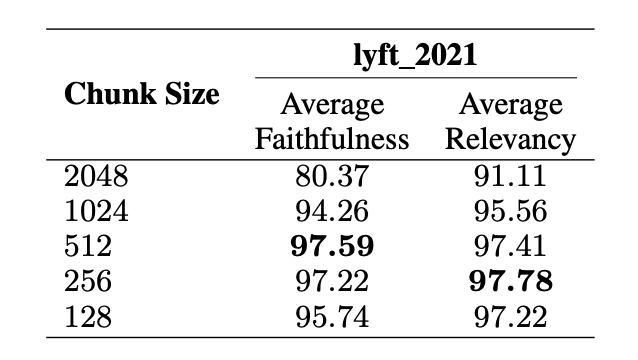
In an experiment detailed in the research paper, the text-embedding-ada-0022 model was used for embedding. The zephyr-7b-alpha3 model served as the generation model, while GPT-3.5-turbo was utilized for evaluation. A chunk overlap of 20 tokens was maintained throughout the process. The corpus for this experiment comprised the first sixty pages of the document lyft_2021.
Larger chunks (2048 tokens): Offer more context but at the cost of slightly lower faithfulness. Smaller chunks (128 tokens): Improve retrieval recall but may lack sufficient context, leading to slightly lower faithfulness.
Advanced chunking techniques
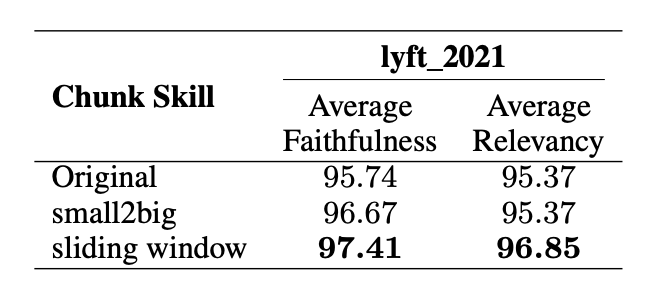
Advanced chunking techniques, such as small-to-big and sliding windows, improve retrieval quality by organizing chunk relationships and maintaining context.
Sliding window chunking: Sliding window chunking segments text into overlapping chunks, combining fixed-size and sentence-based chunking advantages. Each chunk overlaps with the previous one, preserving context and ensuring continuity and meaning in the text.
Small-to-big chunking: Small-to-big chunking involves using smaller, targeted text chunks for embedding and retrieval to enhance accuracy. After retrieval, the larger text chunk containing the smaller chunk is provided to the large language model for synthesis. This approach combines precise retrieval with comprehensive contextual information.
In an experiment detailed in the research paper, the effectiveness of advanced chunking techniques is demonstrated using the LLM-Embedder model for embedding. The study utilizes a smaller chunk size of 175 tokens, a larger chunk size of 512 tokens, and a chunk overlap of 20 tokens. Techniques such as small-to-big and sliding window are employed to enhance retrieval quality by preserving context and ensuring the retrieval of relevant information.
Retrieval methods
1. Query rewriting
Refines user queries to better match relevant documents by prompting an LLM to rewrite queries.
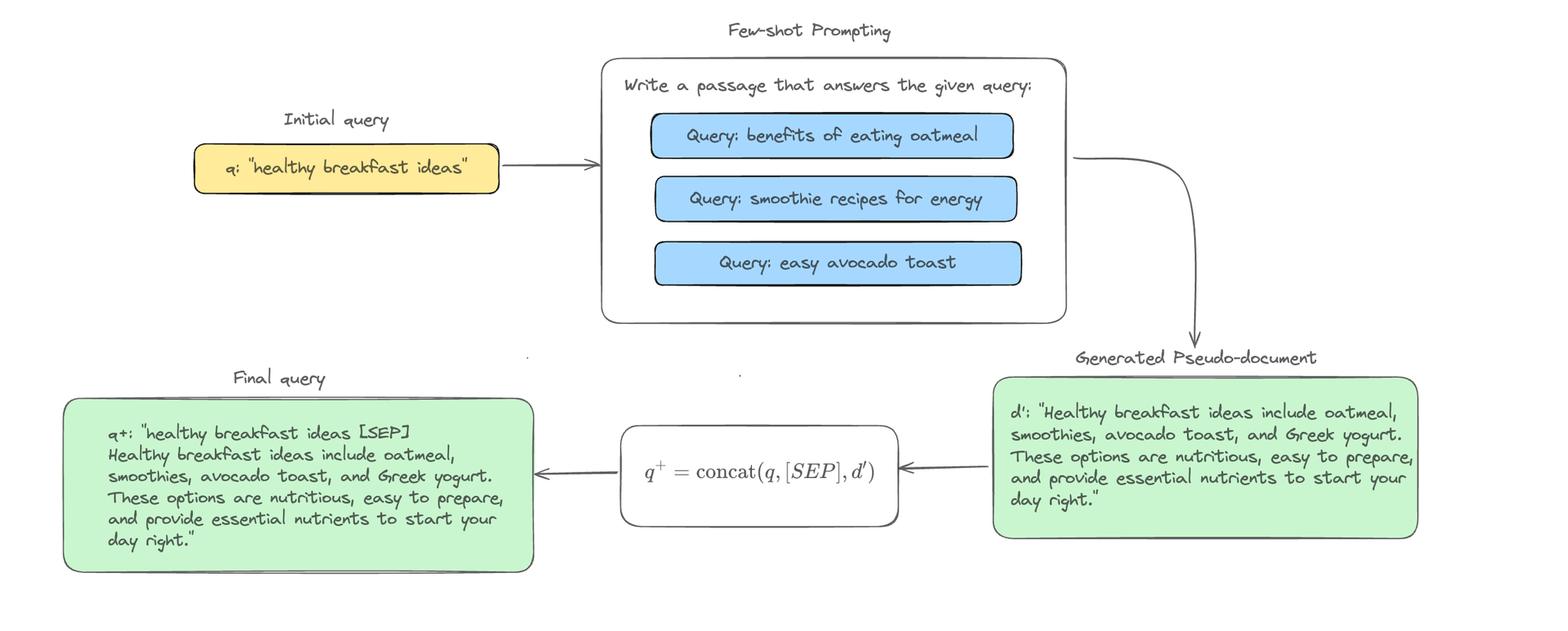
Query2doc: Given a query q, the method generates a pseudo-document d′ through few-shot prompting. The original query q is then concatenated with the pseudo-document d′ to form an enhanced query q+, enhancing the query's context and improving retrieval accuracy. The enhanced query q+ is a straightforward concatenation of q and d′, separated by a special token [SEP].
Performance
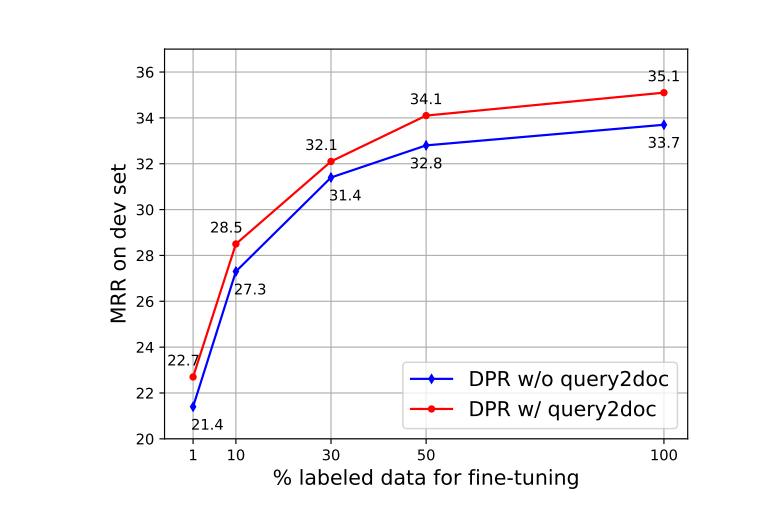
- The “DPR + query2doc” variant consistently outperforms the baseline DPR model by approximately 1% in MRR on the MS-MARCO dev set, regardless of the amount of labeled data used for fine-tuning.
- This indicates that the improvement provided by the query2doc method is not dependent on the quantity of labeled data available for training.
2. Query decomposition
Involves breaking down the original query into sub-questions.This method retrieves documents based on these sub-questions, potentially enhancing retrieval accuracy by addressing different aspects of the original query.
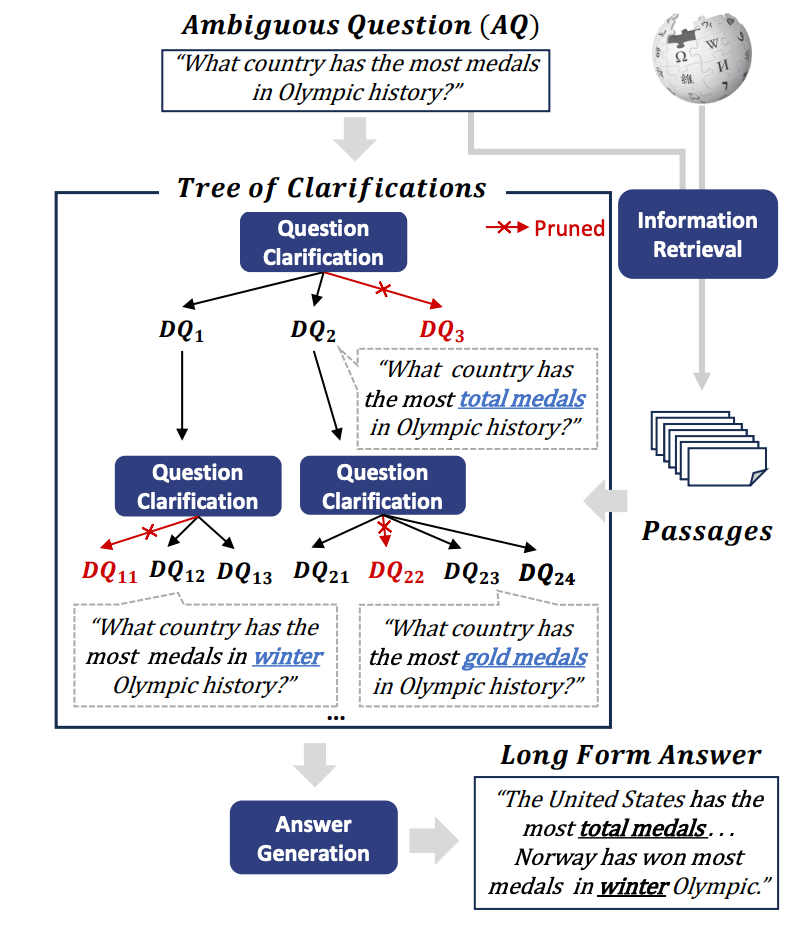
One such framework is TOC (TREE OF CLARIFICATIONS), which addresses ambiguous questions in open-domain QA by generating disambiguated questions (DQs) through few-shot prompting. It retrieves relevant passages to identify various interpretations, like different types of medals or Olympics. TOC prunes redundant DQs and creates a comprehensive long-form answer covering all interpretations, ensuring thoroughness and depth without needing user clarification.
3. Pseudo-documents generation:
Techniques like HyDE (Hypothetical Document Embeddings) improve retrieval by generating hypothetical or pseudo documents with a generative model and encoding them into semantic embeddings using a contrastive encoder. This approach enhances relevance-based retrieval without relying on exact text matches, utilizing unsupervised learning principles effectively.
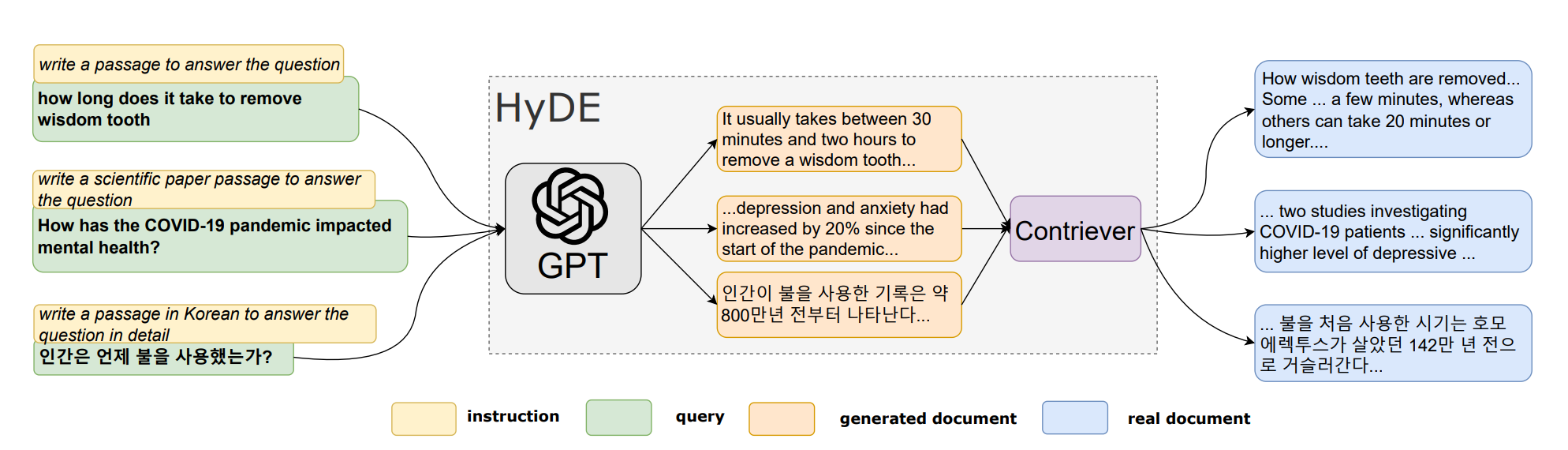
Let's dive deep into HYDE's concept by examining each step it undergoes through an example scenario. At a high level, it performs two tasks: a Generative Task and a Document-Document Similarity Task.
Example query: What are the causes of climate change?
Step 1: Generative model
Purpose: Generate a hypothetical document that answers the query.
Generated Document: "Climate change is caused by human activities like burning fossil fuels, deforestation, and industrial processes. It releases greenhouse gases such as carbon dioxide and methane, trapping heat and causing global warming. Natural factors like volcanic eruptions and solar radiation also contribute."
Step 2: Contrastive encoder
Purpose: Encode the generated document using semantic embedding.
Encoded Vector: A numerical representation in a high-dimensional space that emphasizes semantic content (causal factors of climate change) while filtering out unnecessary details.
Step 3: Retrieval using document-document similarity
Purpose: Compare the encoded vector of the hypothetical document with embeddings of real documents in a corpus.
Process: Compute similarity (e.g., cosine similarity) between the hypothetical document's vector and corpus document vectors.
Retrieval: Retrieve real documents from the corpus that are most semantically similar to the hypothetical document, focusing on relevance rather than exact wording.
Conclusion
Advanced chunking techniques like the sliding window significantly improve retrieval quality by maintaining context and ensuring the extraction of relevant information. Among various retrieval methods evaluated, Hybrid Search with HyDE stands out as the best, combining the speed of sparse retrieval with the accuracy of dense retrieval to achieve superior performance with acceptable latency.
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your RAG performance with Maxim.