Decoding the generation component: How RAG creates coherent text
Introduction
In part one of the "Understanding RAG series," we outlined the three main components of RAG: indexing, retrieval, and generation. In the previous parts, we discussed techniques for improving indexing and retrieval. This blog will focus on methods to enhance the generation component of Retrieval-Augmented Generation (RAG). In this blog, we will also explore techniques like document repacking, summarization, and fine-tuning LLM models for generation, all of which are crucial for refining the information that feeds into the generation process.
Understanding document repacking
Document repacking is a technique used in the RAG workflow to enhance response generation performance. After the reranking stage, where the top K documents are selected based on their relevancy scores, document repacking optimizes the order in which these documents are presented to the LLM model. This rearrangement ensures that the LLM can generate more precise and relevant responses by focusing on the most pertinent information.
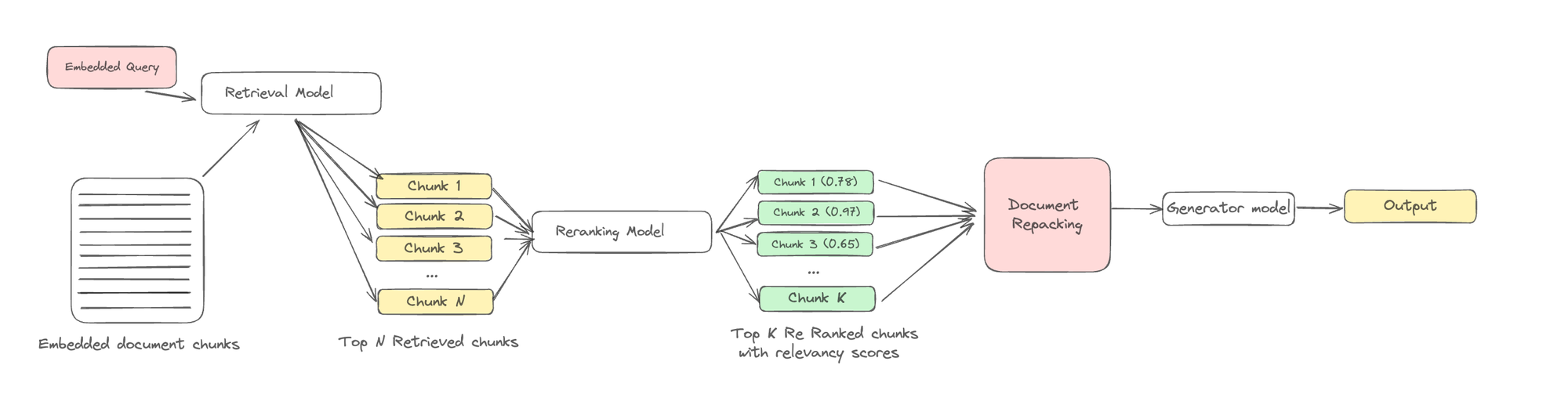
Different repacking methods
There are three primary repacking methods:
- Forward method: In this approach, documents are repacked in descending order based on their relevancy scores. This means that the most relevant documents, as determined in the reranking phase, are placed at the beginning of the input.
- Reverse method: Conversely, the reverse method arranges documents in ascending order of their relevancy scores. Here, the least relevant documents are placed first, and the most relevant ones are at the end.
- Sides method: The sides method strategically places the most relevant documents at both the head and tail of the input sequence, ensuring that critical information is prominently positioned for the LLM.
Selecting the best repacking method
In the research paper-"Searching for Best Practices in RAGeneration," the authors assessed the performance of various repacking techniques to determine the most effective approach, and the "reverse" method emerged as the most effective repacking method.

Understanding document summarization
Summarization in RAG involves condensing retrieved documents to enhance the relevance and efficiency of response generation by removing redundancy and reducing prompt length before sending them to the LLM model for generation. Summarization tasks can be extractive or abstractive. Extractive methods segment documents into sentences, then score and rank them based on importance. Abstractive compressors synthesize information from multiple documents to rephrase and generate a cohesive summary. These tasks can be either query-based, focusing on information relevant to a specific query, or non-query-based, focusing on general information compression.
Purpose of summarization in RAG
- Reduce redundancy: Retrieved documents can contain repetitive or irrelevant details. Summarization helps filter out this unnecessary information.
- Enhance efficiency: Long documents or prompts can slow down the language model (LLM) during inference. Summarization helps create more concise inputs, speeding up the response generation.
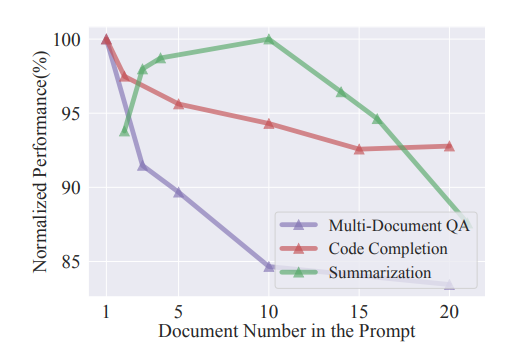
In the above figure it can be clearly seen that the performance of LLMs in downstream tasks decreases as the number of documents in the prompt increases. Therefore, summarization of the retrieved documents is necessary to maintain performance.
Summarization techniques
There are multiple summarization techniques that can be employed in RAG frameworks. Here in this blog, we will discuss two such techniques:
RECOMP: It is a technique that compresses retrieved documents using one of two methods, extractive or abstractive compression, depending on the use case. Extractive is used to maintain exact text, while abstractive synthesizes summaries. The decision is based on task needs, document length, computational resources, and performance. The extractive compressor selects key sentences by using a dual encoder model to rank sentences based on their similarity to the query. The abstractive compressor, on the other hand, generates new summaries with an encoder-decoder model trained on large datasets containing document-summary pairs. These compressed summaries are then added to the original input, providing the language model with a focused and concise context
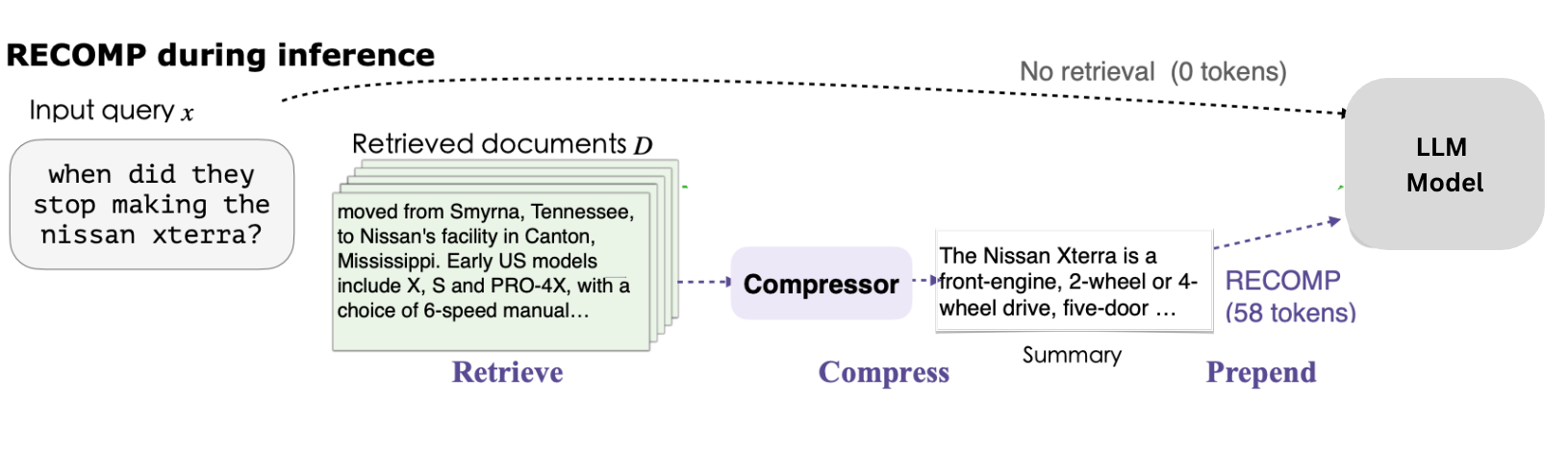
LongLLMLingua: This technique uses a combination of question-aware coarse-grained and fine-grained compression methods to increase key information density and improve the model's performance.
In question-aware coarse-grained compression, perplexity is measured for each retrieved document with respect to the given query. Then, all documents are ranked based on their perplexity scores, from lowest to highest. Documents with lower perplexity are considered more relevant to the question.
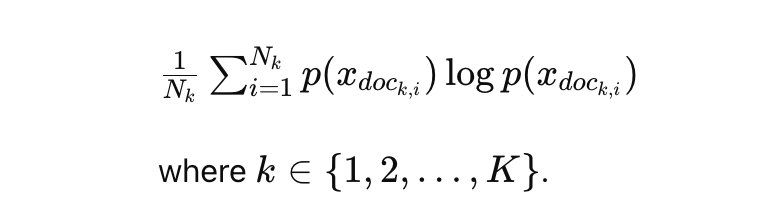
Question-aware fine-grained compression is a method to further refine the documents or passages that were retained after the coarse-grained compression, by focusing on the most relevant parts of those documents. For each word or token within the retained documents, the importance is computed with respect to the given query. Then the tokens are ranked based on their importance scores, from most important to least important.
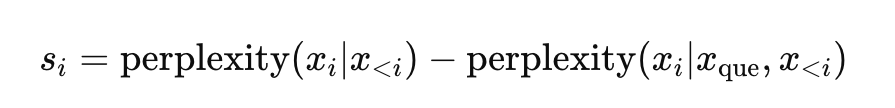
Selecting the best summarization technique
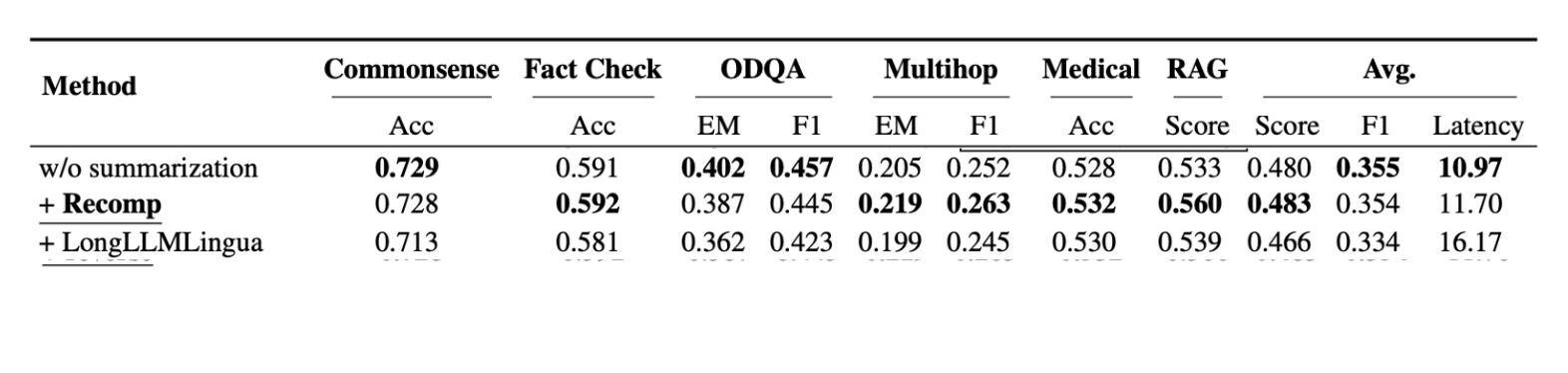
In the research paper "Searching for Best Practices in Retrieval-Augmented Generation," the authors evaluated various summarization methods on three benchmark datasets: NQ, TriviaQA, and HotpotQA. Recomp was recommended for its outstanding performance.
Understanding generator fine-tuning
Fine-tuning is the process of taking a pre-trained model and making further adjustments to its parameters on a smaller, task-specific dataset to improve its performance on that specific task. Here, in this case, the specific task would be answer generation when given a query paired with context. In the research paper -"Searching for Best Practices in Retrieval-Augmented Generation," the authors focused on fine-tuning the generator. Their goal was to investigate the impact of fine-tuning, particularly how relevant or irrelevant contexts influence the generator’s performance.
Deep dive into the fine-tuning process
For the process of fine-tuning, the query input to the RAG system is denoted as 'x' and 'D' as the contexts for the input. The fine-tuning loss for the generator was defined as the negative log-likelihood of the ground-truth output 'y'. The negative log-likelihood measures how well the predicted probability distribution matches the actual distribution of the data.
To explore the impact of fine-tuning, especially with relevant and irrelevant contexts, the authors defined d_gold as a context relevant to the query and d_random as a randomly retrieved context. They trained the model using different compositions of D as follows:
- Dg: The augmented context consisted of query-relevant documents, denoted as Dg={d_gold}.
- Dr: The context contained one randomly sampled document, denoted as Dr={d_random}
- Dgr: The augmented context comprised a relevant document and a randomly selected one, denoted as Dgr={d_gold,d_random}
- Dgg: The augmented context consisted of two copies of a query-relevant document, denoted as Dgg={dgold,dgold}
In this study, Llama-2-7b was selected as the base model. The base LM generator without fine-tuning is referred to as M_b, and the model fine-tuned with different contexts is referred to as M_g, M_r, M_gr, and M_gg . The models were fine-tuned using various QA and reading comprehension datasets. Ground-truth coverage was employed as the evaluation metric due to the typically short nature of QA task answers.
Selecting the best context method for fine-tuning
Following the training process, all trained models were evaluated on validation sets with D_g, D_r, D_gr, and D_∅, where D_∅ indicates inference without retrieval.
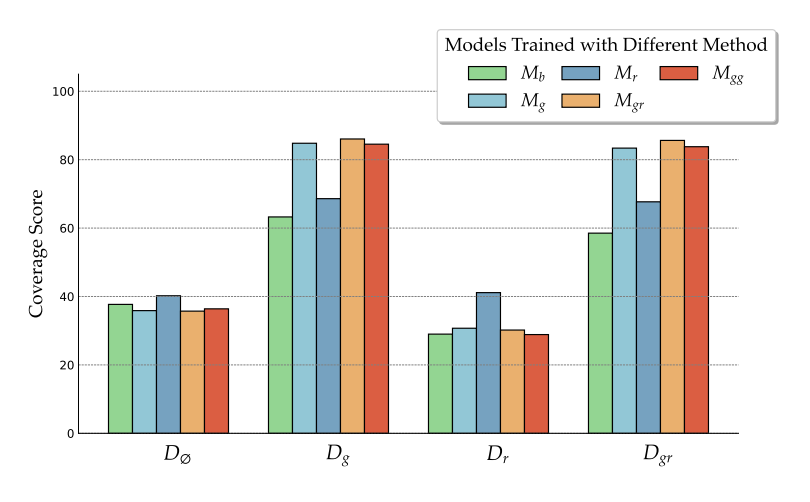
The results demonstrate that models trained with a mix of relevant and random documents (M_gr) perform best when provided with either gold or mixed contexts. This finding suggests that incorporating both relevant and random contexts during training can enhance the generator's robustness to irrelevant information while ensuring effective utilization of relevant contexts.
Conclusion
In this blog, we explored methods to enhance the generation component of RAG systems. Document repacking, with the "sides" method, improves response accuracy by optimizing document order. Summarization techniques like RECOMP and LongLLMLingua reduce redundancy and enhance efficiency, with RECOMP showing superior performance. Fine-tuning the generator improves model performance for specific tasks using relevant and irrelevant contexts. Together, these techniques refine the RAG workflow for more accurate and contextually appropriate responses.
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your RAG performance with Maxim.