RAFT: Adapting Language Model to Domain Specific RAG

Introduction
Large Language Models (LLMs) have transformed many natural language processing tasks, showing impressive abilities in general knowledge reasoning. However, adapting these models to specialized areas like legal documents, medical records, or specific company data is still challenging.
This paper aims to enhance the performance of LLMs in domain-specific question-answering (QA) tasks. Current methods, such as supervised fine-tuning and Retrieval-Augmented Generation (RAG), have their drawbacks. Supervised fine-tuning typically does not utilize external knowledge sources, while RAG often has trouble managing irrelevant information efficiently.
Main Idea
RAFT tackles these challenges by presenting an innovative training method that merges the strengths of supervised fine-tuning and Retrieval-Augmented Generation (RAG). The key concept is to train LLMs to distinguish between relevant and irrelevant documents while answering questions in an "open-book" setting(see image below). This approach allows the model to concentrate on relevant information, leading to the generation of more accurate answers.
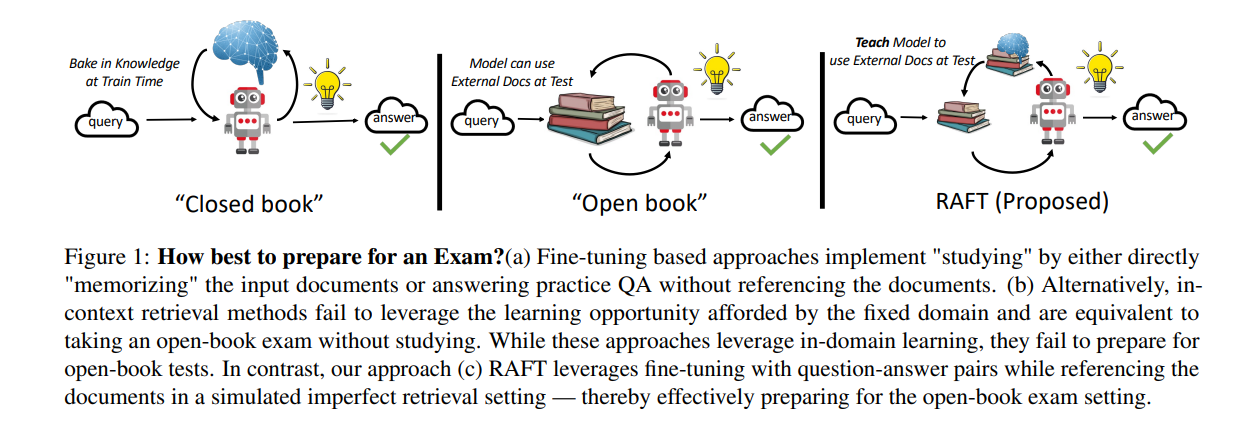
Think of preparing for an open-book exam. You wouldn't aim to memorize every page of the textbook; rather, you'd learn to pinpoint and concentrate on the relevant sections. RAFT adopts a similar approach for LLMs, teaching them to filter out "distractor" documents and extract crucial information from the relevant ones. This enhances their capacity to provide accurate answers within a particular domain.
The approach of RAFT involves two key components: supervised fine-tuning and CoT-style reasoning explanation generation.
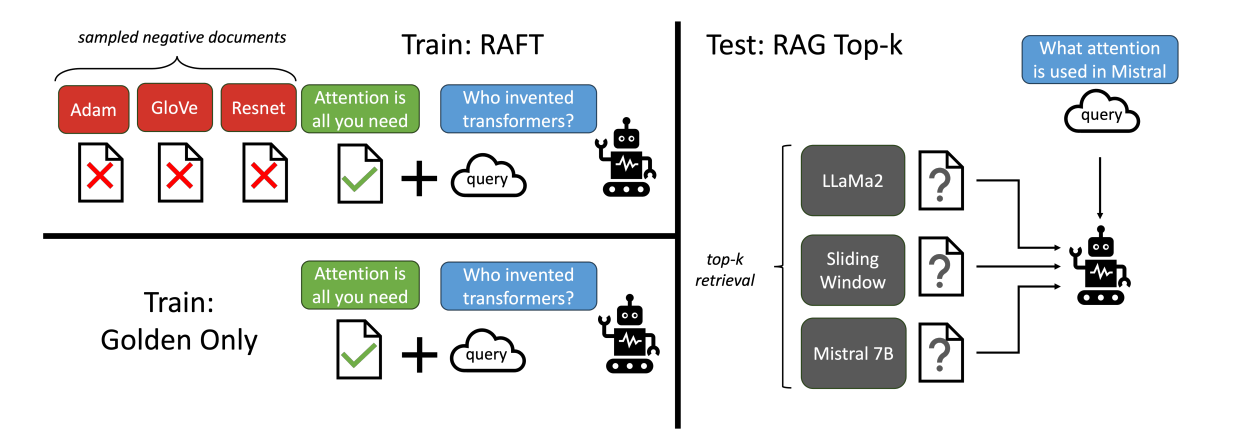
Supervised Fine-Tuning: Initially, a selected LLM is fine-tuned using domain-specific data as training data. This data includes questions (Q), a set of documents (D1, D2, ..., Dn) serving as context, the answer (A), and CoT-style reasoning explanation (A*) for the answer. Among the documents, those containing the answer are termed "oracle documents," while those without the answer are termed "distractor documents." Each data point may consist of one or more oracle documents (D*) and the remaining distractor documents (Dn - D*). The training data is divided such that a certain percentage (P%) contains oracle documents in the context, while the rest (1-P%) contain only distractor documents.
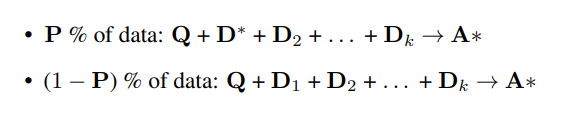
This setup helps the model learn to reference the context and generate a response while also learning to identify when responses are absent in the context.
CoT-style Reasoning Explanation Generation: The CoT-style answer (A*) is generated using another LLM, which utilizes the question, context (D1, ..., Dn), and answer (A). The CoT-style answer (A*) includes keywords ##begin_quote## and ##end_quote##, with the context between these keywords in A* containing citations from the context (Dn) that led to the answer (A). These CoT-style answers provide additional details to the model, enabling it to understand the reasoning process for arriving at a particular answer.
Evaluation
RAFT consistently outperforms existing methods on various benchmarks, demonstrating significant improvements in domain-specific question answering. The inclusion of distractor documents during training enhances the model's robustness and ability to handle irrelevant information effectively.
Experimental Setup:
The experimental setup involved testing the performance of the RAFT framework against several baselines using the LlaMA2–7B-chat model. The baselines used for comparison were:
LlaMA2–7B-chat model
LlaMA2–7B-chat model with RAG
LlaMA2–7B (Domain-specific fine-tuned) - DSF
LlaMA2–7B (Domain-specific fine-tuned with RAG) - DSF+RAG
The datasets utilized for fine-tuning and testing encompassed various domains to evaluate performance comprehensively:
Open-domain Question Answering Datasets:
Natural Questions
TriviaQA
HotpotQA
These datasets primarily focus on common knowledge and cover a wide range of topics.
Biomedical Research Question Answering Dataset:
PubMedQA
This dataset comprises questions and answers related to biomedical research, providing domain-specific content for evaluation.
API Dataset:
Torch Hub
TensorFlow Hub
HuggingFace
These datasets contain information related to various application programming interfaces (APIs), offering diverse content for testing.
Additionally, the GPT-4–1106 LLM was employed to generate CoT-style answers for the training data, facilitating the training process of the RAFT framework.
Observations
The incorporation of a reasoning chain, such as Chain of Thought (CoT), has a profound impact on guiding the model to the correct answer, enhancing its understanding of the task, and ultimately improving overall accuracy and robustness.
A key insight here is:
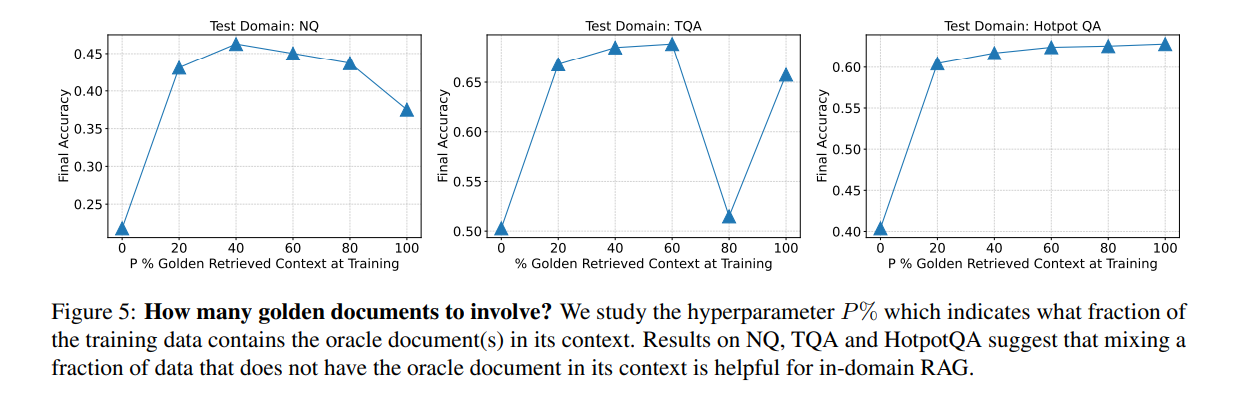
The results reveal that even with just 20% of the training data containing oracle documents within the context, and the remaining 80% comprising solely distractor documents, the models exhibited notable enhancements in performance
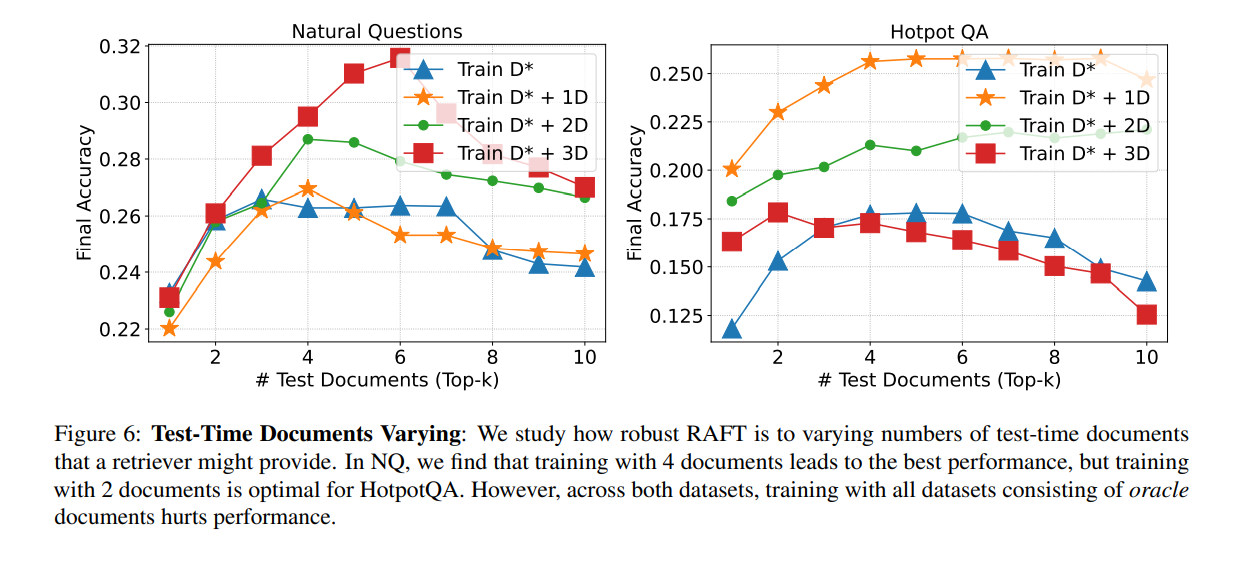
An experiment was conducted to determine the optimal number of distractor documents(D=D*-Dn), such as D* + 1D, D* + 2D, or D* + 3D, to be included during the fine-tuning process. The findings indicated that the model performed better when trained with 2–4 distractor documents. Consequently, during the training phase, 1 oracle document was paired with 4 distractor documents.
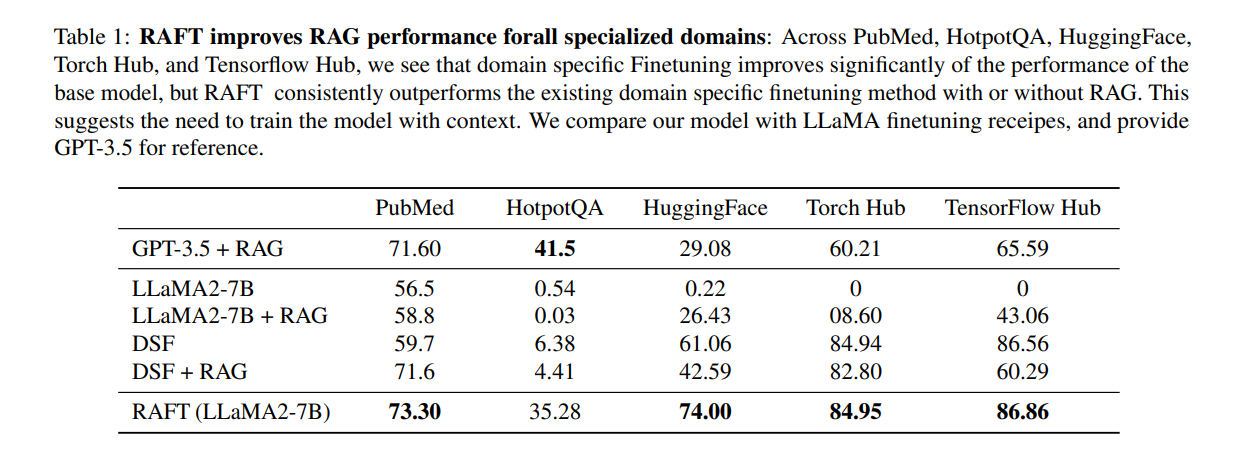
Compared to the base Llama-2 instruction-tuned model, RAFT with RAG demonstrates significantly improved performance in information extraction and robustness against distractors. The improvement can be substantial, reaching up to 35.25% on the Hotpot QA dataset and 76.35% on the Torch Hub evaluation. When compared to DSF on specific datasets, our model exhibits better utilization of provided context to address the task. RAFT notably outperforms DSF on tasks such as HotpotQA and HuggingFace datasets, with gains of 30.87% on HotpotQA and 31.41% on HuggingFace.
The analysis also delves into assessing the impact of the Chain-of-Thought (CoT) approach on enhancing the model's performance. As illustrated in Table 2, merely presenting the answer to a question might not always suffice. This simplistic approach can result in a rapid loss decrease, potentially causing the training process to deviate. By integrating a reasoning chain that not only guides the model to the answer but also enriches its comprehension, overall accuracy can be significantly improved. Our experiments demonstrate that incorporating the Chain-of-Thought notably enhances training robustness. We leverage GPT-4-1106 to generate our Chain-of-Thought prompts, and an example of the prompt used is provided in the figure below

Conclusion: Enhancing Domain-Specific Language Models with RAFT
Fine-tuning language models with domain-specific questions and answers (DSF) alone often fail to access new knowledge effectively, as observed in Retrieval-Augmented Generation (RAG).Furthermore, integrating RAG with DSF (DSF+RAG) may reduce the model's ability to extract relevant information from the context, leading to suboptimal performance.
The innovative approach of RAFT combines domain-specific fine-tuning and RAG to address these challenges. By incorporating golden truth documents in selected training data and using distractor documents as context for the rest, RAFT significantly enhances domain-specific task performance.
This method demonstrates that a strategic fine-tuning process, combined with precise domain data and RAG, can enable even smaller language models to outperform larger ones. This finding highlights the potential of RAFT to revolutionize the effectiveness of domain-specific language models, making it an essential tool for improving the accuracy and relevance of AI-generated content across various specialized fields.
References: