LLM hallucination detection

Introduction
Large Language Models (LLMs) such as GPT-4 and Llama2 generate human-like text, which has enabled a variety of applications. However, alongside this fluency, a major challenge remains hallucinations—situations where the model generates factually incorrect or unverifiable information. Hallucinations in LLMs are not one-dimensional but manifest in various forms, from incorrect entity relationships to invented facts. Traditional methods of hallucination detection have primarily focused on binary classification, distinguishing between factual and non-factual content. However, recent research has highlighted the limitations of this approach, prompting the development of more sophisticated solutions. This blog post explores a new technique called fine-grained hallucination detection, introduced in a paper from the University of Washington and Carnegie Mellon University.
Understanding hallucinations
Hallucinations in LLMs are broadly defined as any factual inaccuracies or unverifiable statements in the generated text. However, hallucinations are not uniform; they vary in type and severity. In the paper, the authors present a taxonomy of hallucinations categorized into six types:
- Entity-level hallucinations: These occur when the model provides incorrect information about an entity. For example, stating "Lionel Messi is the captain of Barcelona" is an entity-level error because Messi plays for Inter Miami, not Barcelona.
- Relation-level hallucinations: These errors involve incorrect relationships between entities. For example, "Paris is the capital of Germany" incorrectly relates Paris to Germany.
- Sentence-level hallucinations: These involve complete statements that contradict factual information. For instance, claiming "The Great Wall of China is located in Japan" is an example of a sentence-level hallucination.
- Invented information: Sometimes, the model generates completely fabricated entities or facts. For example, "Messi is known for his 2017 film 'The Messi Diaries'" invents an event that never happened.
- Subjective statements: These are expressions that are influenced by personal beliefs or opinions, lacking universal validity. For example, "Messi is the best soccer player in the world" is subjective and cannot be factually verified.
- Unverifiable statements: These occur when the model generates information that cannot be fact-checked with available data, such as "Messi enjoys singing songs for his family."

Traditional hallucination detection: limitations
Previous approaches to detecting hallucinations have primarily used binary classification. These models determine whether a generated statement is either factual or non-factual, often based on entity-level errors. While useful in simple cases, this method does not capture the full complexity of hallucinations, especially in nuanced or multi-layered outputs.
For example, a binary model might fail to detect subjective or unverifiable statements, which do not directly contradict known facts but can still be misleading. Similarly, errors involving relationships between entities may not be caught if the entities themselves are factually correct.
Fine-grained hallucination detection
Fine-grained hallucination detection, as introduced in this research, provides a more detailed analysis of LLM outputs by classifying errors into specific types. This approach allows for more precise error correction, as different types of hallucinations require different resolution strategies. The model introduced in the paper, FAVA (FAct Verification with Augmentation), was designed to address this challenge by incorporating RAG with a taxonomy-based hallucination detection system.
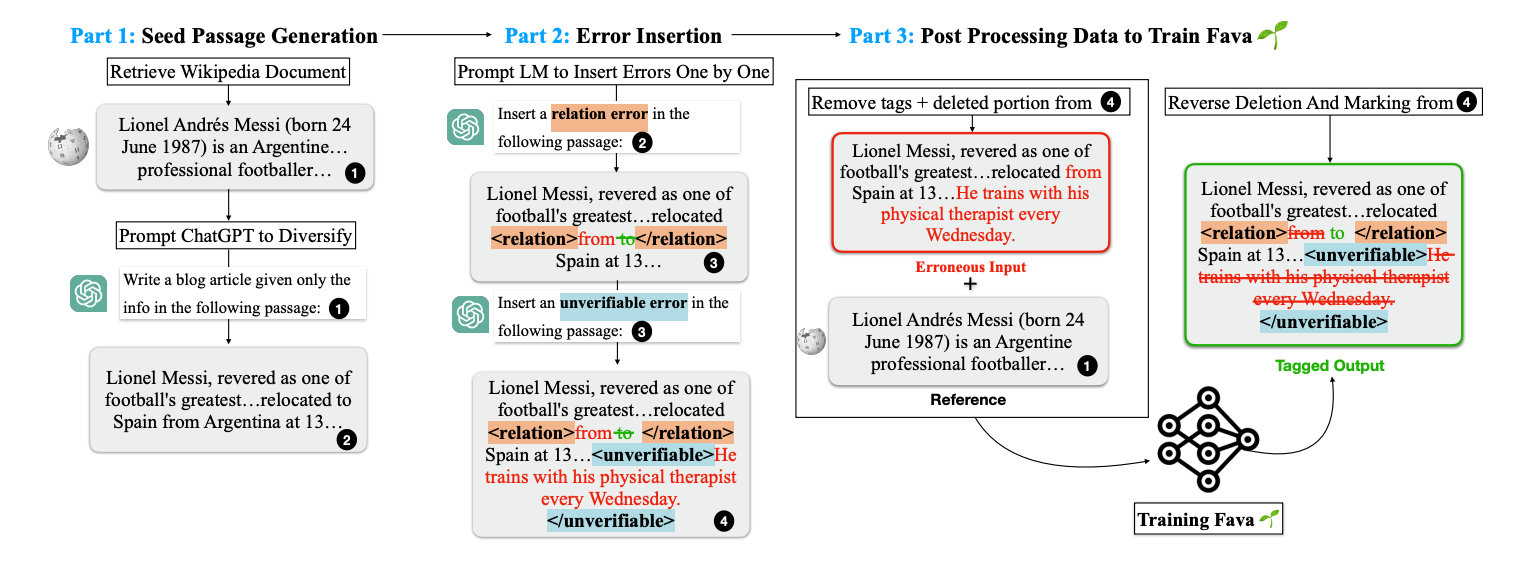
FAVA is trained to detect and edit fine-grained hallucinations at the span level, meaning it can identify specific phrases or segments of text that contain errors. It does this by retrieving relevant external information, comparing it with the generated output, and suggesting corrections. This process is much more nuanced than simply flagging an entire statement as false.
How does FAVA work?
The FAVA system consists of two main components:
- Retriever (Mret): This component retrieves the most relevant documents or facts from external sources (e.g., Wikipedia) that can be used to verify the content of the generated text.
- Editor (Medit): Once the relevant information has been retrieved, the Editor component identifies hallucinations in the output and suggests corrections. This may involve replacing incorrect entities, revising relationships between entities, or removing unverifiable or subjective statements.
FAVA was trained on a large dataset of synthetic errors created by prompting LLMs to insert specific types of hallucinations into otherwise factual text. This training data allowed the model to learn how to detect and correct a wide range of hallucination types.
Evaluation and results
The research team evaluated FAVA on a benchmark dataset of knowledge-intensive queries, comparing its performance to other state-of-the-art LLMs, including GPT-4 and Llama2. The results were striking: FAVA significantly outperformed existing systems on both fine-grained hallucination detection and binary detection tasks.
For example, on the task of entity-level hallucination detection, FAVA achieved an F1 score of 54.5%, compared to 38.6% for GPT-4. Similarly, FAVA’s ability to detect and correct subjective and unverifiable statements was far superior, highlighting its effectiveness in handling more complex types of hallucinations.
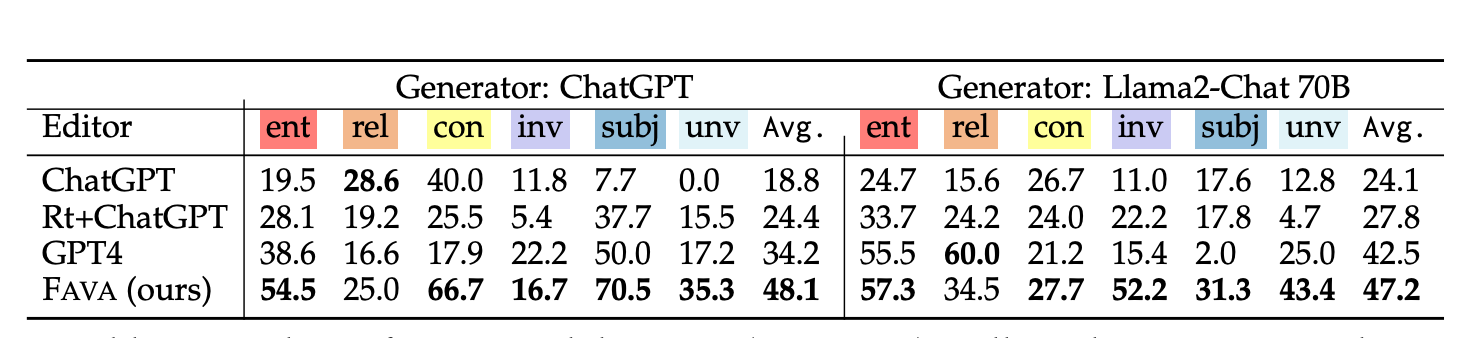
Moreover, FAVA’s ability to suggest edits also led to substantial improvements in the factuality of the final output. The system was able to improve the factual accuracy of Llama2-Chat's outputs by up to 9.3%, demonstrating its potential for real-world applications where precision is critical.
Conclusion
Fine-grained hallucination detection is a game-changer. Systems like FAVA improve LLM accuracy by categorizing hallucinations and providing targeted corrections. However, there is still room for improvement. For example, while FAVA’s performance on invented and unverifiable statements is better than that of existing models, it could be further enhanced by incorporating more sophisticated retrieval mechanisms and broader data sources. Additionally, ongoing research into the interpretability of LLM outputs could help users better understand why certain corrections are made, increasing trust in these systems.
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your Gen AI application's performance with Maxim.