Using a Jury of LLMs Instead of a Single Judge to evaluate LLM generations

As LLMs advance, evaluating their quality is increasingly complex. Using a single large model like GPT-4 as a judge is costly and biased. A research paper by the Cohere team suggests using a Panel of LLM evaluators (PoLL) with smaller models for more accurate, unbiased, and cost-effective assessments.
What’s the issue with the current evaluation with a single Judge?
Using large language models (LLMs) like GPT-4 as evaluators has become increasingly common in AI research and development. However, this approach has notable drawbacks.
1) Evaluator models often exhibit biases, tending to recognize and prefer their own outputs over those generated by other models. So, GPT tends to prefer GPT-generated outputs
2) The practice of using the largest and most capable models for evaluation is both slow and costly, significantly limiting their applicability and accessibility.
What might be a possible solution?
In response to these challenges, researchers are exploring alternative evaluation methods that are more efficient and unbiased. One promising approach is using diverse panels of smaller models, which can provide more balanced assessments while reducing the computational overhead and associated costs. This method not only democratizes access to high-quality evaluations but also enhances the reliability of the results by mitigating model-specific biases.
What is covered in the paper?
- Proposal of PoLL: Evaluate LLM generations using a Panel of LLM evaluators (PoLL) from different model families instead of a single large judge.
- Better Human Judgment Correlation: PoLL shows improved alignment with human judgments compared to a single large judge like GPT-4.
- Cost Efficiency: PoLL is cheaper than using a single large model for evaluations.
- Reduced Bias: PoLL reduces intra-model scoring bias by pooling judgments from a diverse set of evaluator models.
A quick background of LLM as a judge:
A judge evaluator model J is used to score the output from a test model A.
a) Single-Point Scoring
In some settings, an LLM (J) is tasked with independently rating the quality of a single model's output without any point of comparison. The prompt for J typically includes natural language instructions detailing how the grading should be performed, specifying the properties that constitute a good or bad output. Beyond these prompt instructions, the rating relies entirely on J's internal model of what constitutes a quality output. In this scenario, the score is represented as Score = 𝐽(𝑎)
b) Reference-based Scoring
The model relies on reference-based scoring in certain scenarios, where it's given a "gold" reference, denoted as 𝑟. For instance, in Question Answering (QA), this reference corresponds to the "correct" answer to the question. In such In such cases, the scoring function is represented as score = J(a, r).
c) Pairwise Scoring
In another prevalent scenario, pairwise scoring is commonly employed to determine which of the two outputs is superior. Here, given outputs a and 𝑏 generated by models A and B, respectively, an evaluator J compares them and produces a preference score regarding the outputs, expressed as score=J(a,b). The format of the score may vary depending on the specific use case, often represented on a three or five-point scale such as a > b, a ≈ b, a < b
How is scoring done in the case of Polls?
To compute the PoLL score, each evaluator model assesses a provided model output independently, similar to the approaches described earlier. These individual scores are then aggregated through a voting function f; the final score = f(j ∈ P: j(a)), where P is a panel composed of individual judges j and f is a voting function.
The experiment setup
- Poll/Jury Structure:
- So, the PoLL was constructed from three models drawn from three disparate model families (Command R, Haiku, and GPT 3.5)
- Command R (CMD-R, 35B), GPT-3.5, Haiku
- Datasets
a) Single-hop Question Answering
Experiments on datasets from KILT versions of Natural Questions (NQ)question-answer, TriviaQA (TQA), and HotpotQA (HPQA)

b) Multi-hop Question Answering

Cohen’s Kappa Score
Cohen's kappa is a statistic used to measure the agreement between two raters who are evaluating a categorical outcome. Let's break down the formula and its components with an example:
Suppose two doctors are independently diagnosing patients with a certain medical condition. After they've evaluated a set of patients, their diagnoses are compared to determine how much they agree.
- po (observed agreement proportion) is the proportion of cases where the raters agree. For example, if out of 100 cases, the doctors agree on 80 diagnoses, then po=80/100= 0.8
- pe (expected agreement proportion by chance) is the proportion of cases where agreement could occur by random chance alone. It's calculated based on the marginal probabilities of each rater's judgments. If there are, say, three possible diagnoses(A, B, C) for each patient and 2 doctors independently diagnose them, then the possible outcomes are (doctor1-A,doctor2-B),(doctor1-A,doctor2-C), AA, AB, AC, BA, BB, BC, CA, CB, CC (total 9 cases)
Agreement in AA, BB, and CC for both the doctors, so pe=0.33 (3/9).
κ > 0.8 is considered a strong correlation, and κ > 0.6 is a moderate correlation
Now, LLM models and humans are the two judges for Natural Questions (NQ), TriviaQA (TQA), and HotpotQA (HPQA) datasets.

The Cohen’s scores look like this:
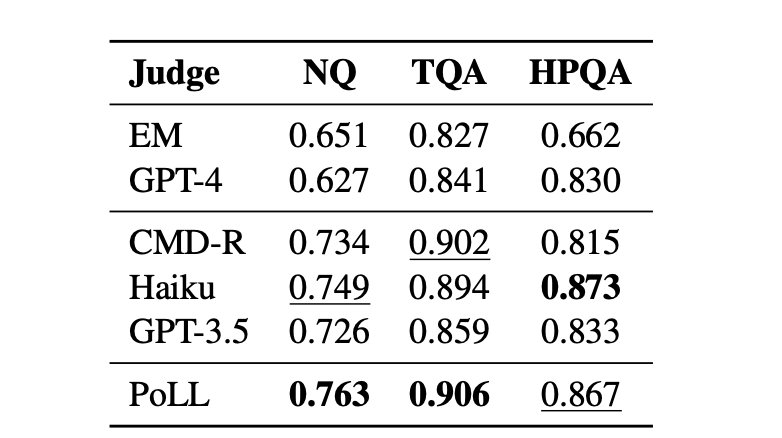
PoLL has the strongest correlation across various tasks, while GPT-4 is one of the weaker evaluators on this particular task setup
Chatbot Arena Hard
Chatbot Arena is a widely recognized benchmark for assessing the head-to-head performance of large language models (LLMs). This crowd-sourced initiative involves users providing prompts to a pair of anonymized LLMs and rating which output is superior.
Assume three chatbots (X, Y, Z) are evaluated by three different judge models (A, B, C), and we also have an overall leaderboard ranking.
- Judge Model A: X = 1st, Y = 2nd, Z = 3rd we can describe it as x=[1,2,3]
- Judge Model B: X = 2nd, Y = 1st, Z = 3rd we can describe it as y=[2,1,3]
- Judge Model C: X = 1st, Y = 3rd, Z = 2nd we can describe it as z=[1,3,2]
- Overall Leaderboard: X = 1st, Y = 2nd, Z = 3rd and the leaderboard rating as l=[1,2,3]
Then, calculate the Pearson correlation between different judge models as compared to the leaderboard rankings by chatbot arena hard

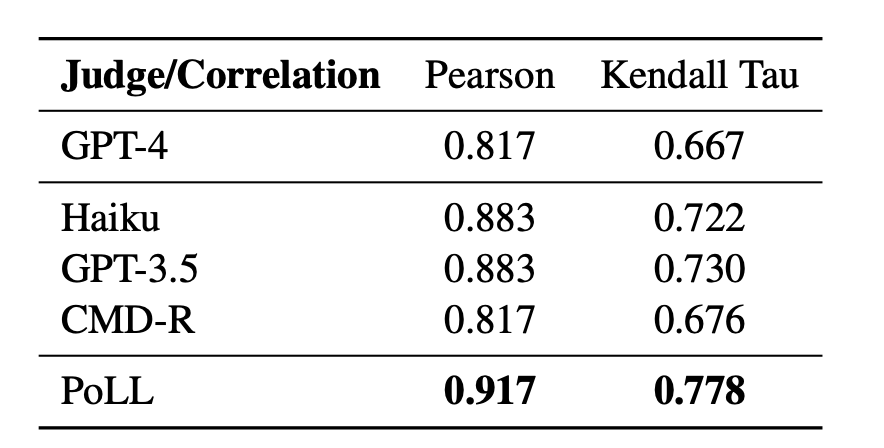
Table 3 shows the correlation between different judge model rankings and human judgment. We consider the crowd-sourced ELO rankings from Chatbot Arena to be the gold standard. Compared to this gold standard, we compute Kendall Tau (Kendall, 1938) and Pearson Correlation (Pearson, 1895) for each judge method's ranked list. Our findings indicate that the PoLL method correlates highest with the gold rankings, particularly for the top-ranked items.
Judge Bias and Consistency
One of the main reasons for replacing a single large judge with a panel of diverse models is to mitigate bias in evaluations. To determine the effectiveness of this approach, they compared the changes in absolute accuracy scores of individual judges and the PoLL method against scores given by human annotators across the multi-hop datasets. This analysis helps assess how well the panel approach aligns with human judgments and reduces bias in the evaluation process.
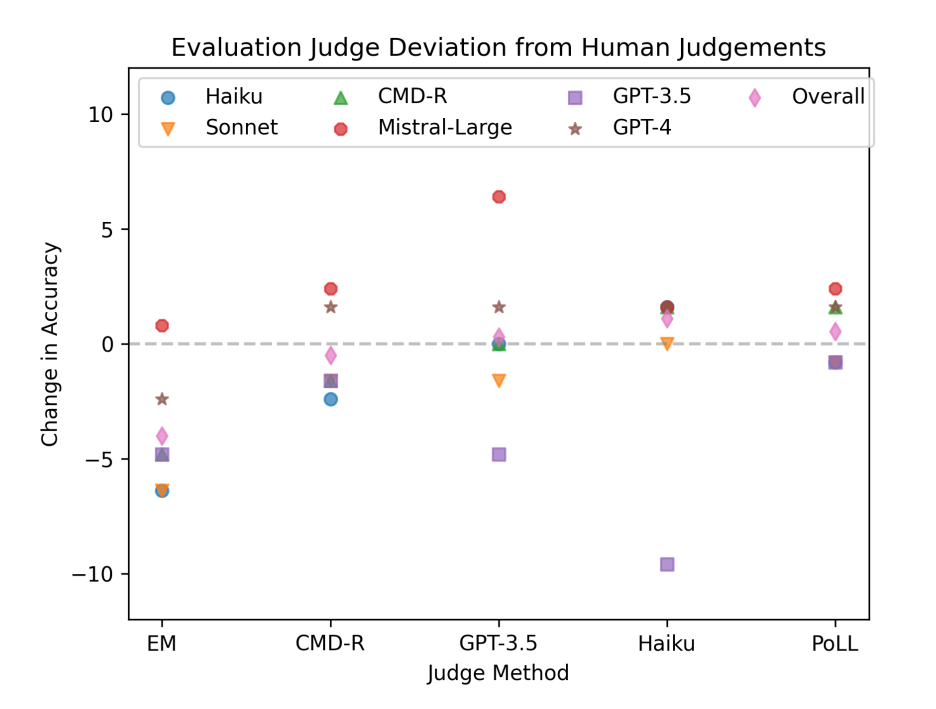
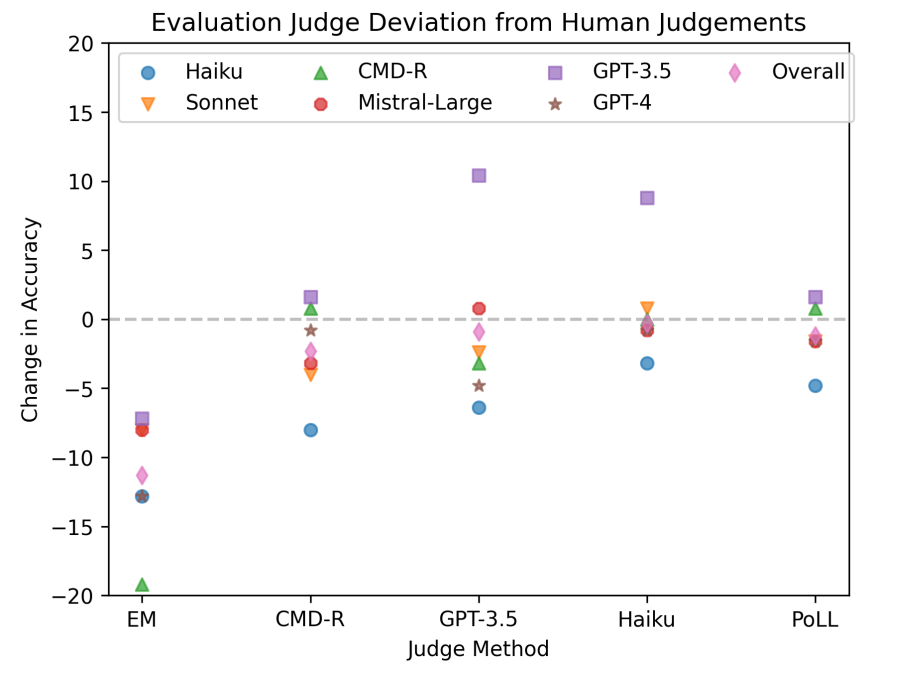
Figures 6 and 7 illustrate the results for HotPotQA and Bamboogle. They show how different judges score various models and the deviations from human annotator decisions (indicated by the dotted line at 0). Overall, PoLL exhibits the smallest score spread, with a standard deviation of 2.2, compared to EM and individual judges. GPT-3.5 shows the largest spread, with a standard deviation of 6.1. Figure 4 also reveals that the highest positive delta for each model occurs when it is judged by itself.
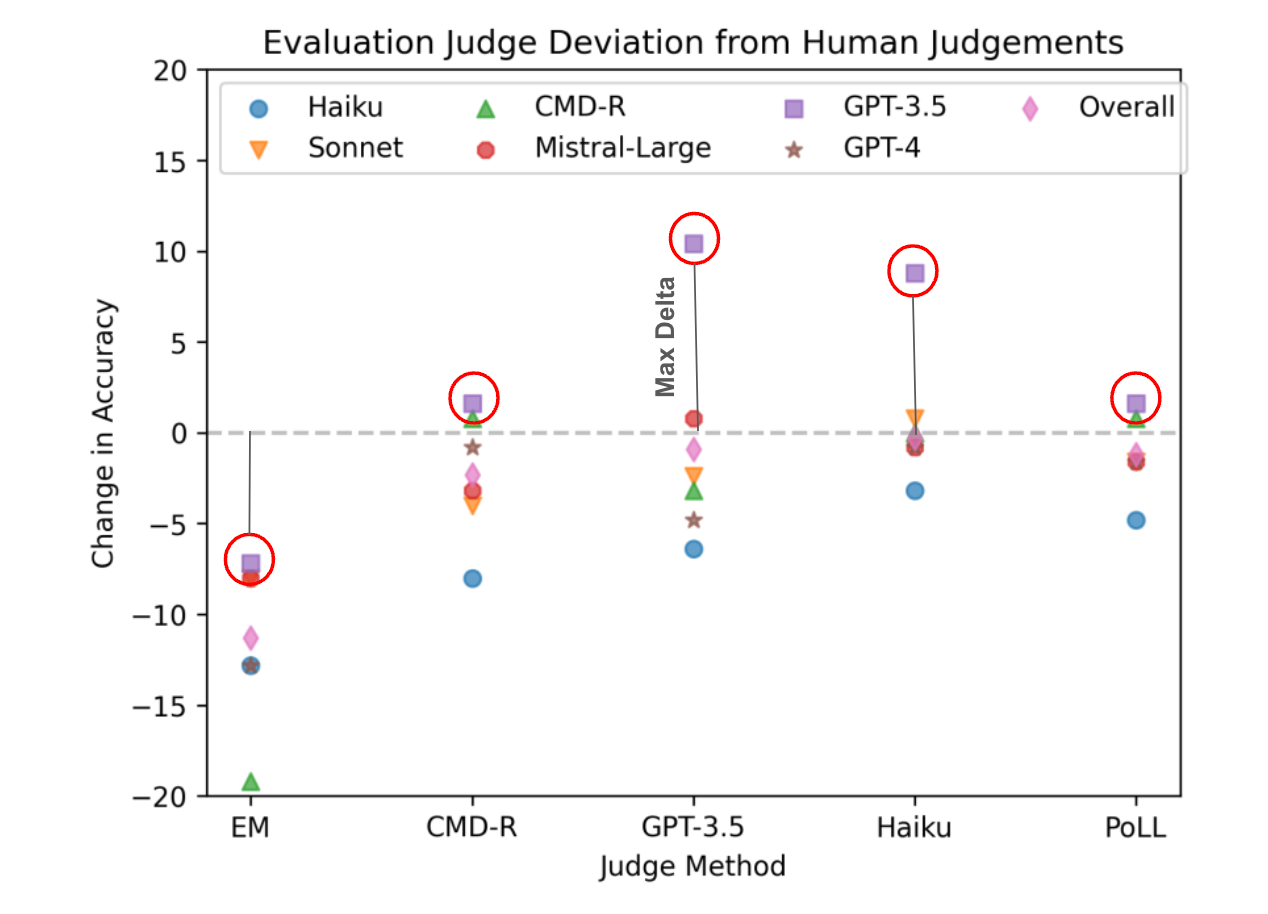
In the above figure (snapshot of figure 4), the max positive delta can be seen when GPT 3.5 is rating itself. It can be seen that GPT-3.5, when rating itself, is very biased (other judges don’t rate it as good as it rates itself). The same can be seen with Haiku and other models.
Cost
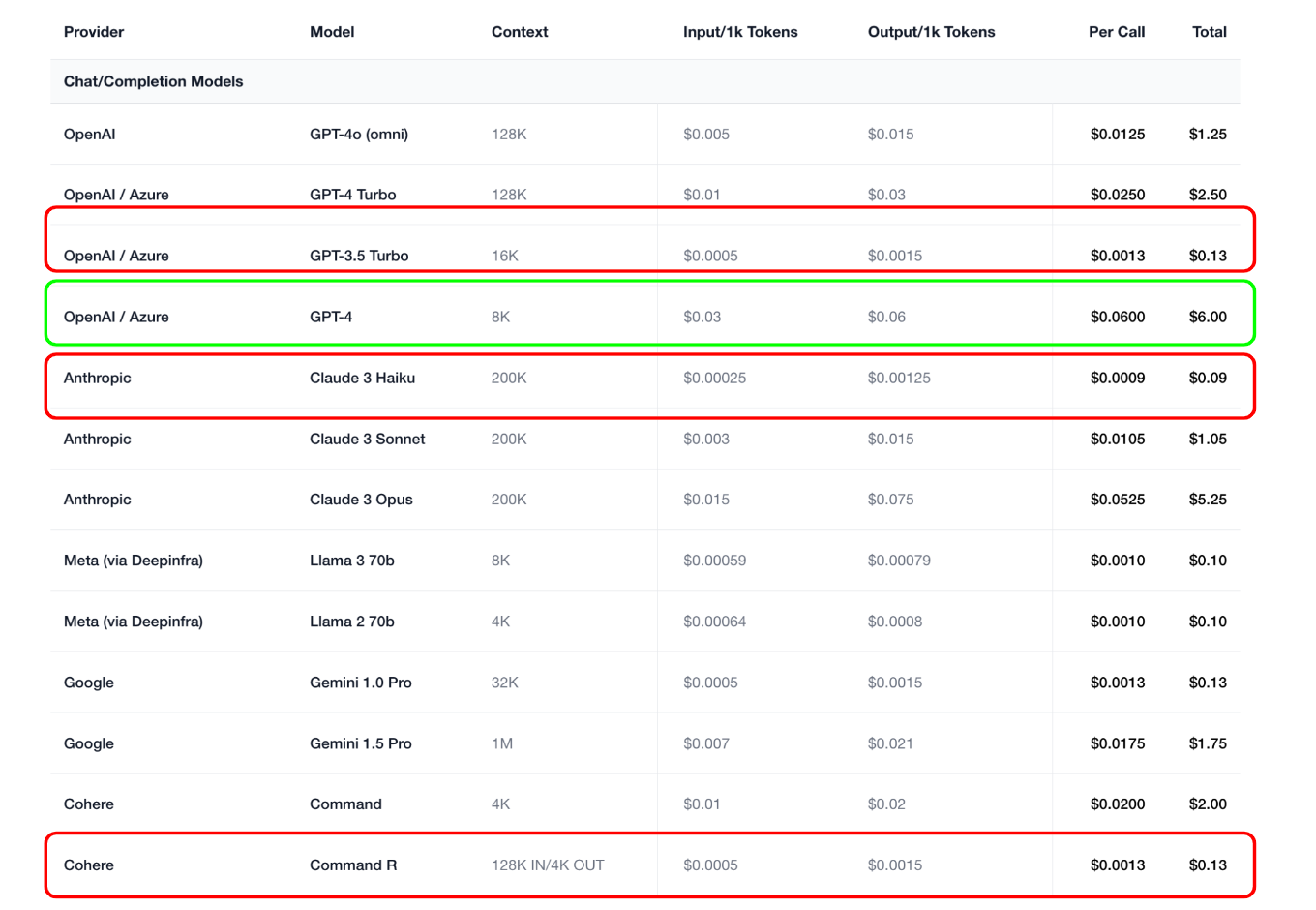
So, there is this website which has updated prices for the models, and when we try to calculate the price of 1000 input tokens to 500 output tokens and doing this call 100 times we find out that (CMD-R, GPT 3.5, Haiku) all together cost $0.35.In stark contrast, the cost for GPT-4 is $6. This highlights a significant price difference between the models.

Conclusion
In this paper, we saw that a Panel of LLM Evaluators (PoLL), consisting of smaller models, effectively evaluates LLM performance and reduces intra-model bias and cost. The findings show that there is no single 'best' judge across all settings, yet PoLL consistently performs well. This paper investigated three evaluator settings with limited judges and panel compositions, finding PoLL to be an effective alternative to a single large model. However, further research is needed to explore its applicability in diverse tasks, such as maths or reasoning evaluations, and to determine the optimal panel selection for quality and cost. On Maxim AI, you can now access our complete range of evaluator models or create your own custom evaluators for your use case. Come and try it out for yourself here!!
References: