KNOWHALU: Hallucination detection via multi-form knowledge-based factual checking

What is "hallucinations" in LLM?
Significant advancements in Natural Language Processing (NLP) have been achieved with the advent of Large Language Models (LLMs). These models excel in generating coherent and contextually relevant text. However, they are prone to "hallucinations." In the context of LLMs, hallucinations refer to instances where the model generates information that seems realistic and coherent but is actually incorrect or irrelevant. For example, an LLM might produce a statement that appears factual but is not based on real data or knowledge. This can be problematic in scenarios requiring precise and accurate information, as incorrect data can lead to misinformation or flawed decision-making. This issue poses a considerable challenge, particularly in applications that demand high factual accuracy, such as medical records analysis, financial reports, and drug design.
Alternate Ways to Mitigate Hallucinations in Large Language Models (LLMs)
To mitigate or detect hallucinations in Large Language Models (LLMs), various approaches have been explored:
- Self-Consistency-Based Approaches: These methods detect hallucinations by identifying contradictions in responses generated stochastically in response to the same query. Imagine asking an LLM the same question multiple times. If it gives different answers each time, you can compare these answers for consistency. Inconsistent answers suggest that at least some of them might be hallucinated.
- Probing LLMs’ Hidden States or Output Probabilities: These approaches involve examining the hidden states or the probability distributions of the LLM’s outputs. Researchers can detect anomalies that might indicate hallucinations by analyzing these internal states or probabilities. However, these methods do not use external knowledge and are therefore limited by the LLM’s internal knowledge.
- Post-Hoc Fact-Checking: Recently, post-hoc fact-checking approaches have shown effectiveness in detecting hallucinations even when the LLM’s internal knowledge is insufficient. These methods involve verifying the generated responses against external knowledge sources. Despite their success in achieving state-of-the-art (SOTA) hallucination detection, they still face challenges. LLMs often struggle with accurate factual checking, especially when queries involve complex logic or multiple factual assertions. This difficulty arises because LLMs have limitations in their reasoning capabilities, which can affect their performance even if the extracted knowledge is correct.
KnowHalu
KnowHalu is a novel approach to detecting hallucinations in text generated by large language models (LLMs).KnowHalu This approach features two main phases: non-fabrication hallucination detection and multi-step factual checking, utilizing multi-form knowledge for factual verification. Notably, KnowHalu is the first to define and categorize non-fabrication hallucinations in general. In this blog, we will take an in-depth look at hallucination detection using the KnowHalu research paper.
What can be labeled as hallucinations?
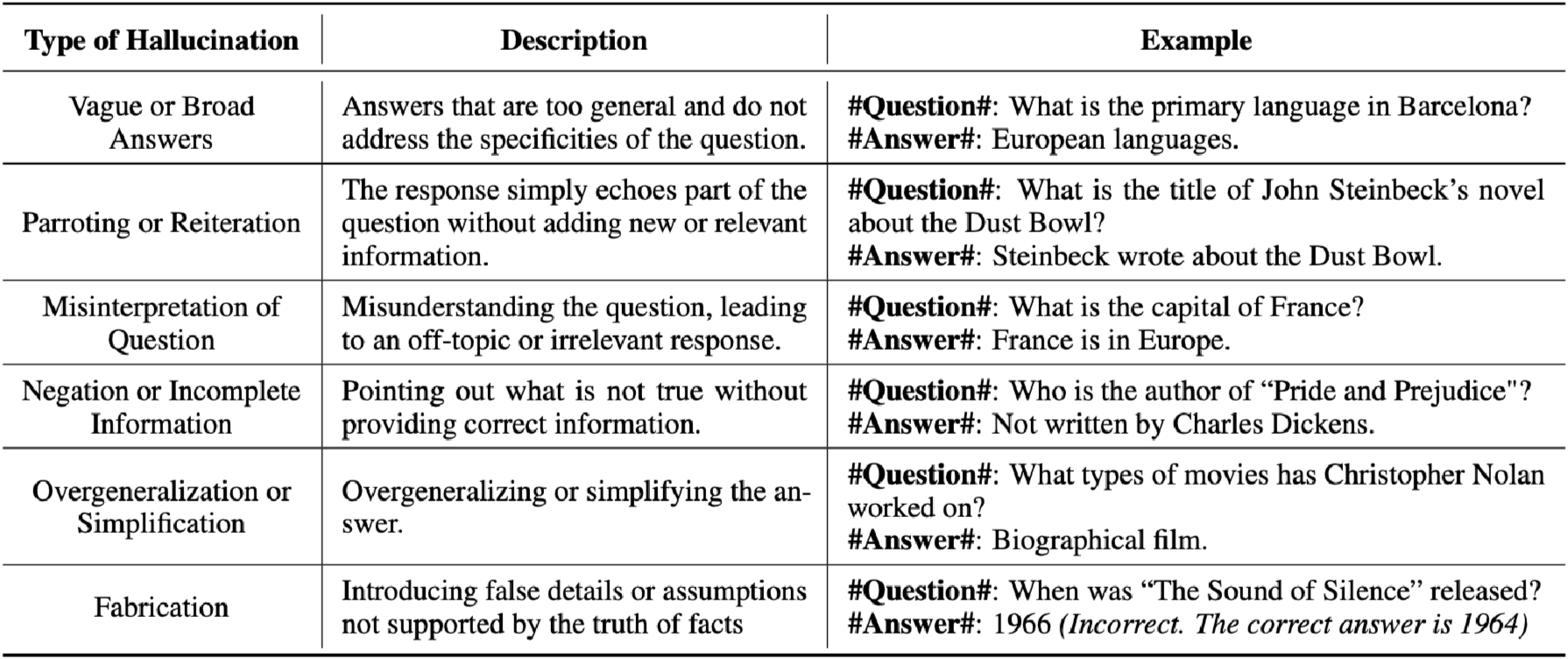
Current approaches in hallucination detection mainly focus on identifying fabricated hallucinations, where the generated answers contain facts that do not match reality. However, hallucinations can also take other forms that go beyond simple factual inaccuracies. A key characteristic of these non-fabricated hallucinations is that, while they may be factually correct, they do not directly address the original query. For example, if asked, "What is the primary language in Barcelona?" a hallucinated response might be "European languages." This answer, though factually correct, lacks specificity and relevance to the question, which is crucial for real-world applications of large language models (LLMs).
Detecting non-fabricated hallucinations
KnowHalu introduces a "Non-Fabrication Hallucination Checking" phase. This phase aims to detect hallucinations that are factually correct but irrelevant. A straightforward method might involve prompting the LLM to identify such hallucinations using examples. However, this often leads to high false positives, where correct answers are wrongly flagged as hallucinations.
To mitigate this, KnowHalu uses an extraction task. This task prompts the LLM to extract specific entities or details requested by the original question from the answer. If the model fails to extract these specifics, it returns "NONE." This extraction-based specificity check reduces false positives and effectively identifies non-fabrication hallucinations. Responses marked as "NONE" are directly labeled as hallucinations, and the remaining answers proceed to the next phase for further factual verification.

Detecting fabricated hallucinations
The Factual Checking phase in KnowHalu's framework detecting factual hallucinations consists of five key steps: Step-wise Reasoning and Query, Knowledge Retrieval, Knowledge Optimization, Judgment Based on Multi-form Knowledge, and Aggregation. These steps work together to ensure the accuracy and reliability of the answers provided by the system. This section references a detailed research paper on the topic.
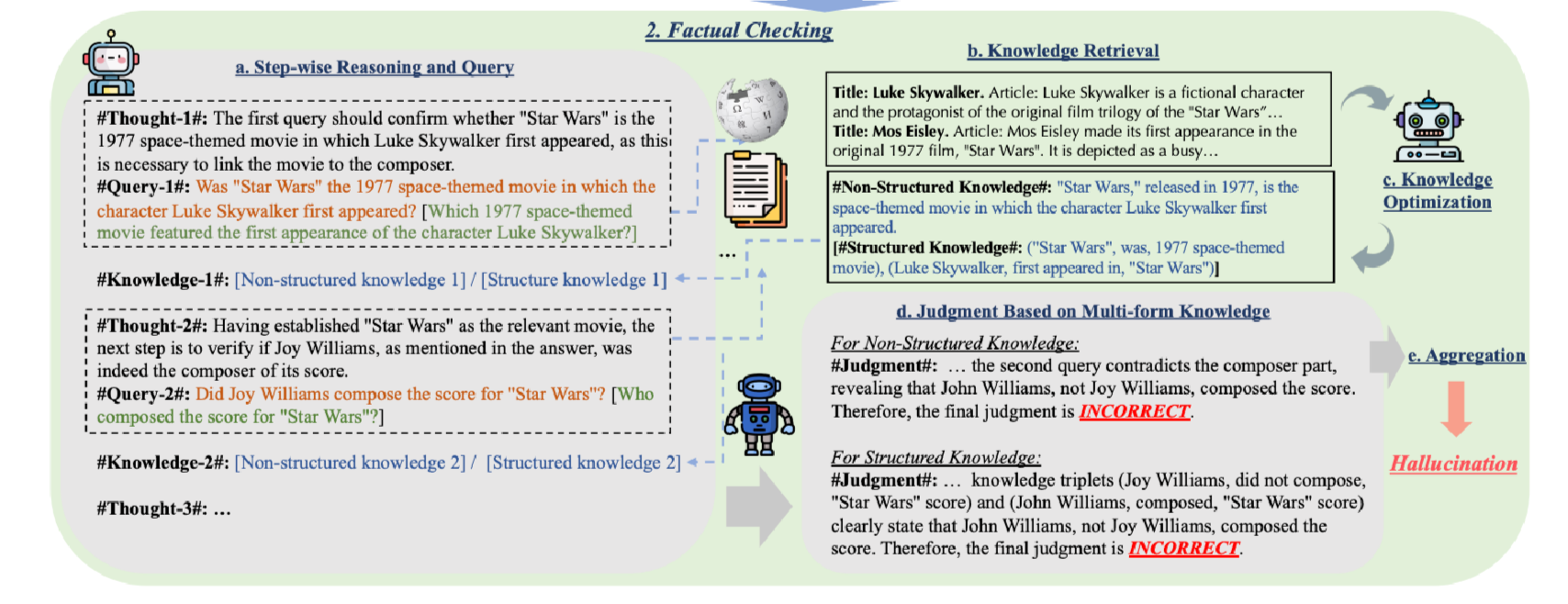
a. Step-wise Reasoning and Query
This step breaks down the original query into sub-queries following a logical reasoning process. The goal is to generate various forms of sub-queries and perform factual checking cumulatively. This method is similar to the ReAct framework, focusing on breaking complex queries into simpler, one-hop sub-queries. The key challenge is crafting precise and effective sub-queries to accurately retrieve relevant knowledge at each logical step.
- Reason to choose One-hop Queries: Multi-hop queries often struggle due to their complexity and ambiguity, leading to less specific knowledge retrieval. Conversely, one-hop queries are simpler and more direct, enhancing retrieval accuracy. For example, a complex query about "Star Wars" would first confirm the movie's details before examining specific aspects, such as the composer’s identity.
- Query Formulation: How queries are formulated is crucial for accurate factual checking. General Queries avoid specific, potentially incorrect details (e.g., "Who composed the score for 'Star Wars'?"), while Specific Queries include key entities mentioned in the answers (e.g., "Did John Williams compose the score for 'Star Wars'?").
b. Knowledge Retrieval
In this step, knowledge is retrieved for each sub-query generated. The Retrieval-Augmented Generation (RAG) framework, based on the Wikipedia knowledge base, is used for this task. Tools like ColBERT v2 and PLAID help retrieve the most relevant passages formatted as "Title: ..., Article: ...".
For summarization tasks, the source document itself is treated as the knowledge base. The document is segmented into text chunks, and sub-queries and text chunks are embedded into dense vectors using a text encoder. The top-K text chunks with the highest cosine similarity to the sub-queries are then retrieved.
c. Knowledge Optimization
The retrieved knowledge is often long and verbose, with irrelevant details. Knowledge Optimization leverages another large language model (LLM) to distill useful information and present it concisely. This knowledge can be in unstructured form (e.g., concise summaries) or structured form (e.g., object-predicate-object triplets).
- Unstructured Knowledge: Summarized text providing essential information.
- Structured Knowledge: Triplets representing key facts (e.g., ("Star Wars", was, 1977 space-themed movie)).
d. Judgment Based on Multi-form Knowledge
This step involves presenting the sub-queries and their corresponding retrieved knowledge to another LLM for judgment. The LLM assesses whether the sub-query and its knowledge match, marking the answer as CORRECT, INCORRECT, or INCONCLUSIVE. If there's any conflict between the answer and the retrieved knowledge, the judgment is INCORRECT.
e. Aggregation
Aggregation combines judgments based on different forms of retrieved knowledge to make a final prediction. This mechanism helps mitigate prediction uncertainty and enhances accuracy. If the base judgment's confidence score is low and the supplementary judgment's confidence is high, the final prediction relies on the supplementary judgment.
- Tokenization Consistency: Different models might tokenize judgment labels differently. For instance, ‘INCORRECT’ might be tokenized as ‘INC’, ‘OR’, ‘RECT’, while ‘CORRECT’ can be ‘COR’, ‘RECT’. The framework consistently uses the confidence score of the first token of the judgment label to maintain consistency.
Let's break down the "Judgment Based on Multi-form Knowledge" and "Aggregation" steps with an example for better understanding.
Example Scenario
Query: Who composed the famous musical score for the 1977 space-themed movie in which the character Luke Skywalker first appeared?
Answer: Joy Williams composed the score for "Star Wars."
Step 1: Judgment Based on Multi-form Knowledge
Step-wise Reasoning and Query
The query is broken down into sub-queries:
- Did "Star Wars" release in 1977 and feature Luke Skywalker?
- Did Joy Williams compose the score for "Star Wars"?
Knowledge Retrieval: Relevant information is retrieved:
- Unstructured Knowledge: "Star Wars," released in 1977, is the space-themed movie where Luke Skywalker first appeared.
- Structured Knowledge: ("Star Wars", release year, 1977), (Luke Skywalker, first appeared in "Star Wars")
- Unstructured Knowledge: The composer of the "Star Wars" score is John Williams.
- Structured Knowledge: (John Williams, composed, "Star Wars" score)
Knowledge Optimization: Optimize the retrieved knowledge for clarity:
- Unstructured: "Star Wars," released in 1977, is the movie where Luke Skywalker first appeared.
- Structured: ("Star Wars", release year, 1977), (Luke Skywalker, first appeared in, "Star Wars")
- Unstructured: John Williams, not Joy Williams, composed the score for "Star Wars."
- Structured: (John Williams, composed, "Star Wars" score), (Joy Williams, did not compose, "Star Wars" score)
Judgment Generation
Evaluate the sub-query answers against the optimized knowledge:
- Correct: The movie "Star Wars" matches the 1977 release and features Luke Skywalker.
- Incorrect: Joy Williams is not the composer; John Williams is.
Final Judgments
- Correct: The movie details are accurate.
- Incorrect: The composer's details conflict with the retrieved knowledge.
Step 2: Aggregation
Aggregation of Judgments
Combine judgments from structured and unstructured knowledge:
- Movie Detail Judgment:
- Unstructured: Correct
- Structured: Correct
- Composer Detail Judgment:
- Unstructured: Incorrect
- Structured: Incorrect
Final Aggregated Judgment
- For the movie details, both sources agree it's correct.
- For the composer details, both sources agree it's incorrect.
Final Judgment: The answer is incorrect due to the wrong composer detail, despite the correct movie detail.
Why KnowHalu is Better?
KnowHalu outperforms existing baselines in detecting factual hallucinations due to its comprehensive use of both structured and unstructured knowledge, combined with effective aggregation techniques. The results from the experiments, summarized in the tables below, highlight its superior performance across various tasks and configurations.
Key Metrics:
- True Positive Rate (TPR): Indicates the model's ability to correctly identify hallucinations.
- Average Accuracy (Avg Acc): Reflects overall performance in distinguishing correct and hallucinated content.
Table 4: Performance Comparison Using Different Query Formulations
| Query Type | Knowledge Form | TPR (%) | Avg Acc (%) |
|---|---|---|---|
| Specific | Structured | 57.4 | 60.75 |
| Unstructured | 66.0 | 65.45 | |
| General | Structured | 65.6 | 62.15 |
| Unstructured | 70.4 | 65.55 | |
| Combined Queries | Structured | 68.1 | 66.85 |
| Unstructured | 68.2 | 69.05 |
Table 5: Performance Using Different Number of Retrieved Passages
| Top-K Passages | Knowledge Form | TPR (%) | Avg Acc (%) |
|---|---|---|---|
| K = 1 | Structured | 61.1 | 62.70 |
| Unstructured | 65.6 | 65.20 | |
| K = 2 | Structured | 68.1 | 66.85 |
| Unstructured | 68.2 | 69.05 | |
| K = 3 | Structured | 67.2 | 66.70 |
| Unstructured | 68.6 | 69.70 | |
| K = 4 | Structured | 67.1 | 66.45 |
| Unstructured | 68.8 | 69.20 | |
| K = 5 | Structured | 64.2 | 65.75 |
| Unstructured | 66.9 | 69.80 |
Key Advantages of KnowHalu:
- Higher TPR and Avg Acc: Consistently shows higher true positive rates and average accuracy compared to other models, indicating better detection capabilities.
- Effective Use of Multi-form Knowledge: Combines structured and unstructured knowledge to leverage the strengths of both forms, providing comprehensive assessment and verification.
- Aggregation of Judgments: Improves final predictions by combining insights from different knowledge sources, reducing uncertainty and enhancing reliability.
- Versatility and Robustness: Performs well across different query types and with varying amounts of retrieved passages, demonstrating flexibility and robustness.
Evaluators are the cornerstone of the Maxim platform. Evaluators are the quality and safety signals you want to test your application on. At Maxim, we've developed a comprehensive suite of evaluators available for your testing needs right out of the box. Our platform even allows you to assess hallucinations, ensuring robust and reliable application performance.