FastLongSpeech: 30x Compression That Doesn't Murder Your Context

Speech models are having a moment and seems like they’re here to stay. They can transcribe your rambling, understand your questions, and even tell when you're being sarcastic. But ask them to process anything longer than a TikTok video and they straight-up collapse.
The problem? Speech can be wasteful. A 30-second audio clip explodes into token sequences 4x longer than text saying the same thing. It's like your model is reading every word five times while also describing the font. And when you try scaling up to actual long-form content (think podcasts, meetings, lectures) the computational cost goes nuclear.
Most LSLMs (Large Speech-Language Models) tap out around 30 seconds. The few that push to 30 minutes do it by drowning the problem in specialised training data that costs more to generate than most research budgets.
FastLongSpeech says: what if we just... compressed smarter?
The Pied Piper Problem (Minus the Valley Drama)
Remember Pied Piper from Silicon Valley? Their whole breakthrough was middle-out compression: figuring out what information actually mattered and ditching the rest without destroying the file.
FastLongSpeech is doing something similar, except instead of compressing video files to save storage, they're compressing speech representations to save your GPU from thermal death.
The insight's the same: lossless compression is a lie when you're dealing with redundant data. Speech frames are full of redundancy. They have repeated sounds, silence, acoustic filler. Traditional approaches treat every frame like it's precious. FastLongSpeech asks: what if we measured which frames actually carry meaning and compressed accordingly?
No pivoting to a box business required.
The Core Insight: Not All Speech Frames Matter Equally
Here's what the researchers noticed: speech representations are full of junk. Repeated sounds, silence, those awkward "uhhhh" moments lead to tons of frames that add length but zero meaning.
Traditional compression approaches treat all frames equally. Average pooling? Just smush everything together. Random sampling? Hope you didn't throw away something important. Both are basically flying blind.
FastLongSpeech does something cleverer: it measures which frames actually contain information and which ones are just acoustic filler. Then it compresses accordingly.
Two metrics drive this:
- Content Density : How much actual text-equivalent information is in this frame?They use CTC (Connectionist Temporal Classification) probabilities to figure this out. High probability of non-blank tokens = this frame matters. Low probability = probably just background noise or a pause.
- Frame Similarity : Are these adjacent frames basically saying the same thing?Cosine similarity between consecutive frames. High similarity = redundant, safe to merge.
Armed with these two signals, the model can make intelligent choices about what to keep and what to squish.
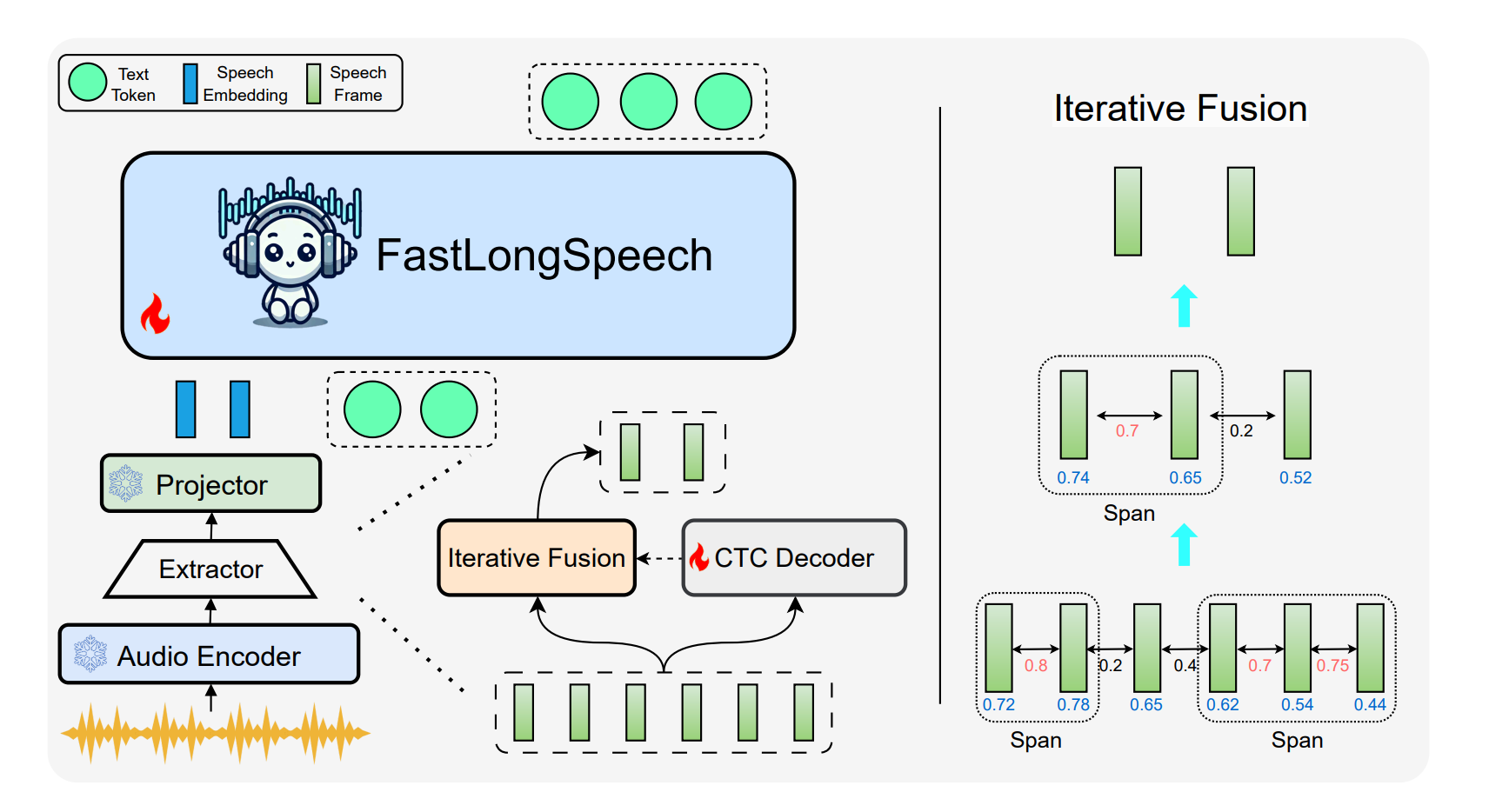
Iterative Fusion: Compression That Actually Preserves Meaning
The compression happens in stages. Each iteration:
- Identifies the most similar adjacent frame pairs
- Groups consecutive similar frames into "spans"
- Merges each span using content density as weights (keeps the informative bits)
- Cuts sequence length roughly in half
Repeat until you hit your target length.
This progressive approach does two smart things:
- Expands receptive field gradually instead of doing one brutal compression pass
- Prioritizes information-rich frames so you don't accidentally delete the entire point of the sentence
The result? You can compress 30x and still maintain decent quality on QA tasks. Middle-out vibes, minus the Erlich Bachman toxicity.
Training Trick: Learn Compression Without Long Audio
Here's where it gets interesting. They don't have long-form speech training data. Nobody does, really, it's expensive and rare.
Instead, they train in two stages:
Stage 1: Train a CTC decoder on regular ASR data. This teaches the model to recognize content density, ie. which frames have information vs. which are just vibes.
Stage 2: Dynamic compression training on short speech with varying compression ratios.
That second part is key. During training, they randomly sample target lengths: {750, 400, 200, 100, 50, 25, 12} frames. The model sees the same short audio compressed at different levels and learns to handle both light and aggressive compression.
This means the LLM gets exposed to compressed representations without needing actual long-form training data. You're essentially teaching it: "sometimes speech is dense, sometimes it's sparse, deal with both."
Turns out? It transfers beautifully to long-form tasks it's never seen.
The Benchmark
They also built LongSpeech-Eval because apparently nobody had a proper long-speech understanding benchmark.
Built on top of LongBench (a text-based long-context dataset), they:
- Filtered out formula-heavy and non-English content
- Converted documents to spoken form using GPT-4o
- Synthesized speech with Orca TTS
164 samples, averaging 133 seconds, maxing out at 1000 seconds. Questions require actually understanding the content, not just transcribing it.
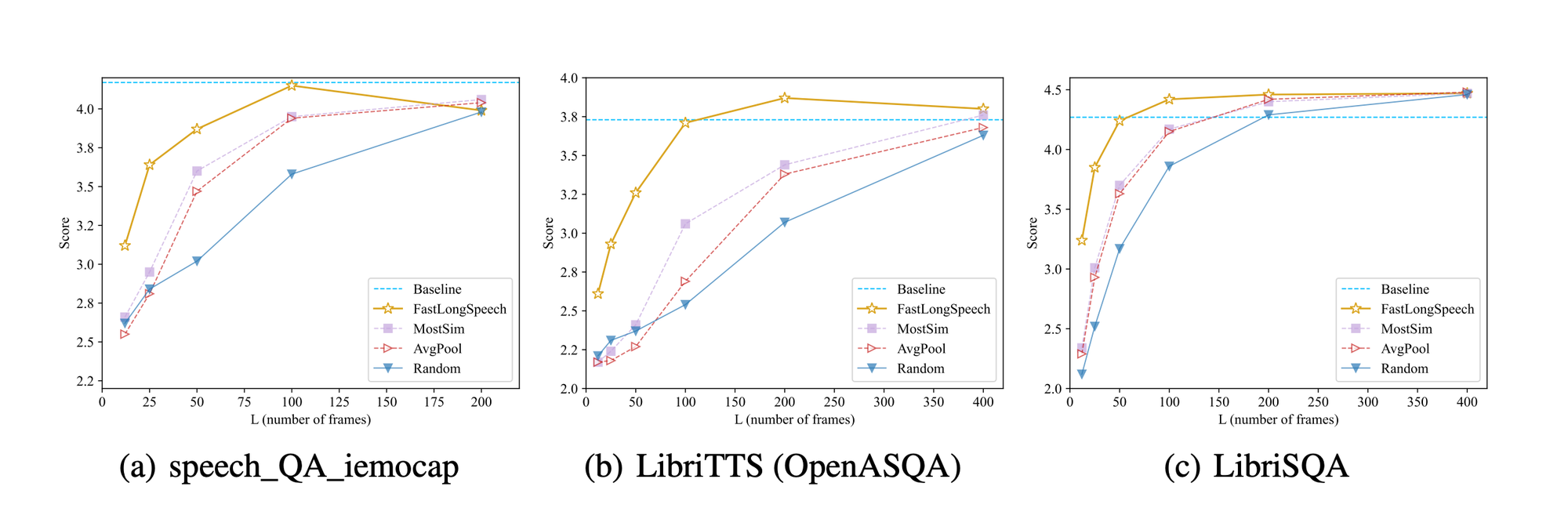
And it works!
- Long speech performance: 3.55 score (on their 1-5 scale), beating methods like NTK-RoPE that just stretch the context window. And it does this while being 60% cheaper computationally and 7x faster than cascaded approaches.
- Short speech: At L=200 (moderate compression), matches vanilla Qwen2-Audio quality with half the compute cost. Even at 30x compression (L=25), still pulls decent scores.
- Task-dependent sweet spots:
- ASR degrades at extreme compression (makes sense, you need all the phonemes)
- But QA and dialogue understanding? Still strong even at 15-30x compression
- Emotion recognition maintains performance with 50% cost reduction
- The ablation studies confirm what you'd expect:
- Dynamic compression training is critical (without it, performance tanks)
- Iterative fusion beats single-step compression significantly
- Content density weighting is the MVP, removing it hurts the most
What This Means for Practitioners
You can now handle long audio without specialized infrastructure. Compress at inference time based on your compute budget and quality requirements. Need fast responses? Crank up compression. Need perfect transcription? Dial it back.
No expensive long-speech training data required. The approach transfers from short to long naturally, which is huge for anyone building speech applications without Google-scale resources.
Generalizes beyond the base model. They tested on vanilla Qwen2.5-Omni without the second training stage, still worked. The iterative fusion strategy is robust enough to bolt onto existing LSLMs.
The Limitations (Because Nothing's Perfect)
The paper's honest about constraints:
- Still designed around 30-second base model limitations
- Optimal compression ratios are task-dependent (you'll need to tune)
- As actual long-speech data becomes available, there's room to improve further
Also worth noting: they're compressing after the audio encoder. Earlier compression (in the encoder itself) might yield even better efficiency, but that's future work territory.
Bottom Line
FastLongSpeech solves a real problem: making speech models handle realistic-length audio without requiring proportional increases in compute or magical long-form datasets.
The iterative fusion strategy is elegant: measure what matters, compress what doesn't, do it progressively. The dynamic compression training is clever: learn from short examples at varying densities, transfer to long contexts naturally.
And critically, it's practical. You can actually use this. Bolt the extractor onto an existing LSLM, train on short-speech data you already have, and suddenly your model handles hour-long audio without melting your GPUs.
Richard Hendricks would be proud. Except this actually ships.
Paper: FastLongSpeech: Enhancing Large Speech-Language Models for Efficient Long-Speech Processing


