Evaluating the Quality of AI HR Assistants using Maxim AI

Use of Artificial Intelligence in Human Resources is reducing administrative load by automating routine tasks such as hiring and resolving employee queries, freeing HR teams to focus on people-centric initiatives. The applications of AI span every stage of the HR workflows, including:
- Sourcing candidates from large talent pools
- Screening thousands of resumes to identify the best-fit candidates
- Conducting interviews and assessments using AI-powered tools
- Onboarding and training new employees with AI-personalized programs
- Enhancing employee experience through AI-enabled policy guidance, PTO management, and reimbursement support
In high-impact HR scenarios, it's critical to ensure AI systems operate accurately and without bias. A well-known example is Amazon’s internal AI recruiting tool, which was found to show bias against female applicants. This high-profile failure highlights the importance of rigorous quality assurance and continuous monitoring to prevent discriminatory outcomes, ensure legal compliance, and maintain trust among candidates and employees.
In this blog, we’ll explore how to ensure the reliability of AI-powered HR applications. We’ll take the example of an internal HR assistant that improves employee experience by providing answers on company policies such as benefits, PTO, and reimbursements. Our focus will be on evaluating the quality of the responses using Maxim's evaluation suite.
Evaluation Objectives
We want to ensure:
- Assistant responses are grounded in the knowledge source we provided.
- The responses are unbiased (i.e., check for gender, racial, political, or geographical bias)
- Assistant is using the most relevant chunks of policy information for a given query.
- The tone of responses is polite and friendly.
- The assistant operates with low latency and predictable cost
Step 1: Prototype an AI HR Assistant in Maxim’s Prompt Playground
We’ll build a RAG-based HR QnA assistant by creating a prompt in Maxim’s no-code UI and using a text file containing company policies as the context source.
- Create prompt: Head to "Single prompts" in the "Evaluate" section and click "+" to create a new prompt. Let's name this:
HR_RAG_Assistant - Define system message: We'll use the following prompt to guide our HR assistant to generate helpful answers to employee queries.
Include at least one direct quote from the context, enclosed in quotation marks, and specify the section and page number where the quote can be found.
Ensure the response is friendly and polite, adding "please" at the end to maintain a courteous tone.
- Using Maxim, we can define dynamic variables in the prompt. Here, we’ll attach our context source as the value for the {{context}} variable.
Creating a assistant in Maxim's Prompt Playground
- Create context source: This is the knowledge base that our assistant will use to generate its responses. We can bring our context source into Maxim by directly importing the file containing the information or by bringing the retrieval pipeline through an API endpoint.
- We’ll use the HR_policy.txt file containing the data of the company policies and upload it to Maxim.
- To add a context source, go to the "Library" section and select "Context sources".
- Click the "+" button to add a new context source and select "Files" as the type.
- Select "Browse files" to upload our knowledge base (
HR_policy.txtfor our example). - Maxim will automatically convert the file’s content into chunks and embeddings using the
text-embedding-ada-002model. These embeddings enable the retrieval of context that is relevant to the user’s query.
Adding a file as a context source
- Connect the context source to our prompt in the Prompt Playground, under the "Variables" section. Also, select an LLM of choice (using Gemini 2.0 flash in this example).
- To test the output, we'll pass the following user query to our HR assistant.
Attaching context source to prompt and testing the output
Here’s what’s happening: For the input, we first query the context source to fetch relevant chunks of information (context). This context is then passed to the LLM in the system prompt (via the {{context}} variable), and the LLM generates a response for our input query using the information in the retrieved context.
To evaluate the performance of our assistant, we'll now create a test dataset. It is a collection of employee queries and corresponding expected responses. We'll use the expected response to evaluate the performance and quality of the response generated by our assistant
Step 2: Create a Dataset
For our example, we’ll use the HR_queries.csv dataset.
- To upload the dataset to Maxim, go to the "Library" section and select "Datasets".
- Click the "+" button and upload a CSV file as a dataset.
- Map the columns in the following manner:
- Set
employee_queryas "Input" type, since these queries will be the input to our HR assistant. - Set
expected_responseas "Expected Output" type, since this is the reference for comparison of generated assistant responses.
- Set
- Click "Add to dataset" and your evaluation dataset is ready to use.
Creating a Dataset on Maxim
Step 3: Evaluating the HR Assistant on Maxim
Now we'll evaluate the performance of our HR assistant and the quality of the generated responses.
- To evaluate the AI assistant, we'll use the following evals available on Maxim. We’ll browse and import these evaluators from Maxim’s Evaluator Store.
| Evaluator | Type | Purpose |
|---|---|---|
| Context Relevance | LLM-as-a-judge | This metric evaluates how well your RAG pipeline's retriever finds information relevant to the input. |
| Faithfulness | LLM-as-a-judge | This metric measures the quality of your RAG pipeline's generator by evaluating whether the output factually aligns with the contents of your context. |
| Context Precision | LLM-as-a-judge | This metric measures your RAG pipeline's retriever accuracy by assessing the relevance of each node in the retrieved context relative to the input, using information from the expected output |
| Bias | LLM-as-a-judge | This metric determines whether output contains gender, racial, political, or geographical bias. |
| Semantic Similarity | Statistical | This metric checks whether the generated output is semantically similar to the expected output. |
| Tone check | Custom eval | This metric determines whether the output has friendly and polite tone |
- Tone check: To check the tone of our HR assistant's responses, we’ll also create a custom LLM-as-a-Judge evaluator on Maxim. We’ll define the following instructions for our judge LLM to evaluate the tone.
Creating a custom LLM-as-a-Judge eval
- Trigger an evaluation:
- Go to the Prompt Playground and click "Test" in the top right corner.
- Select your test dataset (i.e.,
HR_queriesfor our example). - To evaluate the quality of our retrieved context, select the context source you’re using for the AI assistant under "Context to evaluate". (i.e.,
HR_policyin our example). - Select the evaluators and trigger the test run. For each of the employee queries in our dataset, the assistant will fetch the relevant context from the context source and generate a response.
Triggering a test run to evaluate AI HR QnA assistants performance
Step 4: Analyze Evaluation Report
Upon completion of the test run, you’ll see a detailed report of your AI HR assistant's performance across chosen quality metrics (i.e., bias, faithfulness, etc.) and model performance metrics such as latency and cost.
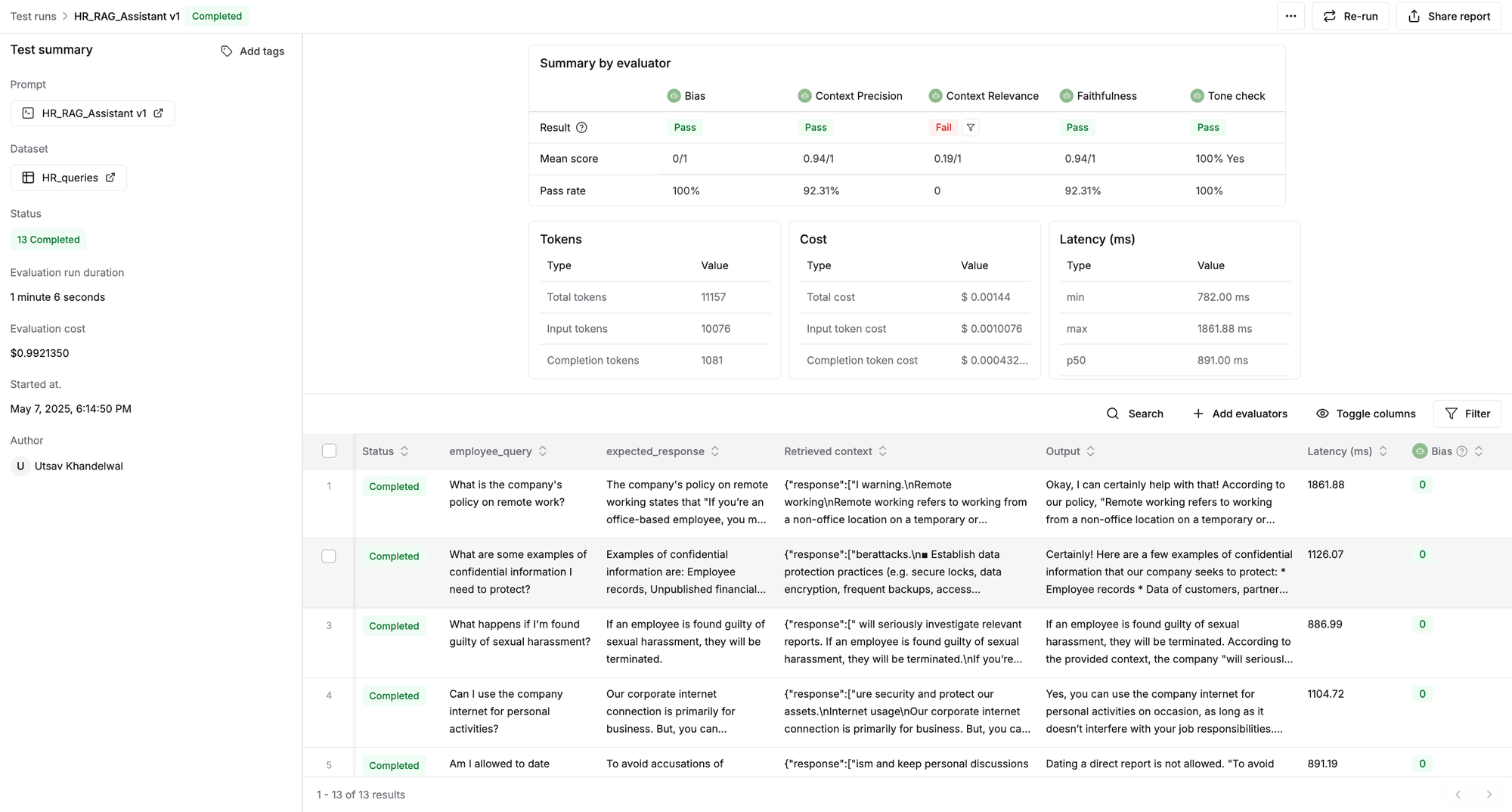
Check out the dynamic evaluation report generated for our assistant. You can click on any row to inspect the input query, the assistant's response, or the evaluator's scores and reasoning.
Few insights from the report:
- The AI HR QnA assistant scored consistently low on the 'Context Relevance' metric, indicating that the retrieved context includes a lot of information that was irrelevant wrt the input. To address this, we can refine our chunking strategy to break down data into more precise chunks to increase indexing accuracy. Additionally, introducing a re-ranking step will allow us to reorder the initially retrieved documents based on their contextual relevance, ensuring that the most pertinent chunks are passed to the LLM.
- The assistant successfully passed the Bias evaluation across all tested queries, confirming that the generated responses do not contain any gender, racial, political, or geographical bias.
Conclusion
AI-powered HR assistants can significantly enhance employee experience and operational efficiency. In this blog, we walked through the process of building and evaluating an internal HR assistant using Maxim’s no-code evaluation suite. From uploading policy documents as context to testing for faithfulness, bias, and retrieval precision, we demonstrated how to systematically assess the quality of an AI assistant’s responses.
As AI continues to transform HR workflows, from resume screening to answering employee queries, rigorous evaluation remains critical to ensure trustworthy and accurate outcomes. Maxim makes it easier than ever to prototype, test, and refine AI systems, helping organizations deploy reliable assistants with speed.