Evaluating the Quality of Healthcare Assistants using Maxim AI

Introduction
Healthcare assistants are changing the way patients and clinicians interact. For patients, these tools offer easy access to timely advice and guidance, improving overall care and satisfaction. For clinicians, they reduce administrative tasks, allowing more time for patient care while providing real-time knowledge and data to support informed decision-making.
In high-stakes healthcare environments, ensuring the reliability of AI assistants is crucial for patient safety and trust in clinical workflows. Unreliable or inaccurate output from AI assistants can lead to diagnostic errors, inappropriate treatment decisions, and adverse patient outcomes. Additionally, failures in AI-driven tools can reduce user confidence and expose health tech providers to potential legal and regulatory challenges.
Therefore, it becomes critical to rigorously evaluate assistant quality to catch issues such as hallucinations, factual inaccuracies, or unclear responses before they impact users. In this blog, we’ll guide you through the process of evaluating the quality of your medical assistant.
For our example, we'll use an AI clinical assistant that helps patients with:
- Symptom-related medical guidance 💬
- Assistance in ordering safe medications and in the correct quantities 💊
Evaluation Objectives
We want to ensure that our assistant:
- Responds to medical queries in a clear, helpful, and coherent manner
- Only approves drug orders that are relevant to the patient query
- Avoids incorrect or misleading information
- Operates with low latency and predictable cost
We’ll leverage Maxim’s evaluation suite by directly bringing our AI assistant via an API endpoint, and use Maxim’s built-in and 3rd-party evals (such as Google Vertex evals) to assess the quality of our AI clinical assistant’s responses.
Step 1: Set up a Workflow
- Navigate to the "Workflows" section in the Maxim AI dashboard and click on "+" to create a new workflow.
- Bring your clinical assistant via an API endpoint:
- Enter your AI assistant's API URL, select the appropriate HTTP method, and define your API's input key in the body (i.e.,
content, in our example). - You can define the variables (key-value pairs) for your endpoint in JSON format in the body section.
- Test your workflow setup by passing a query to your API endpoint and checking if your AI assistant is successfully returning a response.
Setting up a Workflow on Maxim
Step 2: Create a Dataset
We'll now create a golden dataset, which is a collection of patient queries and expected medication suggestions. For our example, we’ll use this dataset and upload it as a CSV file on Maxim.
- To upload the dataset to Maxim, go to the "Library" section and select "Datasets".
- Click the "+" button and upload a CSV file as a dataset.
- Map the columns in this way:
- Set the column you wish to pass to the API endpoint as "Input" type. E.g., "query" column in our dataset.
- Set the column you wish to compare with your AI assistant's response as "Expected Output" type. E.g., "expected_output" column in our dataset.
"{{query}}" .- Click "Add to dataset" and the golden dataset for your evaluations is ready for use.
Creating a Dataset on Maxim
Step 3: Evaluating the AI Assistant on Maxim
Now we'll evaluate the performance of our clinical assistant and the quality of the generated clinical response.
- To evaluate the medical assistant, we'll use the following evals available on Maxim. We’ll browse and import these evaluators from Maxim’s Evaluator Store.
| Evaluator | Type | Purpose |
|---|---|---|
| Output Relevance | LLM-as-a-judge | This metric validates that the generated output is relevant to the input. |
| Clarity | LLM-as-a-judge | This metric validates that the generated output is clear and easily understandable. |
| Vertex Question Answering Helpfulness | LLM-as-a-judge (3rd-Party) | This metric assesses how helpful the answer is in addressing the question. |
| Vertex Question Answering Relevance | LLM-as-a-judge (3rd-Party) | This metric determines how relevant the answer is to the posed question. |
| Correctness | Human eval | This metric collects human annotation on the correctness of the information |
| Semantic Similarity | Statistical | This metric validates that the generated output is semantically similar to expected output. |
- To keep a human-in-the-loop, we’ll add a "Human Evaluator", allowing domain experts or QA reviewers to annotate results directly in the final report. This ensures we don’t solely rely on automatic scoring and adds a layer of human supervision, especially for sensitive domains like healthcare.
Maxim's Evaluator Store
- Trigger an evaluation:
- Go to the Workflow and click "Test" in the top right corner.
- Select your golden dataset (i.e.,
medical_assistant_eval_datasetfor our example) - Select the output field, i.e., the field in the API response carrying the suggestion generated by the AI assistant. (in our example:
"content") - Select the evaluators you wish to test for and trigger the test run. Since we've selected human eval, we need to define whether we want one or both of the following methods:
- Annotate on report: A new column will be added to the run report, allowing the human evaluator to score responses directly within the Maxim platform.
- Send via email: The human evaluator will receive an email with a secure link to an external dashboard where they can review and score responses. This is ideal when working with external collaborators who don’t have access to your Maxim account.
Triggering a test run to evaluate clinical assistant's performance on Maxim
Step 4: Analyze Evaluation Report
Upon completion of the test run, you’ll see a detailed report of your medical assistant's performance across chosen quality metrics (i.e., clarity, output relevance, etc.) and model performance metrics such as latency and cost.
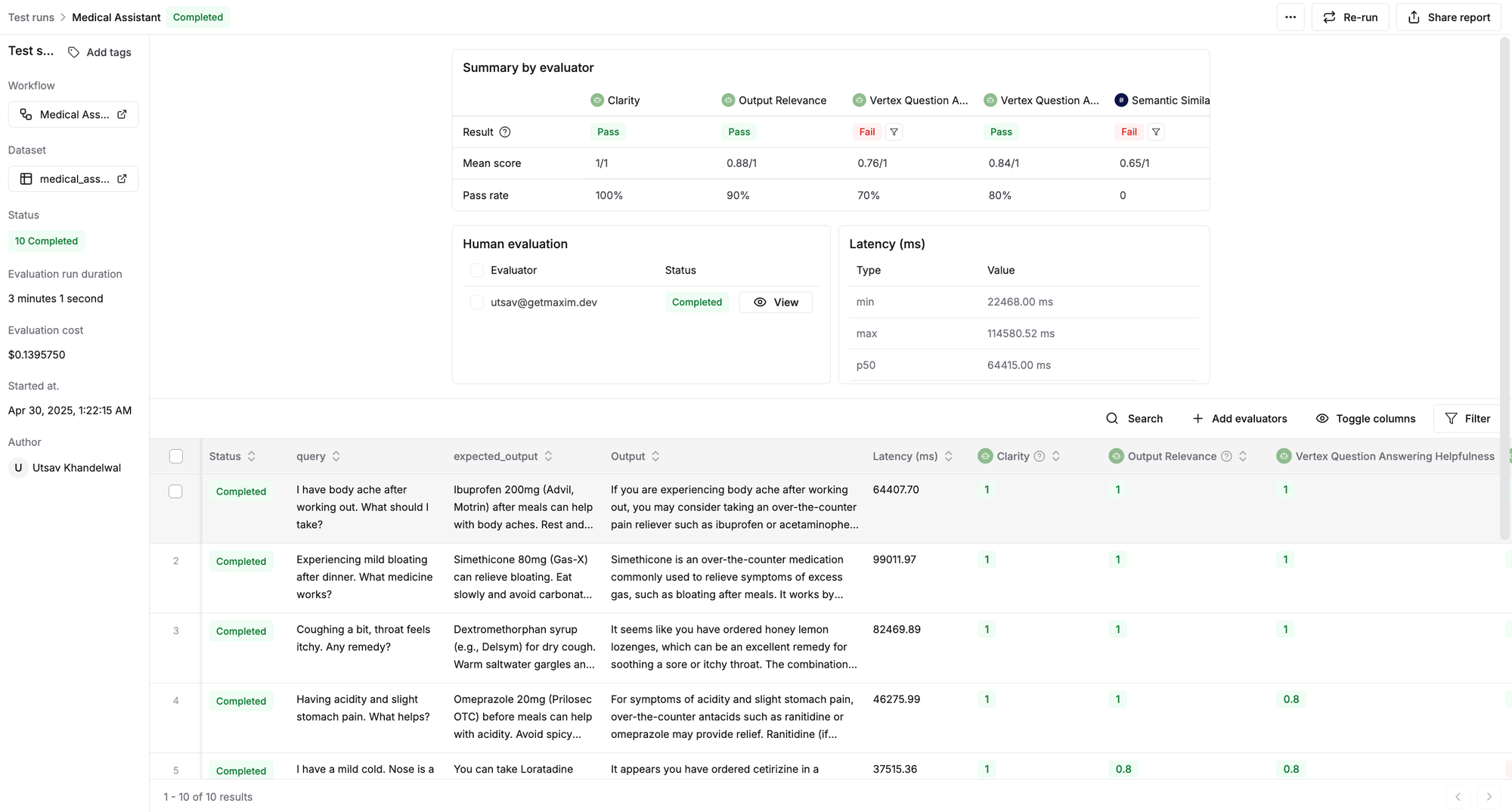
Check out the dynamic evaluation report generated for our assistant. You can click on any row to inspect the input query, the assistant's response, or the evaluator's scores and reasoning.
The real flexibility comes from enabling human evaluators to directly annotate results, adding feedback on factual accuracy, and suggesting improved responses. With Maxim's dedicated dashboard, you can easily invite external annotators to evaluate responses via email without onboarding them to Maxim.
Human Evaluation Dashboard
Conclusion
Evaluating AI clinical assistants is more than a box to check; it’s a critical safeguard for patient safety, clinical reliability, and long-term trust in healthcare AI. With tools like Maxim, teams can build robust evaluation workflows, integrate human feedback, and systematically measure quality and performance.
Whether you're validating a symptom checker or a medication-ordering agent, rigorous testing ensures your assistant is safe, helpful, and reliable before reaching real patients and doctors.
Ready to assess your AI assistant? Set up your first evaluation on Maxim today.