DSPy framework

DSPy is a declarative, self-improving framework for LLMs designed to streamline pipelines and aid broader LLM application development processes. The framework allows developers to define tasks and workflows in a high-level, declarative manner using their API. This process simplifies the need to specify “what needs to be done?” rather than detailing “how to do it?”.
DSPy’s key feature is its ability to self-improve prompts. This means that over time, the framework can refine and improve the prompts used by LLMs to process queries based on performance feedback, leading to better results without explicit finetuning. Let us now examine the essential building blocks that facilitate the process.
Building blocks
First mentioned in the research paper “DSPY,” the framework promises to be able to wrap the entire process of optimizing pipelines in a high-level language.

The framework is built on multiple building blocks, which seamlessly work together to create a powerful yet flexible system to manage LLM pipelines better. Here are some of the primary building blocks of DSPy:
- Language models: The framework includes various models attached to API calls from big providers such as OpenAI, Llama, and Claude Models.
- Signatures: This block manages the inputs and outputs of the tasks, ensuring data integrity.
- Modules: These are reusable blocks that encapsulate specific functions or tasks.
- Data: This holds various methods for storing and retrieving data for tasks.
- Metrics: Provides feedback for optimizing and improving the pipeline over time.
- Optimizers: focus on optimizing prompts passed to the model, ensuring they are the best possible query versions.
- DSPy assertions: Validate the behavior of components, ensuring smooth usage.
- Typed predictors: Ensure predictions adhere to specifications and have a consistent output accuracy.
Now, barring Language Models, Data, Assertions, and Predictions, which can be brought in from an external source, DSPy’s framework shines among the rest with its Signatures, Modules, Metrics, and Optimizer.
DSPy signatures
DSPy Signatures are declarative specifications that define the input/output behavior of a certain DSPy Module. Signatures enable users to skip the jargon and quickly and effectively control how models interact with language models. They provide pre-defined structures and context, helping query handling. These signatures can be called upon statements such as:
classify = dspy.Predict('question -> answer')
summarize = dspy.ChainOfThought('document -> summary')
Where input->output is a direct in-line implementation of DSPy signatures.
DSPy modules
DSPy modules represent distinct components that contain specific functions, processes, or sub-tasks. Each module is reusable and greatly helps in agentic workflows and RAGs by managing tasks such as handling memory, interaction with external applications, or even managing dialogue flow. Some Modules that come with DSPy are:
- dspy.predict(): handle predictive tasks without explicit complex logic
- dspy.ChainOfThought: gives the agent a systematic, structured thought process
- dspy.ReAct: enables the model to reason and interact with external tools to influence outputs.
A sample implementation of dspy.Modules can be seen as follows:
import dspy
# Define a simple signature for question answering with tool usage
class BasicQA(dspy.Signature):
"""Answer questions using external tools."""
question = dspy.InputField()
answer = dspy.OutputField(desc="A detailed answer based on tool usage")
# Simulate a web search tool function (in reality, this would call an actual API)
def web_search_tool(query):
# Simulated response from a web search API (replace this with actual API call)
if "current president of the United States" in query:
return "The current president of the United States is Joe Biden."
else:
return "No relevant information found."
# Pass signature and tool function to ReAct Module
react_module = dspy.ReAct(BasicQA, tools={'web_search': web_search_tool})
# Define an input value for a question
question = 'Who is the current president of the United States?'
# Call React module on particular input
result = react_module(question=question)
print(f"Question: {question}")
print(f"Final Predicted Answer (after React process): {result.answer}")
Assuming the code works, the output should look something like this:
Question: Who is current president of United States?
Final Predicted Answer (after React process): The current President of US is Joe Biden.
DSPy metrics
DSPy Metrics are a highly thoughtful component of DSPy, which lets users measure and improve a model’s performance, particularly in complex tasks such as long-form generation and multi-step reasoning. Metrics allow users to do several evaluations of the model performance:
- Dspy.evaluate.metrics.answer_exact_match: To immediately check if answers are matching across the samples.
- Dspy.evaluate.metrics.answer_passage_match: Compare arrays of data at the same time.
- Trace: To trace Language Model Calls during optimization or deployment.
One rather interesting application of the DSPy metric is the ability to employ an AI for feedback as a metric. This can be done by creating a signature called Assess and then calling upon the assessing language model using the DSPy.predict function.
# Define the signature for automatic assessments.
class Assess(dspy.Signature):
"""Assess the quality of a tweet along the specified dimension."""
assessed_text = dspy.InputField()
assessment_question = dspy.InputField()
assessment_answer = dspy.OutputField(desc="Yes or No")
gpt4T = dspy.OpenAI(model='gpt-4-1106-preview', max_tokens=1000, model_type='chat')
def metric(gold, pred, trace=None):
question, answer, tweet = gold.question, gold.answer, pred.output
engaging = "Does the assessed text make for a self-contained, engaging tweet?"
correct = f"The text should answer `{question}` with `{answer}`. Does the assessed text contain this answer?"
with dspy.context(lm=gpt4T):
correct = dspy.Predict(Assess)(assessed_text=tweet, assessment_question=correct)
engaging = dspy.Predict(Assess)(assessed_text=tweet, assessment_question=engaging)
correct, engaging = [m.assessment_answer.lower() == 'yes' for m in [correct, engaging]]
score = (correct + engaging) if correct and (len(tweet) <= 280) else 0
if trace is not None: return score >= 2
return score / 2.0
DSPy optimizers
DSPy optimizers are tools that improve model performance by tuning different critical parameters such as prompts, instructions, and weights for the language model. Optimizers provide a way to streamline iterative processes such as creating prompts, instruction generation, and multi-hop reasoning, which are essential parts of agentic workflows.
Here is a holistic overview of all the major optimizers in DSPy:
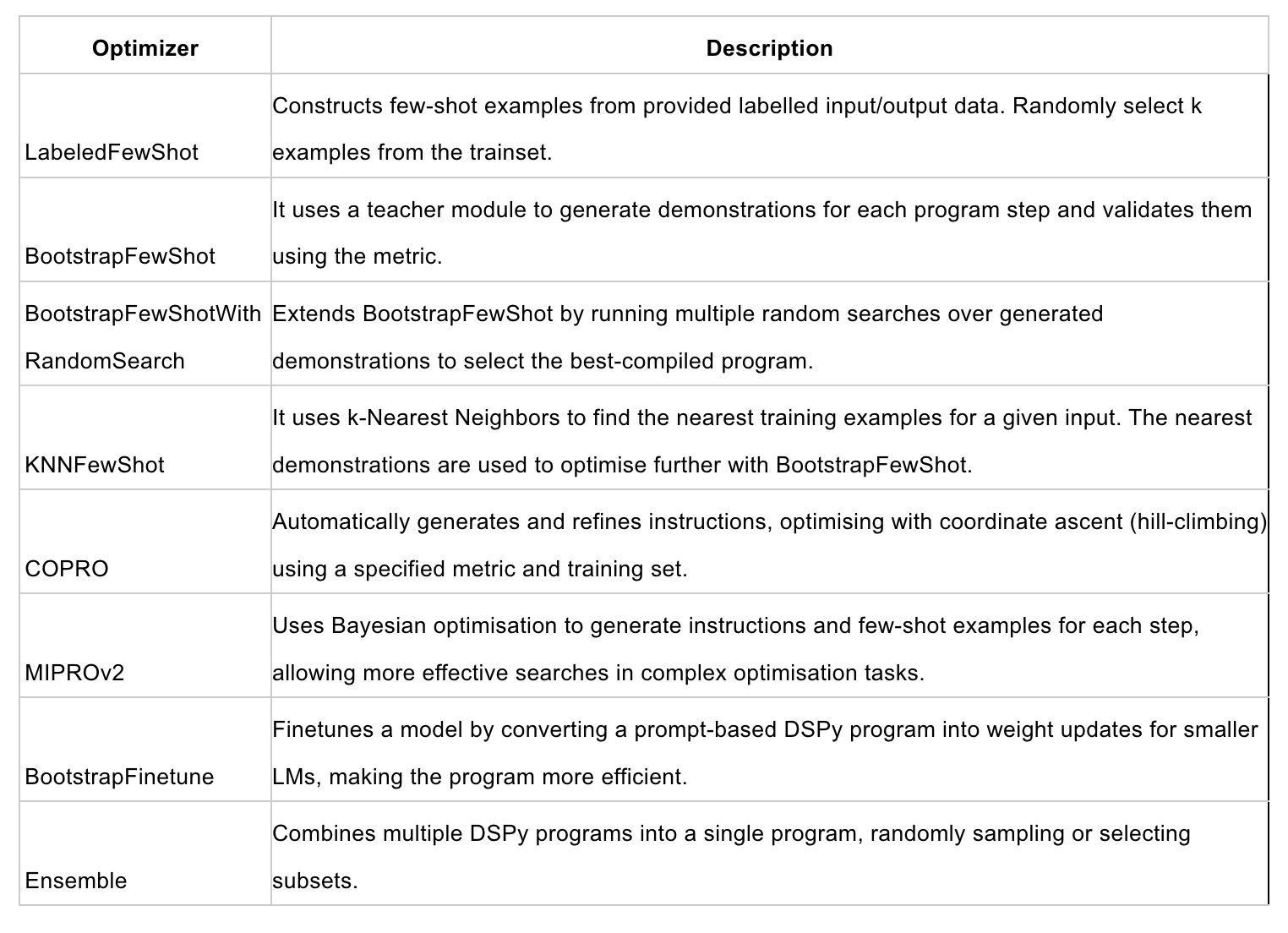
To check out optimizers in action, let us take an example of FewShotWithRandomSearch optimizer to improve the performance of a DSPy program:
from dspy.teleprompt import BootstrapFewShotWithRandomSearch
# Configuration for the optimizer: we bootstrap 8-shot examples for program steps, repeated 10 times with random searches.
config = dict(
max_bootstrapped_demos=4,
max_labeled_demos=4,
num_candidate_programs=10,
num_threads=4
)
# Initialize the optimizer with a custom metric
teleprompter = BootstrapFewShotWithRandomSearch(metric=YOUR_METRIC_HERE, **config)
# Compile the program using the optimizer on a given trainset
optimized_program = teleprompter.compile(YOUR_PROGRAM_HERE, trainset=YOUR_TRAINSET_HERE)
# Save the optimized program for future use
optimized_program.save("path_to_save_optimized_program.json")
Some examples of DSPy
With continuous community support, DSPy has been able to showcase its capabilities through different stress tests, which range in different aspects of LLM applications such as Research Papers, Open-Source Software, and Providers that support framework building through their documentation. Some such examples are:
To understand the model’s use case and performance better, let us take a page out of the official DSPy Research Paper that highlights the framework’s performance on GPT-3.5 and Llama 2-13B for MultiHop QA on the HotPotQA dataset.
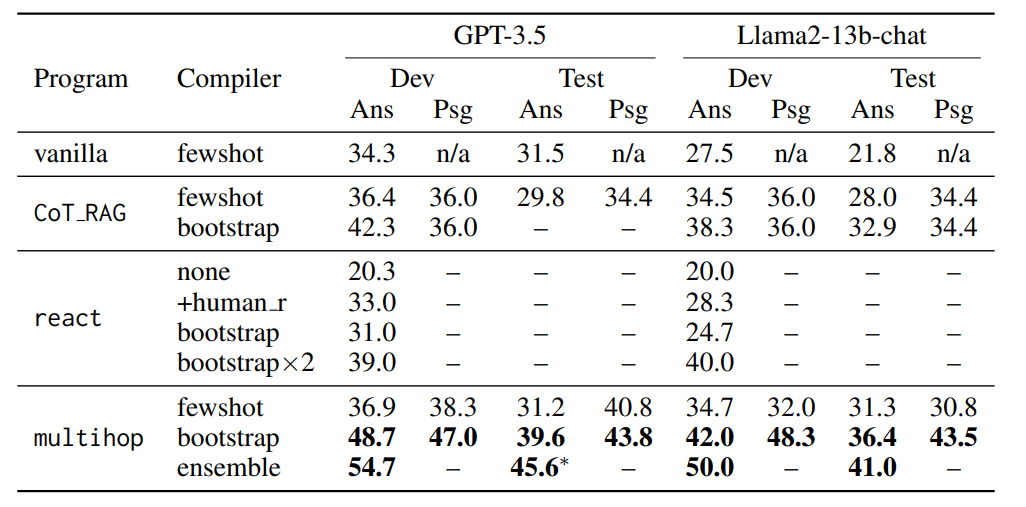
The training set comprised "hard" examples, with a sample size of 200 for training and 300 for validation. The results showed that a simple multi-hop program achieved an answer exact match (EM) rate of 54.7% on the test set, significantly outperforming the vanilla few-shot prompting baseline, which had an EM rate of only 31.5% for GPT-3.5 and 21.8% for Llama2-13b-chat. The multi-hop framework's iterative query generation across passages was key to synthesizing relevant information, leading to an EM improvement from 42.3% (bootstrap) to 48.7% (multi-hop with bootstrap).
Conclusion
Here, we explored DSPy, an emerging framework designed to optimize large language model (LLM) pipelines. DSPy simplifies the often complex and repetitive aspects of working with LLMs by wrapping these processes into concise, declarative code that can be instantly executed. Instead of getting bogged down by low-level code, developers can leverage DSPy to build and manage efficient pipelines with minimal effort, making it a powerful tool for streamlining workflows and reducing redundancy in LLM operations.
We also highlighted features that make DSPy particularly well-suited for AI agents and similar applications. Its modular design allows for easy integration of validation logic, optimization metrics, and compilation processes, enabling AI agents to function more efficiently. By allowing developers to adjust performance parameters without rewriting code quickly, DSPy facilitates rapid iteration and adaptability, key elements for deploying more intelligent, faster AI-driven systems.
Further reading
DSPY: COMPILING DECLARATIVE LANGUAGE MODEL CALLS INTO SELF-IMPROVING PIPELINES
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your RAG performance with Maxim.