Contextual document embeddings

Introduction
Retrieval is a complex task due to the diversity of queries and the importance of the relevance of the text being retrieved. There are primarily statistical-based retrieval and neural-based retrieval techniques. The paper we will be discussing today works on improving document embeddings for neural retrieval tasks. Traditional methods of generating document embeddings involve encoding documents individually, which can result in embeddings that do not fully capture the context in which a document appears. Often, these embeddings are out-of-context for specific retrieval tasks. Thus, this paper highlights the importance of considering the context provided by neighboring documents to create more accurate and useful document embeddings in retrieval scenarios where context is important.
Method
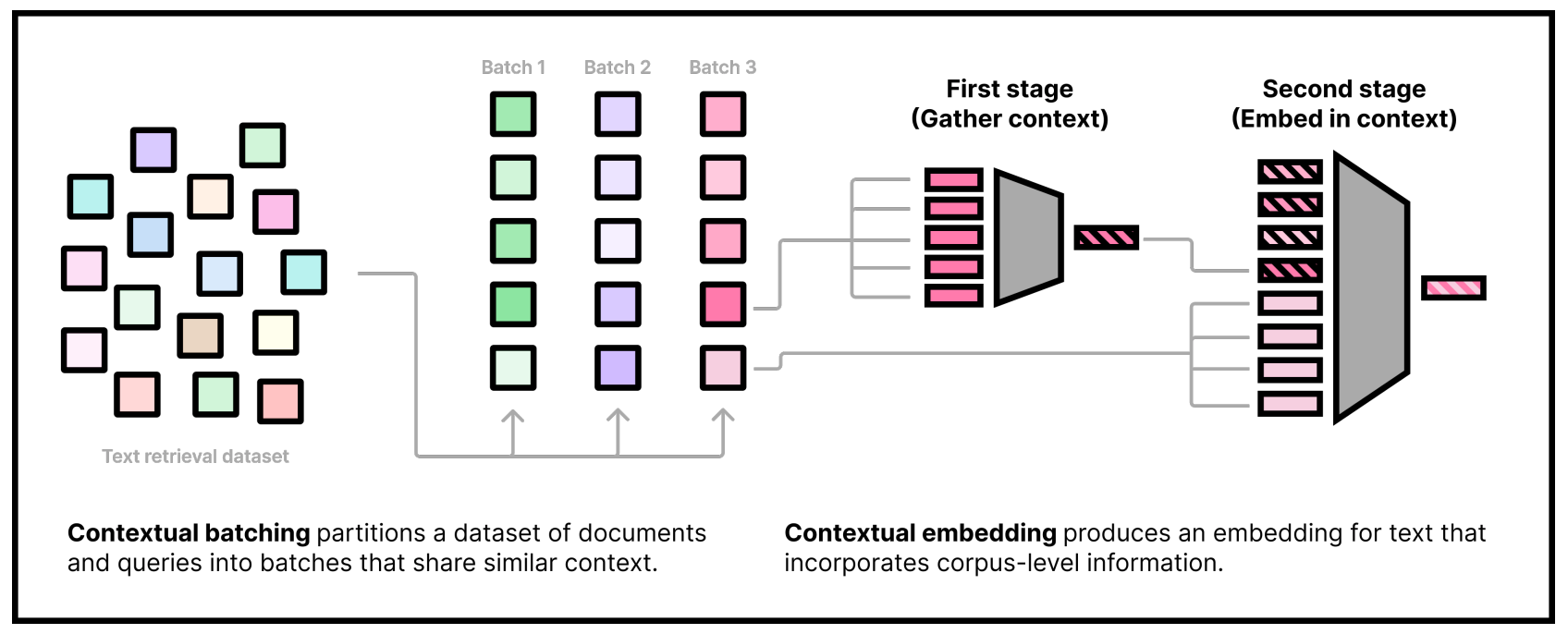
The work deals with integrating contextual information in the embedding functions such that it performs retrievals well when the test document is in a different domain compared to the trained set. The authors introduce two main methods to achieve contextual document embeddings:
- Adversarial contrastive learning objective:
- This method modifies the traditional contrastive learning objective to include neighboring documents in the loss function. By incorporating intra-batch contextual loss, the embeddings are trained to recognize and utilize the context provided by neighboring documents.
- The approach involves a contrastive loss that explicitly considers the relationships between a document and its neighbors within the same batch, promoting the learning of contextual information.
- Contextual document embedding architecture (CDE):
- The second method involves developing a new neural network architecture that explicitly encodes information from neighboring documents into the document's embedding.
- It consists of two bidirectional transformers, encoders called in sequence in the two stages:
- Firstly, all the documents are gathered, embedded using a unique embedding model, transformers and concatenated into a sequence.
- Secondly, integrate the contextual embedding sequence at the input of the second stage embedding model.
- This architecture ensures that the embeddings inherently capture contextual information, as it processes not just the target document but also its surrounding documents during the encoding phase.
Experiments
For training data, they train on meta-datasets collected in Nomic Embed which includes data from 24 datasets scraped from web sources like Wikipedia and Reddit. For supervised training, they use 1.8 human-written query-document pairs for text retrieval aggregated from popular datasets like HotpotQA and MS Marco. For metrics, they used NDCG@10, a conventional retrieval metric enabling comparison across disparate datasets.
For benchmarking, performance was measured using the Massive Text Embedding Benchmark (MTEB), which is a comprehensive benchmark for evaluating text embeddings. The experiments focused on out-of-domain tasks to demonstrate the robustness of the proposed methods.
Results
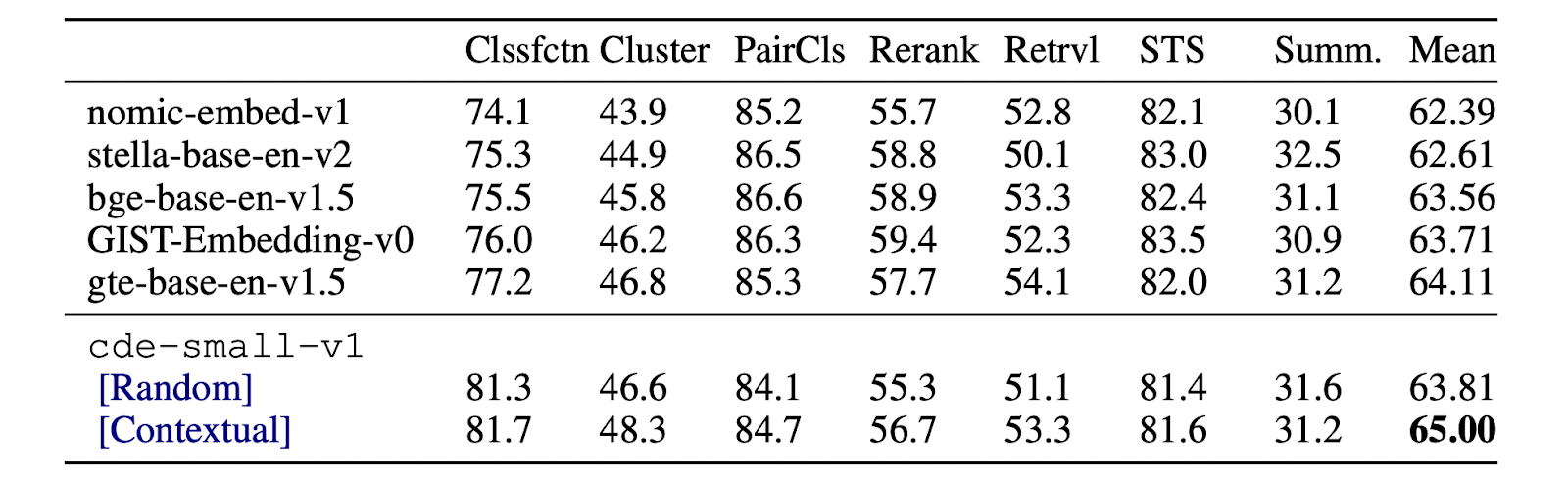
The experimental results highlighted that the proposed methods outperformed traditional Biencoder approaches across multiple benchmarks. The improvements were particularly notable in out-of-domain settings, where contextual information is crucial for accurate retrieval. The contextual document embeddings achieved state-of-the-art results on the MTEB and BEIR benchmarks without relying on complex techniques such as hard negative mining, score distillation, or extremely large batch sizes.
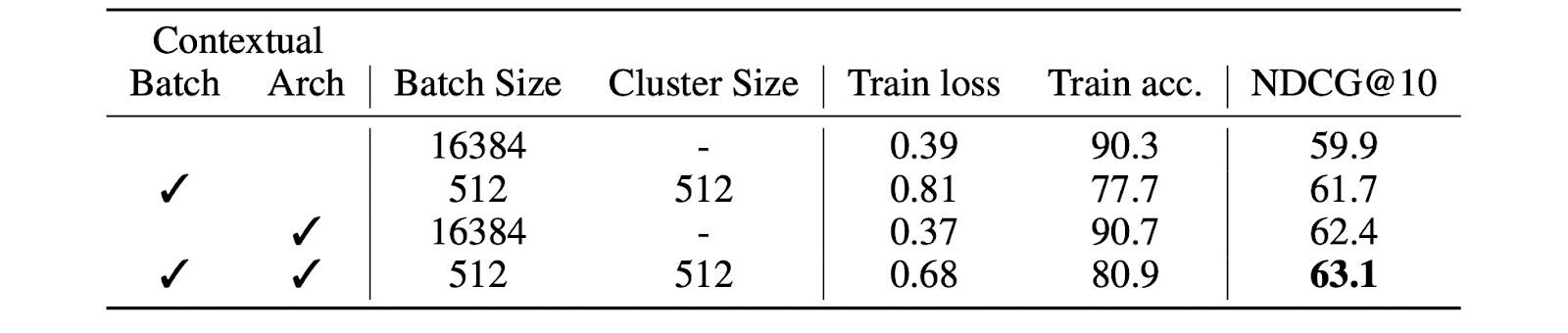
Besides the improvements, the methods can be easily applied to any contrastive learning dataset and can improve the performance of existing Biencoders without requiring significant modifications or computational resources.
Conclusion
As demonstrated, the proposed method of incorporating context into document embeddings significantly enhances the performance of neural retrieval tasks. CDE provides a simple yet effective approach to generating contextual document embeddings. These methods can be integrated into existing contrastive learning frameworks, improving performance across various applications. The paper shows that contextual information from neighboring documents can be leveraged to create superior document representations, paving the way for more accurate and efficient retrieval systems.
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your Gen AI application's performance with Maxim.