Computation Beyond Tool Use: Executing Programs Inside a Transformer

When LLMs need to compute something reliably, we've settled into a familiar pattern: the model writes code, an external interpreter runs it, the result gets injected back into the context, and the model carries on. It works well enough that we rarely stop to question the architecture. But tool use doesn't make the model a better executor. It makes the model a better coordinator of systems that do execution for it. The capability still lives outside. And when something goes wrong mid-execution, the model has no visibility into why, because it never actually ran the steps.
The reason we settled here is real though. Every transformer forward pass does two things at each layer: attention retrieves relevant state from past tokens, and the MLP transforms whatever was retrieved into the next representation. That architecture is powerful but fundamentally approximate. A single wrong intermediate token in a long computation cascades into a completely wrong answer, with no correction mechanism. The natural question is: what if the model didn't hand off at all? What if it just ran the program itself? But that idea runs into two problems immediately: the model approximates rather than computes exactly, and attending over long execution traces is quadratically expensive. Percepta decided to take both problems seriously : they trained a small vanilla transformer whose weights encode a complete WebAssembly interpreter, and solved both problems. The model doesn't call an external tool. It executes programs inside its own decoding loop, deterministically, for millions of steps. And the key to making that fast enough to matter turns out to be a geometric insight about 2D attention vectors.
Why tool use became the default
Let's be clear: tool use works. The pattern of writing code, executing it externally, and reading back the result measurably improves performance on math and reasoning benchmarks. Production systems built on tool-integrated reasoning are reliable. Failures are rare. For the vast majority of what we ask these systems to do today, delegating execution outward is the right call and it's not going away.
But there's a useful analogy here from the Percepta post itself. Humans can't fly. Building airplanes doesn't change that. It just means we built machines that fly for us. Tool use is exactly this: we built machines that compute for us. Useful, obviously. But the model itself still can't compute. It can describe an algorithm, reason about it, orchestrate tools that run it. It just can't execute the steps itself.
That distinction matters more than it sounds. The result of tool use comes back to the model as a black box. The model never sees the intermediate state, so if something fails mid-execution it has no visibility into what went wrong(expect for the error messages) More fundamentally, the external interpreter is non-differentiable. You can't backpropagate through it, which means the execution component can never be trained end to end alongside the reasoning component. The boundary between "the model" and "the systems it calls" is hard-wired into the architecture.
The non-determinism problem also doesn't fully disappear. When you're doing complex multi-step reasoning and calling tools at each step, the model is still making decisions under uncertainty about what to compute next. A wrong reasoning step (not just a wrong calculation, the model deciding wrongly what to compute) cascades just as badly. Offloading arithmetic is useful but it doesn't make the overall system reliable over very long horizons.
This is what makes the Percepta direction genuinely interesting as a research area, not as a replacement for what works today, but as an exploration of what becomes possible when the model itself becomes the computer.
The structural problem with long execution traces
Here's the constraint that makes in-model execution hard. Standard autoregressive decoding means the t’th token generation attends over a KV cache of size t. KV caching avoids recomputing past projections but it doesn't remove the linear scan: at every step, your query still scores against all t cached keys to figure out what to attend to. Work per step grows as O(t), total cost across t steps grows as O(t²).
For a program that runs a few hundred steps this is fine. For a program that needs millions of execution steps (think a constraint solver backtracking through a hard Sudoku, or running the Hungarian algorithm on a large cost matrix) it's a hard wall. The computation becomes impractical before you get anywhere interesting, which is the deeper reason exact long-horizon execution got delegated outward. Not just approximation errors, but raw cost.
What the interpreter actually looks like
The model uses standard PyTorch with nn.MultiheadAttention, a gated feedforward network, nothing custom. The architecture is completely vanilla. d_model=36, n_heads=18, n_layers=7. What makes it special is entirely in the weights.
When the model encounters a computation it needs to run, it emits a WebAssembly program. WebAssembly is a good target here: it's a low-level instruction set that C compiles to cleanly, with deterministic semantics and instructions that map to at most 5 tokens each. The model then switches into execution mode and runs the program itself, token by token, producing a trace that looks like a simple addition:
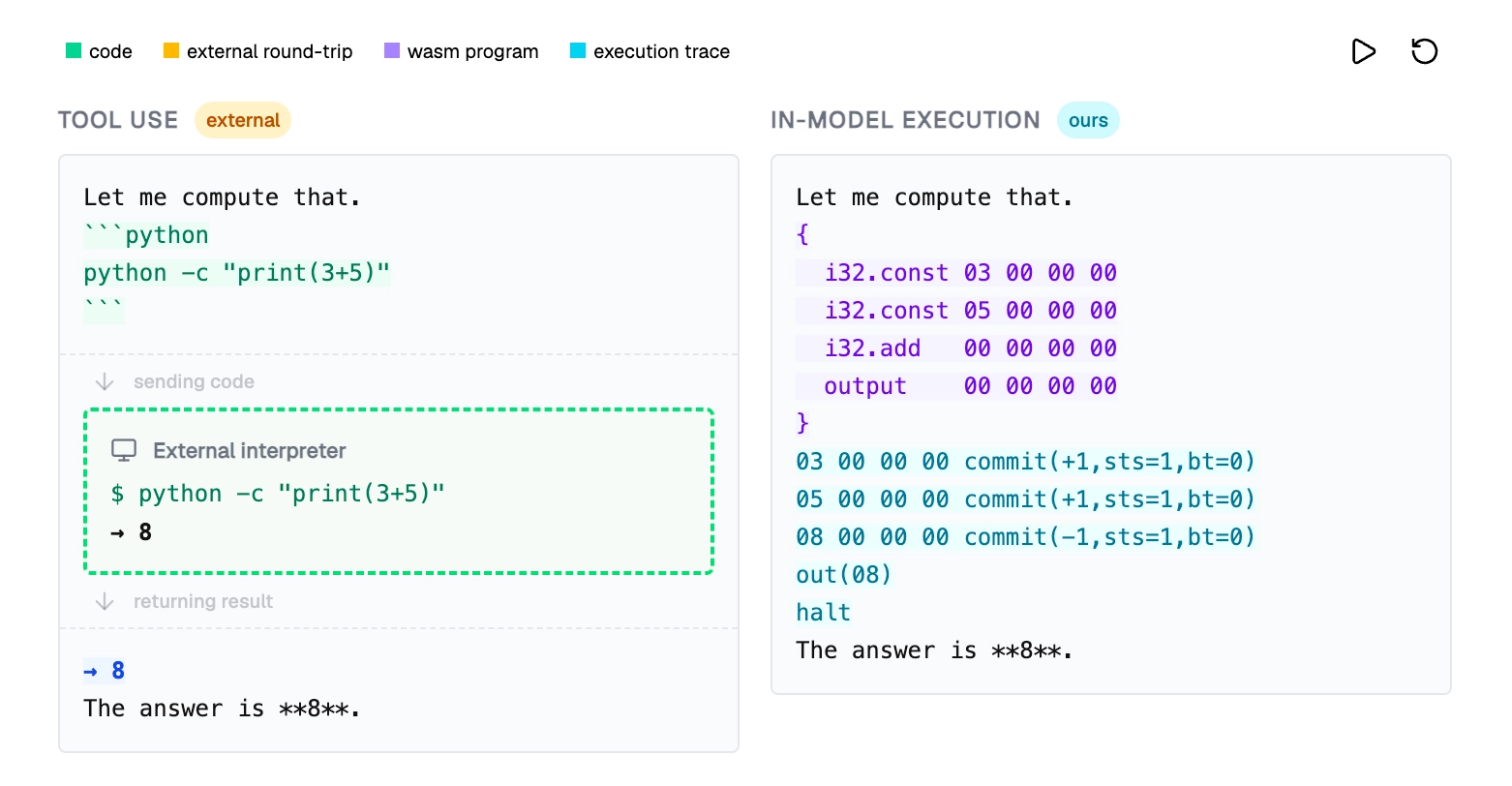
The attention heads are doing the retrieval work at each step: when the model hits an i32.add instruction, the attention pattern looks back through the trace to find the two values on top of the stack. The MLP does the local transformation: given those retrieved values, produce the correct next token. Both components together implement interpreter behavior. Deterministically, step by step, for as long as the program runs.
The key unlock: 2D heads and convex hull attention
This is where the performance problem gets solved : Standard attention as we know, works like this - you have a query vector q at the current step, and a key vector kj for every past position j. You compute the dot product q·kj for all j, apply softmax, and use the resulting weights to aggregate values. Retrieval cost is O(t) because you're scoring against every key.
The question Percepta asked: is there a special case where you can do this much faster? The answer is yes, when head dimension is 2. Here's why. If your keys and queries are 2D vectors, then the attention operation (specifically hard-max attention: find the single key that maximizes the dot product with the query) becomes a geometric problem. You have a set of 2D points (your past keys), and a query direction q. You want the point that is furthest in the direction of q. That's a classical problem in computational geometry called a "supporting point" query.
The key insight is that you don't need to check all t points to answer this. The point that maximizes the dot product with any direction is always on the convex hull of the point set. Think of the convex hull as the outer boundary you'd get if you wrapped a rubber band around all your key vectors plotted as 2D points. Only the points on that outer boundary can ever be the maximum in any direction. Everything interior is irrelevant. So instead of scanning all t past keys, you maintain a convex hull as tokens are generated, and answer each query by searching only the hull. Binary search on a convex hull takes O(log t). That drops the per-step cost from O(t) to O(log t), and total cost across t steps from O(t²) to O(t log t).
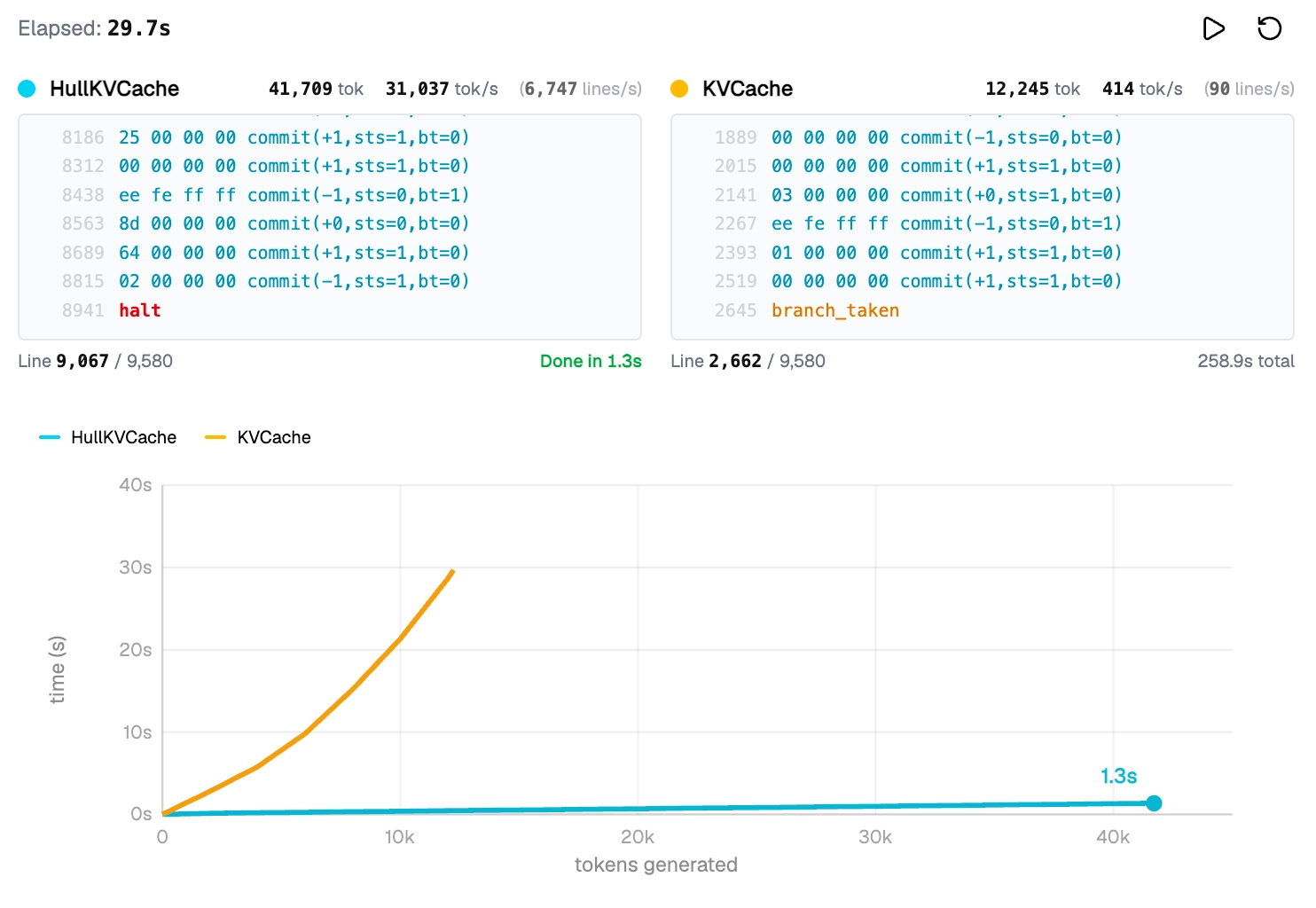
The performance difference in practice: 1.3 seconds versus 258 seconds for the same workload. Same token count, same program, standard KV cache vs. their HullKVCache. The obvious concern: does restricting head dimension to 2 fundamentally limit what the model can represent? The answer is no for the purposes of this construction. You can still have arbitrarily many heads (n_heads = d_model / 2, so a larger model just uses more heads), arbitrarily many layers, and arbitrarily large embeddings. The restriction is only on per-head dimension. And the theoretical result holds: 2D attention is sufficient for Turing completeness. You can represent a full RAM computer with it.
For softmax attention rather than hard-max, the same geometric machinery extends naturally. Maintain nested convex hulls, retrieve the top-k highest-scoring keys using hull queries, compute softmax over those k keys. Cost becomes O(k + log t). As long as k stays small, this remains practical.
What's still unresolved
The honest version of this result has clear boundaries. The model demonstrated here is a standalone executor, not integrated with a large reasoning model. The path toward a hybrid where a large LLM plans and delegates to this fast execution substrate is described but not built yet.
The 2D head restriction also hasn't been stress-tested at scale. It's flexible enough to capture complex logic and Turing completeness holds, but whether a model trained at GPT-scale with 2D heads retains full general capability is an open question. The speedup also shows up most visibly on deterministic mechanical traces: exact copying, state machine stepping, structured lookups. Those are exactly the cases where it matters for an executor, but it's worth being precise that this isn't a general-purpose attention speedup for arbitrary workloads.
The differentiability angle is the most interesting open direction. Because the execution trace is part of the forward pass, gradients can propagate through the computation. That means a combined reasoning-plus-executor system could potentially be trained end to end, with the execution component learning to run programs more accurately alongside a reasoning component learning to generate better programs. That would be a genuinely different thing from anything we have today.
Conclusion
The core problem with in-model computation has always been two-layered: LLMs approximate rather than compute exactly, and attending over long execution traces is quadratically expensive. Percepta addresses both. A transformer whose weights encode a deterministic interpreter solves the approximation problem. Restricting attention heads to 2D, which reduces key retrieval to a convex hull query, solves the scaling problem.
Tool use works, and it'll keep working. But it's a workaround for a fundamental limitation, not a solution to it. What this research explores is whether the model itself can become the computer, not by calling better tools, but by executing programs inside its own weights. Whether that scales to hybrid systems that reason and compute inside the same architecture is the right question to be asking now, and one worth exploring further. But as a research direction, this is about as fascinating as it gets.
For the full technical details : Can LLMs Be Computers?


