Claude 3.5 Sonnet put to the test

Since Anthropic released “Claude 3.5 Sonnet,” it has been all the rage on social media. Anthropic has claimed that it outperforms leading industry models, including its previous flagship, Claude 3 Opus model. It’s 2x faster and 5x cheaper than Claude 3 Opus.
It is also available via the Anthropic API, Amazon Bedrock, and Google Cloud’s Vertex AI. The model costs $3 per million input tokens and $15 per million output tokens, with a 200K token context window more than GPT-4o's 128K.
This performance boost and the cost-effective pricing make the Claude 3.5 Sonnet perfect for complex tasks like mathematical reasoning and managing multi-step workflows.
Anthropic says that Claude 3.5 Sonnet achieved impressive results in reasoning and coding and is very good at writing high-quality content with a natural, relatable tone.
We wanted to put the models to the test on two key dimensions:
- Performance Comparision
- Latency
- Throughput
- Cost and Context
- Quality Comparision
- standard benchmark published
- Reported benchmarks
- ELO Rating
- internal benchmark on different niche tasks
- Mathematical abilities: Testing on solving algebraic equations up to undergrad level
- Classification and language reasoning: Natural Language Inference
- Long Context inference: Doing the famous needle in a haystack test
- standard benchmark published
Performance Comparision
In this part of the analysis, let's focus on the performance metrics claude-3-5-sonnet and the GPT-4o Model.
For performance, we will look at the following set of metrics:
- Latency and Throughput comparing
claude-3-5-sonnetandGPT-4o - Cost comparing
claude-3-5-sonnetandGPT-4o
Latency: Comparing Claude 3.5 Sonnet and GPT
Claude 3.5 Sonnet is twice as fast as Claude 3 Opus, offering significantly improved processing speeds and response times. However, despite this advancement, Claude 3.5 Sonnet still falls short compared to GPT-4o regarding latency.
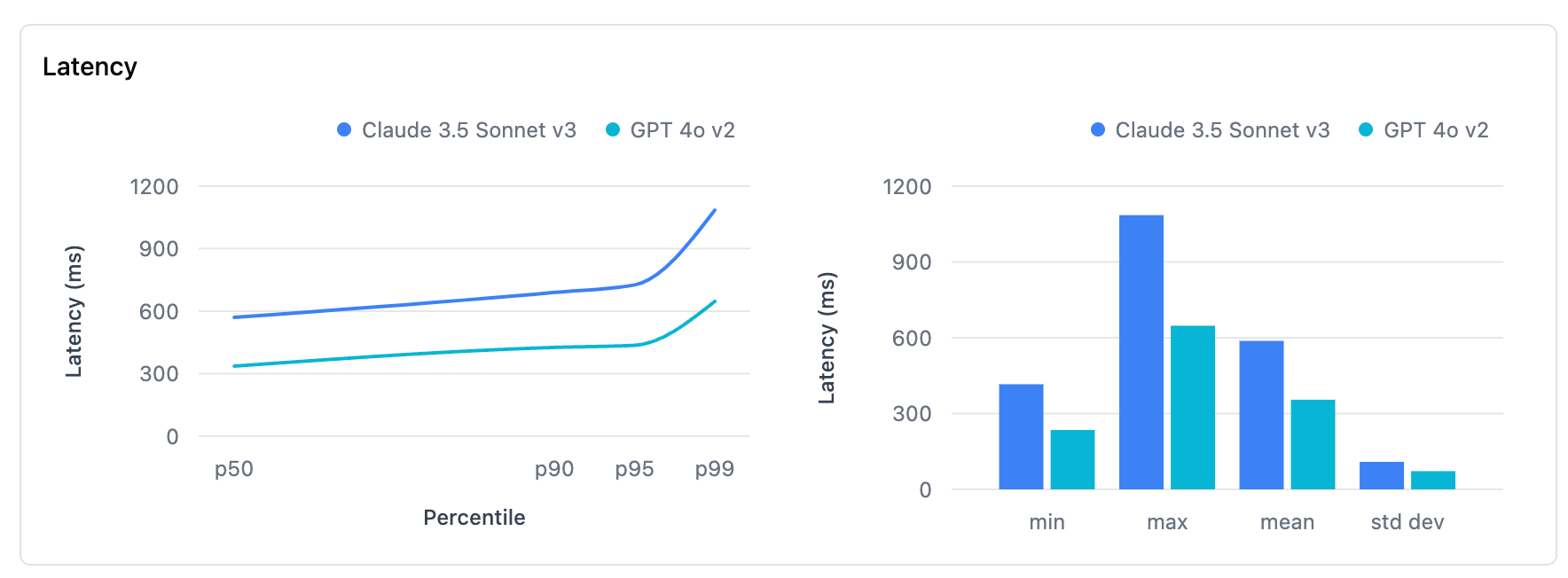
While Claude 3.5 Sonnet has made notable strides in reducing delay and enhancing efficiency, GPT-4o remains the leader in delivering the quickest response. This means that users seeking the fastest possible response for their computational needs will find GPT-4o superior in terms of minimizing waiting time and maximizing throughput.
Winner: Gpt 4o
Throughput: Comparing Claude 3.5 Sonnet and GPT 4o
The throughput is measured in tokens per second. Claude 3.5 Sonnet's throughput has improved about 3.43 times compared to Claude 3 Opus, which achieved 23 tokens per second. In our experiments, we found that the throughput for claude-3.5-sonnet was marginally better than that of GPT-4o.
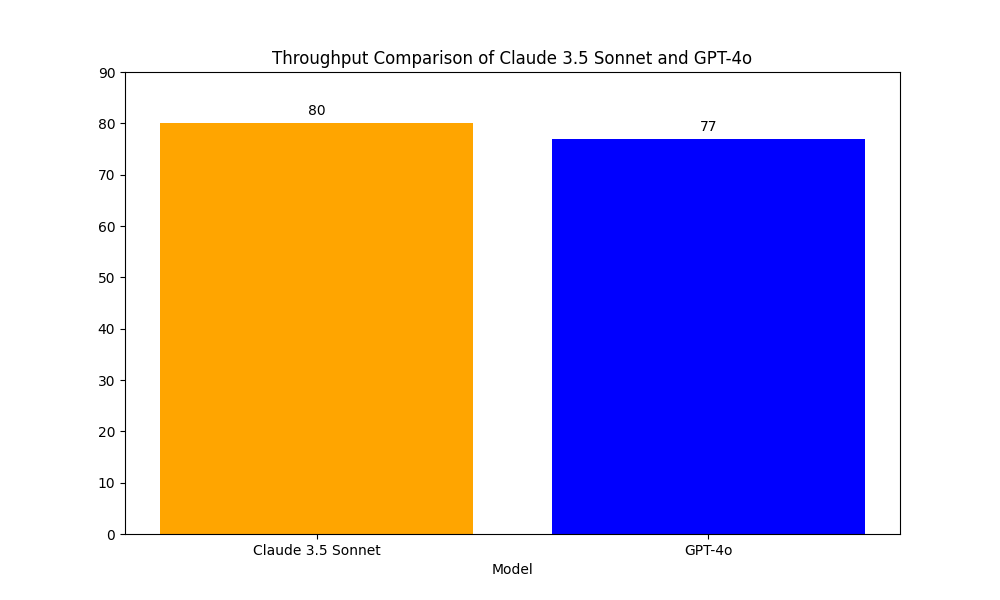
Winner: Calude 3.5 Sonnet
Cost and Context: Comparing Claude 3.5 Sonnet and GPT 4o
Claude 3.5 Sonnet has the same cost for Output Tokens but is lower in price for input tokens. It's also important to note that Claude 3.5 Sonnet has a higher context window of 200K compared to that of GPT 4o's 128K.
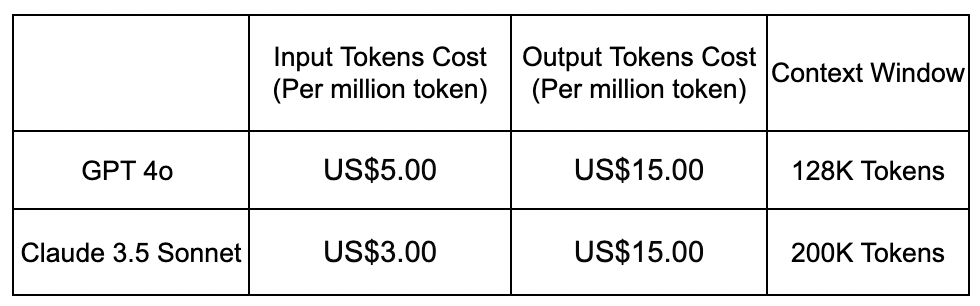
Winner: Calude 3.5 Sonnet
Quality Comparision
Now that we have examined the two models' performance, we will compare them in terms of quality. We will first look at the published standard benchmarks, but they have limitations, as it's possible to game the public benchmarks. We will also examine how the models fared on our internal benchmarks.
Standard benchmark published
Any new model's capabilities are assessed through benchmark data presented in technical reports. The image below compares Claude 3.5 Sonnet's performance on standard benchmarks against the top five proprietary models and one open-source model.
.png)
As reported by Anthropic's release, Claude 3.5 Sonnet sets new industry benchmarks in graduate-level reasoning (GPQA), undergraduate-level knowledge (MMLU), and coding proficiency (HumanEval). It excels at grasping nuance, humour, and complex instructions and is exceptional at writing high-quality content with a natural, relatable tone.
Key takeaways from this comparison:
- Claude 3.5 Sonnet leads in Graduate Level Reasoning, Undergraduate Level Knowledge, and Code, followed by GPT-4o.
- Claude 3.5 Sonnet scores highest in Multilingual Math (91.6%), with Claude 3 Opus in second place (90.7%).
- In Reasoning Over Text, Claude 3.5 Sonnet outperforms others with 87.1%, followed by Llama-400b at 83.5%.
Winner: Calude 3.5 Sonnet
Elo Rating
The ELO Leaderboard rankings have been released, with GPT-4o maintaining the top spot.
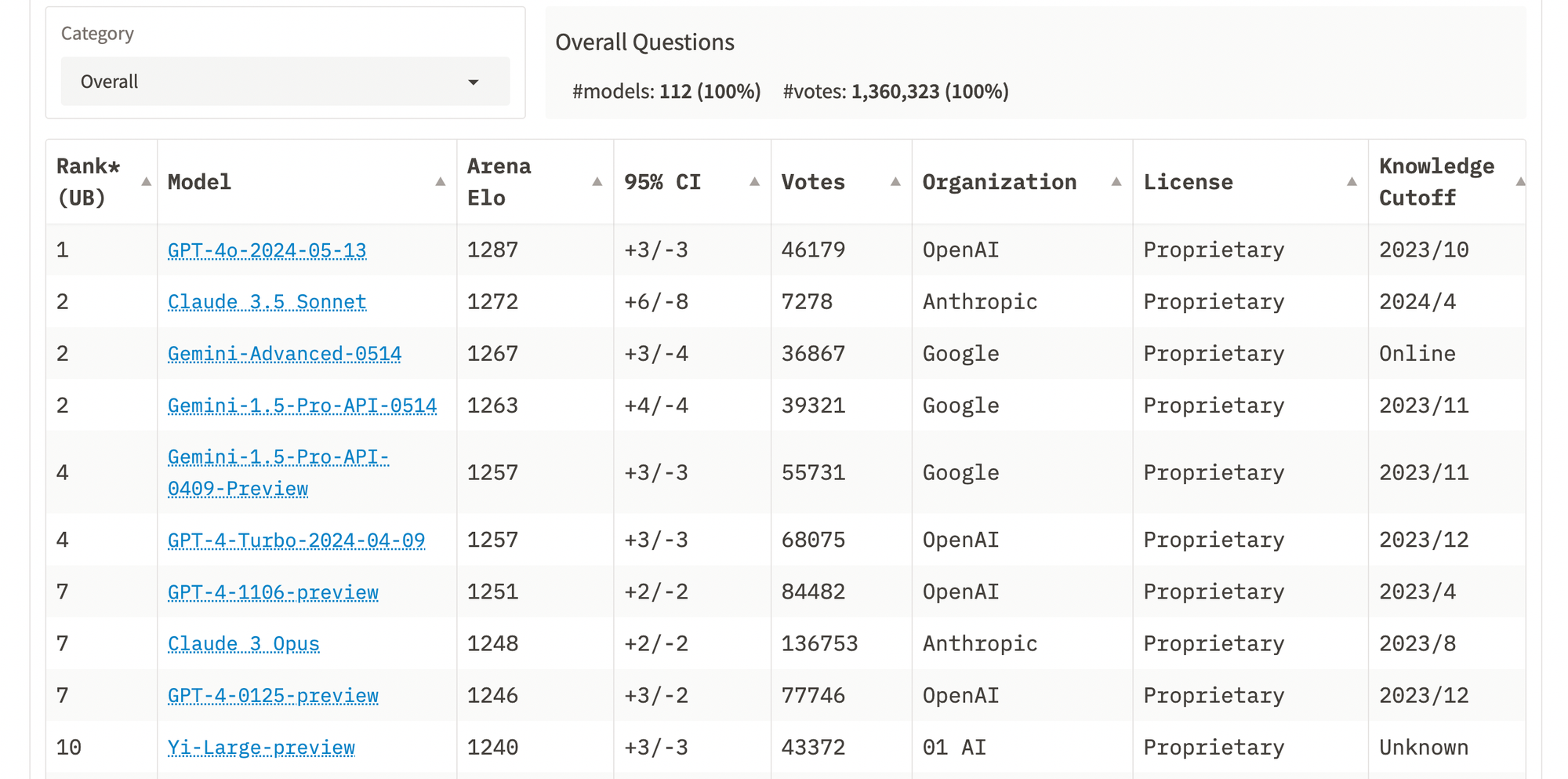
This public ELO leaderboard is part of the LMSYS Chatbot Arena, where users can prompt two anonymous language models, vote on the best response, and then reveal their identities. This creates a huge anonymous quality review for the models, thus ensuring the right model has the highest score as per human expectations.
While GPT-4o leads overall, Sonnet achieved the highest score in coding—a significant feat given it isn't even the largest model in the Claude 3 family.
Here is a look at task-specific scores for different models in different categories.

Winner: Gpt 4o
Internal benchmark on different niche tasks
- Mathematical abilities:
We wanted to test the models' ability to solve medium—to tough algebraic and word problems for the first task.
An example of the problems we probed the model with:
if x + | x | + y = 7 and x + | y | - y = 5 what is x + y = ?
So, as evident, solving this problem is not entirely trivial. At the end of the benchmark, we concluded that both models have room for improvement in this regard. Claude and GPT 4o scored in the 30-45% range, with Claude scoring marginally better.
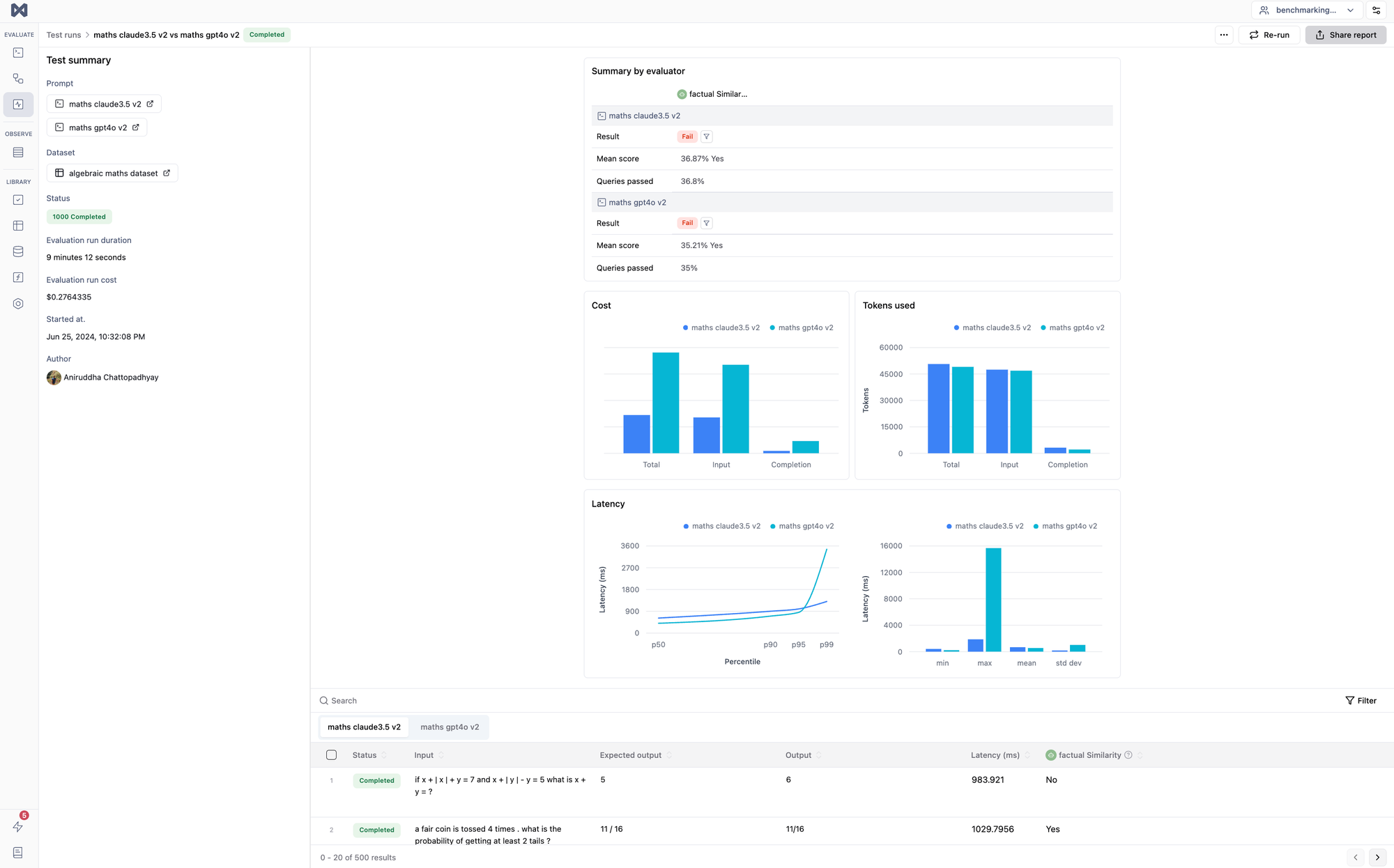
Also, every run had some variation, but the result hovered in the 30-45% range. Maybe the score would have improved with a better, more tuned system prompt, but both models have significant room for improvement in this aspect.
Winner: Calude 3.5 Sonnet
Classification and language reasoning:
Next, we wanted to test the model using natural language inference. We wanted to test its ability to perform multiclass classification on a natural language inference dataset for this. We wanted to test its ability to perform multiclass classification on a natural language inference dataset for this. The classification would test its verbal reasoning abilities.
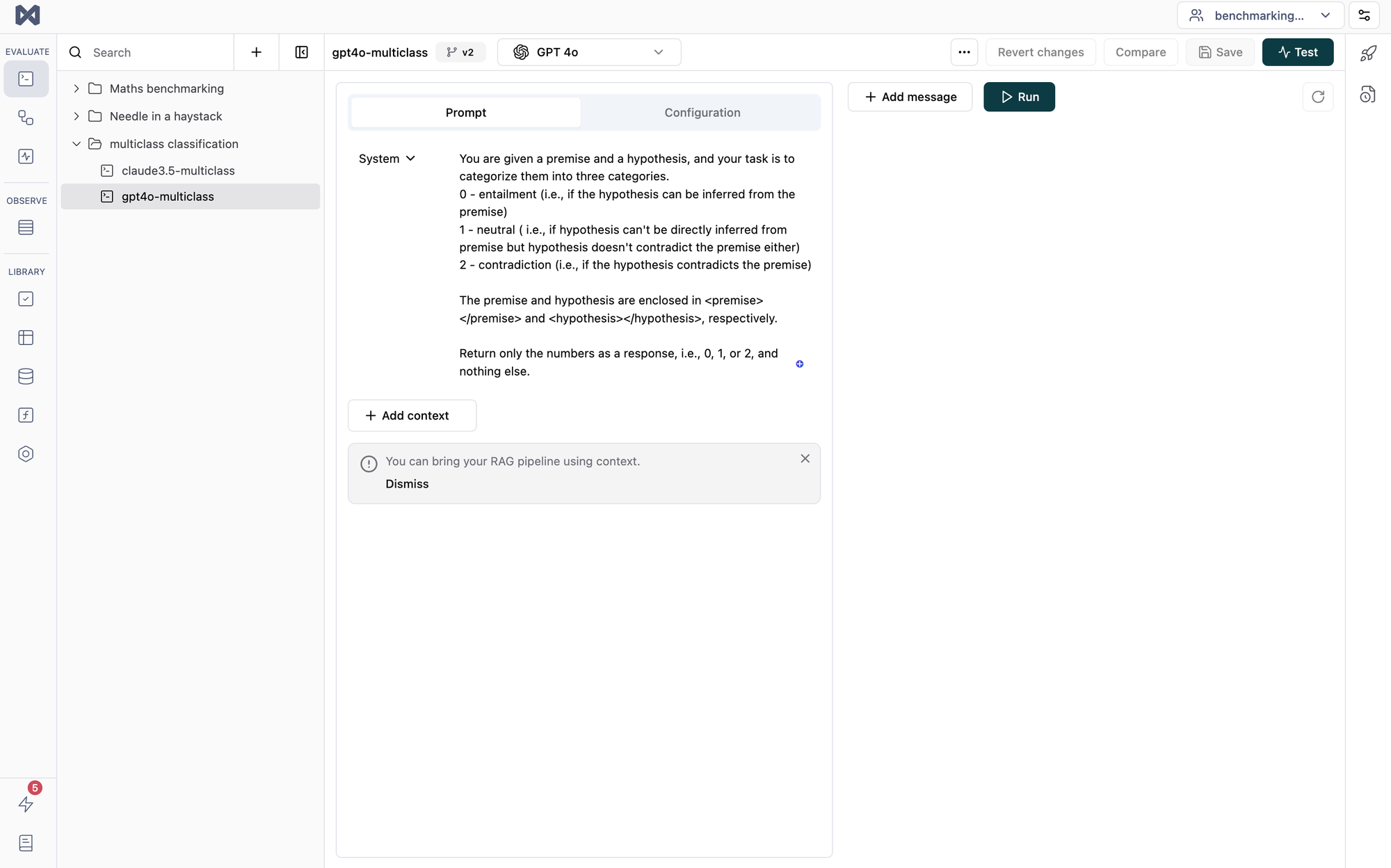
Here, the two models were given prompts that contained a premise and hypothesis, and they were asked to classify the prompts into 3 categories:
- Class 0 (entailment): If the hypothesis can be inferred from the premise and therefore
- Class 1 (neutral): If the hypothesis can't be inferred from the premise but it doesn't contradict each other.
- Class 2 (contradiction): If the hypothesis contradicts the statement in the premise.
Note: All three classes were balanced in the dataset we have used.
Here is a snapshot of the system prompt used for this task that was given to both models. (The same system prompt was used for both models).
Both the models performed well, with GPT4o leading in all the metrics for the classification task, be it accuracy, recall, precision or F1 score as seen below.
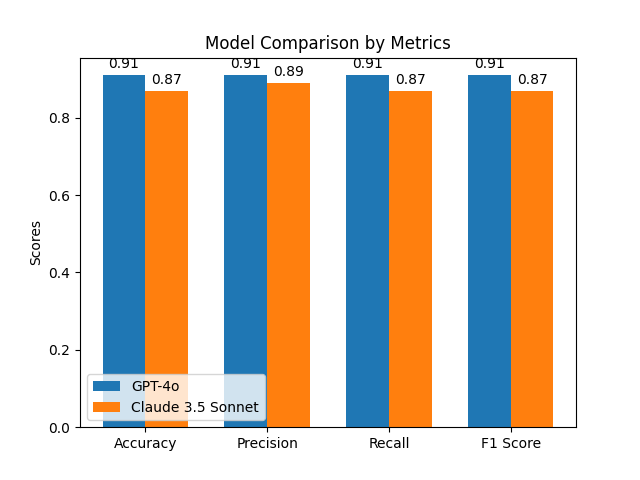
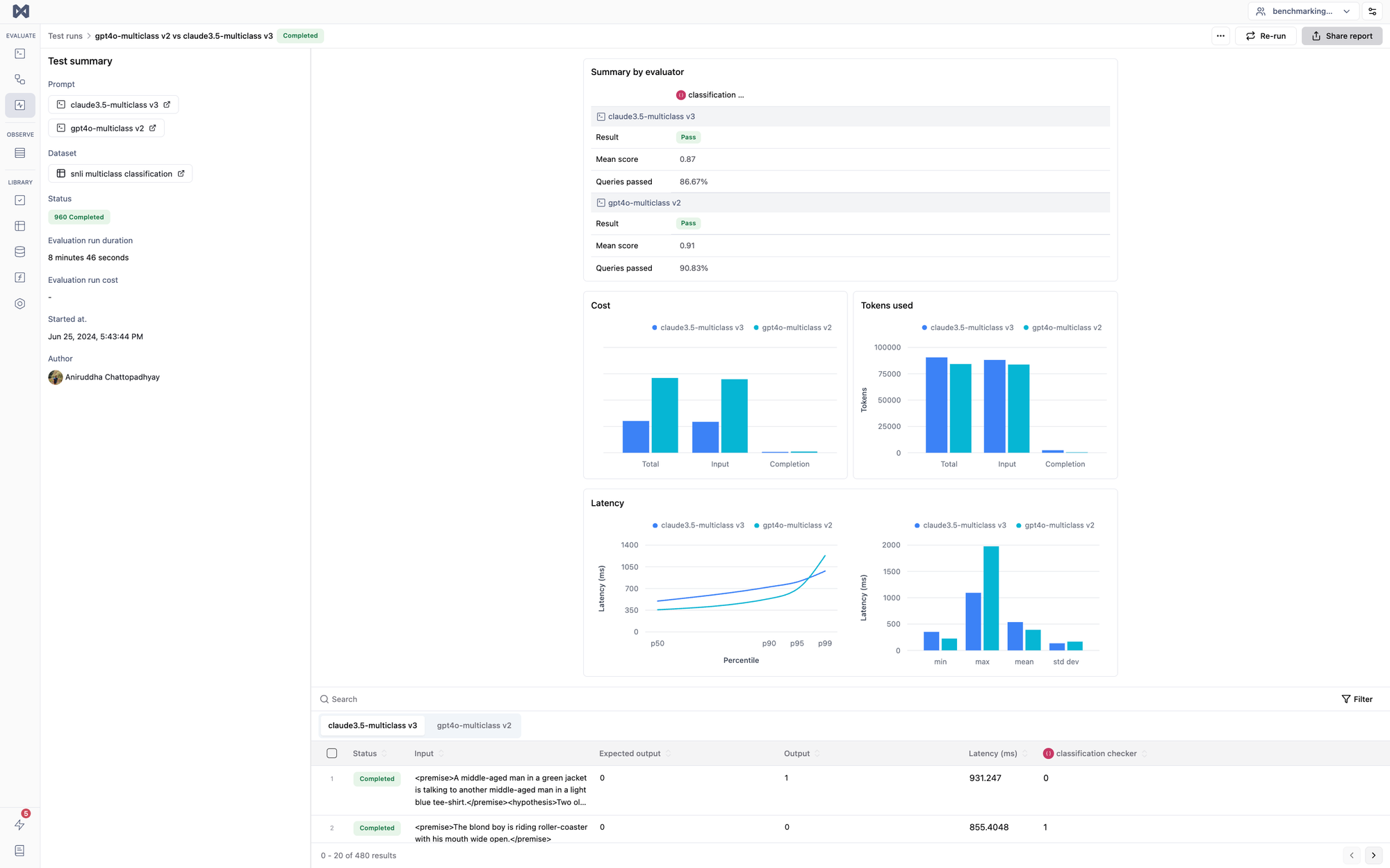
Winner: Gpt 4o
Long Context Inference:
Here, we emulated the very popular needle-in-a-haystack methodology on our own dataset to observe both models' long context inference abilities.
The idea of the needle in a haystack test is to inject a small piece of out-of-context text information (the needle) into a large corpus of text (the haystack) and see if the model is able to retrieve the needle when asked about it.
Upon looking at the responses, we concluded that both GPT 4o and Claude 3.5 Sonnet are equally well-versed in fetching the needle from the haystack. However, one key observation was that while GPT-4o answers strictly according to the context, Claude-3.5-Sonnet answers according to the context, but at the same time, it mentions that the needle seems out of context to the whole haystack text, as we can see in the Output below.
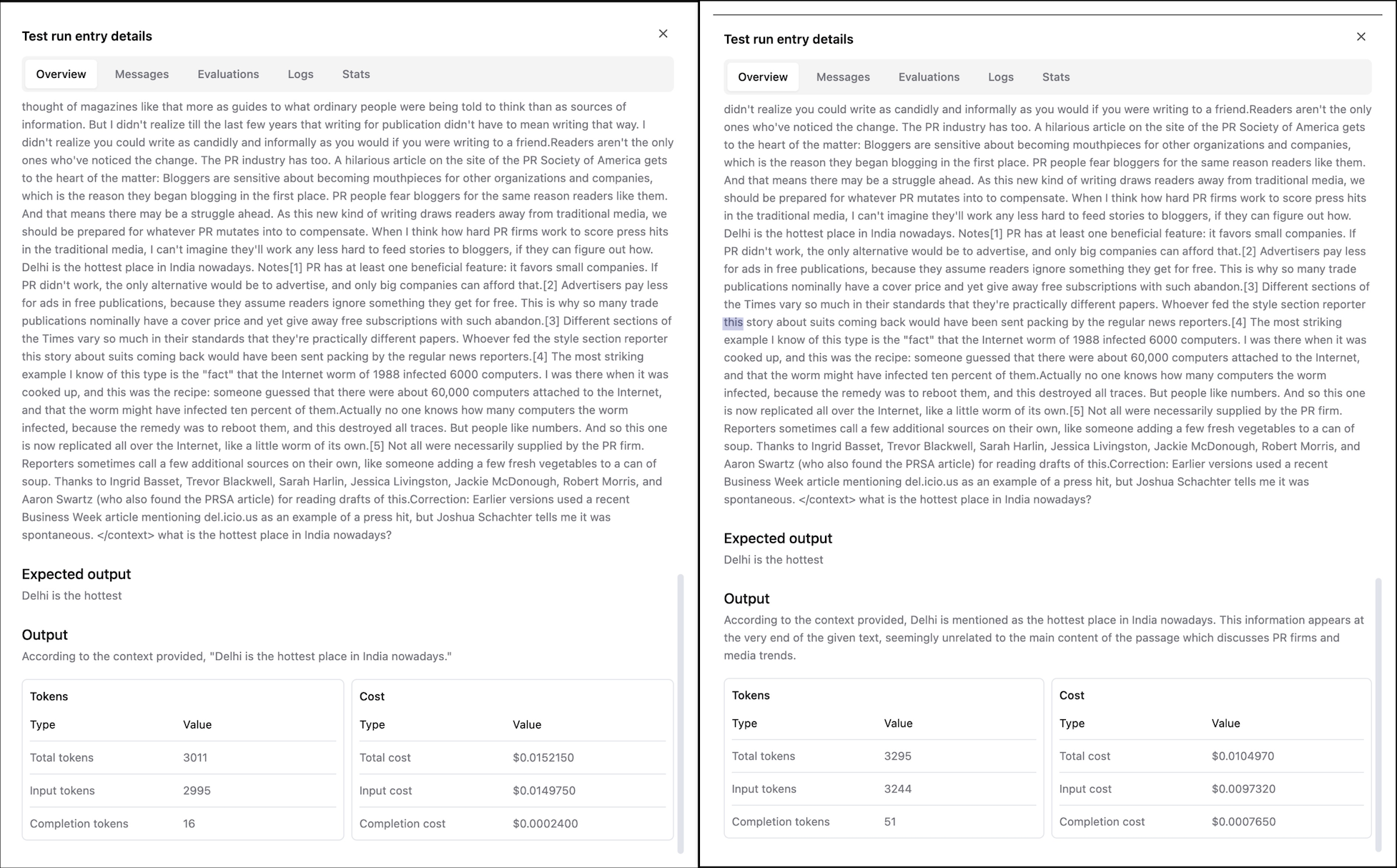
Winner: DRAW
Summary
Below is a summary table of all insights from our experiments:
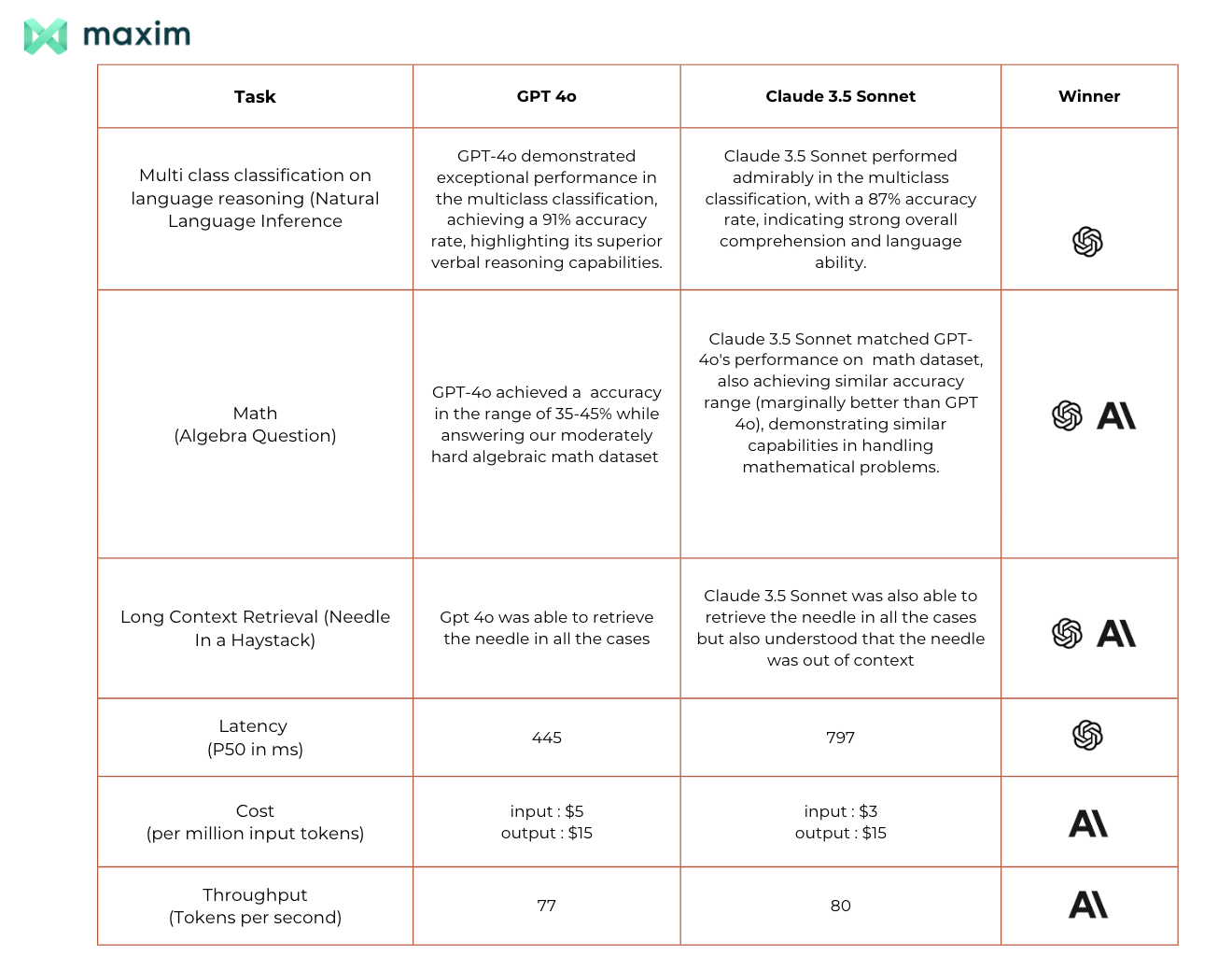
Conclusion
According to our experiments, GPT 4o still leads in some of the use cases, but as is the case with most things in Gen AI, a thorough use case-based analysis is needed to confidently decide which model works based on your use case.
At Maxim, we support both of these SOTA models, among others, as well as multimodal datasets, an evaluator store, and the ability to attach context sources (for RAG) to allow you to run these experiments at scale on your own use case and make a decision not just based on vibe checks but on quantifiable metrics.