Breaking the Context Window: How Recursive Language Models Handle Infinite Input

Long-context understanding has been a persistent challenge in language model research. Despite architectural innovations (ALiBi, YaRN, RoPE variants) and massive context window expansions (Claude 3.5 at 200k tokens, GPT-5 at 256k+), models still exhibit performance degradation on long inputs, a phenomenon known as "context rot." The community has pursued ever-larger context windows, but this approach hits both performance and systems-level walls.
Recursive Language Models (RLMs), a new inference strategy from MIT researchers , takes a fundamentally different approach: instead of forcing models to process unbounded context directly, let them recursively decompose and interact with that context through a REPL environment. The result? RLM(GPT-5-mini) outperforms base GPT-5 by 114% on challenging long-context benchmarks while maintaining comparable costs, and scales to effectively unlimited input lengths (10M+ tokens tested).
The Problem: Context Rot is Real and Poorly Characterized
Here's the paradox: modern frontier models achieve 90%+ accuracy on synthetic benchmarks like RULER's needle-in-a-haystack tests, yet practitioners consistently report degradation in real-world scenarios: extended Claude Code sessions, long ChatGPT conversations, multi-document analysis. The benchmarks don't capture what matters.
Why? Most long-context benchmarks test retrieval of isolated facts from low-information-density "haystacks." Real tasks involve higher complexity: semantic aggregation across thousands of entries, multi-hop reasoning across documents, or maintaining coherence over evolving state. As Anthropic notes in their context engineering documentation, "as the number of tokens in the context window increases, the model's ability to accurately recall information decreases". But this definition misses the interaction between context length and task complexity.
One of the ways to handle this problem has been architectural: make context windows bigger and hope performance holds. But two fundamental problems remain:
- Performance degradation persists even within nominal context limits, especially for information-dense tasks
- Systems constraints make processing multi-million token contexts impractical despite theoretical support
What if the solution isn't bigger context windows, but smarter decomposition strategies that models control themselves?
How Recursive Language Models Work
Here's the elegant core idea: from the user's perspective, calling an RLM looks identical to calling a regular language model. Using rlm.completion(query, context) provides the same interface as a standard model completion. But under the hood, something fundamentally different is happening.
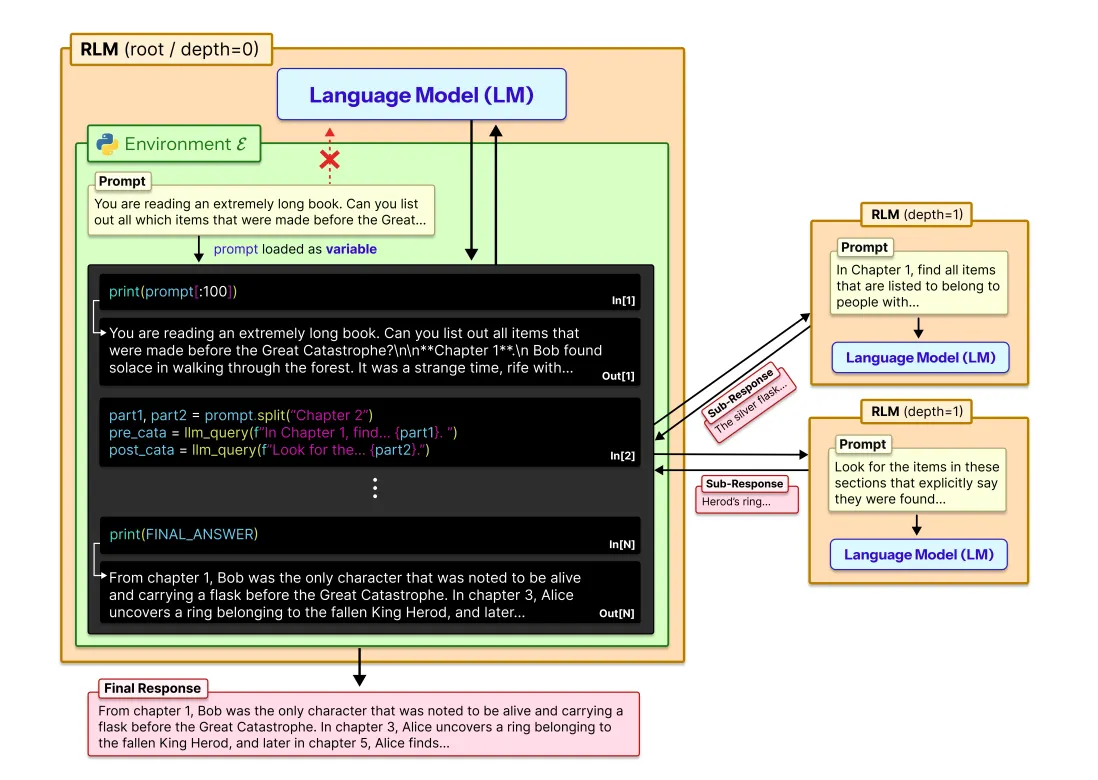
The Context-Centric Approach
Instead of giving the model your entire context upfront, RLMs provide:
- Your query to the root language model
- An environment (specifically, a Python REPL/notebook) that stores the context as a variable
- The ability to recursively spawn new LM calls within that environment
Think of it like this: instead of asking a model to read and memorize a 500-page book before answering a question, you give it the question and let it interactively explore the book, peeking at sections, searching for keywords, and asking sub-questions to itself about specific passages.
The REPL Environment
The choice of Python REPL as the environment is deliberate and powerful. The root LM receives only the query initially, with context stored as a variable it can manipulate programmatically:
- Inspection:
context[:2000]orcontext.split('\\n')[100:110] - Filtering:
[line for line in context if regex.match(pattern, line)] - Transformation: Parse, chunk, or restructure data before querying
- Recursive decomposition:
rlm_call(sub_query, context_chunk)spawns isolated sub-instances - State accumulation: Build answers incrementally across iterations
Crucially, the root LM's context window stays lean. It never ingests the full context, only the portions it explicitly requests and the outputs from recursive calls (which are truncated to prevent context bloat).
When confident, the model terminates with FINAL(answer) or FINAL_VAR(variable_name) to return a programmatically constructed result.
The Results: Small Models Outperforming Large Ones
The researchers tested RLMs on two challenging benchmarks where modern frontier models struggle:
OOLONG: Beating GPT-5 with GPT-5-mini
The OOLONG benchmark tests semantic reasoning over thousands of unstructured data entries. For example: "Among instances from users 67144, 53321, 38876... how many should be classified as 'entity'?", but the entries aren't pre-labeled, so the model must infer labels for ~3000-6000 rows.
The results at 132k tokens (well within GPT-5's context window):
- GPT-5: 30.2 points
- GPT-5-mini: 20.3 points
- RLM(GPT-5-mini): 64.7 points (114% improvement over GPT-5!)
And get this: RLM(GPT-5-mini) cost roughly the same per query as regular GPT-5. A smaller model with recursive reasoning beats a larger model with direct access to all context (and does so economically.)
Even at 263k tokens (near the limit for both models), RLM(GPT-5-mini) maintained a 49% improvement over base GPT-5, while the cost per query actually decreased.
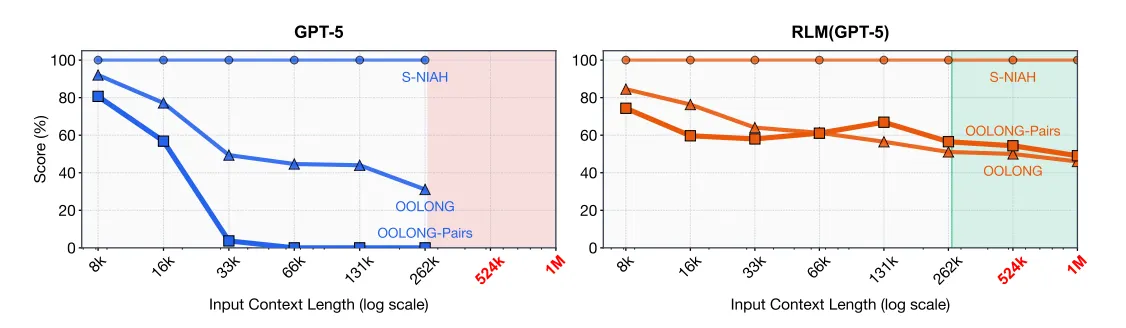
BrowseComp-Plus: Handling 10M+ Tokens
The researchers created a "Deep Research" task using BrowseComp-Plus, where models must answer multi-hop questions scattered across massive document collections (think 100,000 documents averaging 5k words each.)
At 1,000 documents (~5M+ tokens):
- GPT-5 (truncated): ~40% accuracy
- GPT-5 + BM25 retrieval: ~60% accuracy
- ReAct + GPT-5 + BM25: ~80% accuracy
- RLM(GPT-5): 100% accuracy
What's remarkable is that RLM(GPT-5) was the only approach that maintained perfect performance at this scale, and did so without pre-indexing the corpus with traditional retrieval methods. The model dynamically decides how to search and process information at runtime.
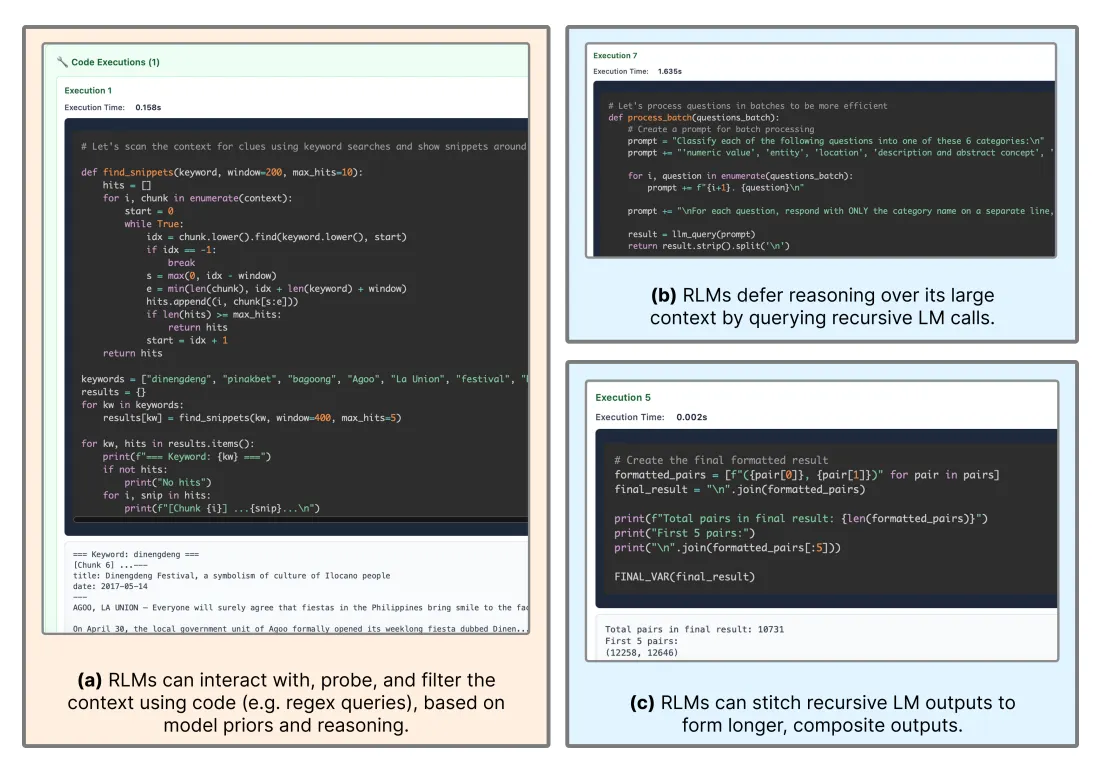
What's the Model Actually Doing?
One of the coolest aspects of RLMs is interpretability: you can watch how the model breaks down its task. The researchers observed several emergent strategies:
Peeking: Like a programmer examining a dataset, the model inspects small portions to understand structure:
context[:2000] # Look at first 2000 characters
Grepping: Using pattern matching to narrow search space:
[line for line in context if 'user_id' in line and 'question' in line]
Partition + Map: Chunking context and spawning parallel recursive calls:
for chunk in split_context(context, size=1000):
result = recursive_lm(f"Label this chunk: {chunk}")
Summarization: Condensing information from subsets before making decisions.
Programmatic One-Shotting: For tasks like tracking git diffs across 75k+ token histories (where GPT-5 fails 90% of the time), RLMs can programmatically apply changes rather than trying to "think through" each diff.
Four Key Observations from the Paper
Beyond the impressive benchmark results, the researchers identified four critical patterns that reveal how and when RLMs excel:
Observation 1: RLMs Scale to 10M+ Tokens and Outperform Everything Else
RLMs demonstrated strong performance on inputs well beyond the effective context window of frontier LMs, outperforming base models and common long-context scaffolds by up to 2× while maintaining comparable or cheaper average token costs.
The kicker? On BrowseComp-Plus with 1,000 documents (6-11M input tokens), the cost of using RLM scales comparably to what it would theoretically cost for GPT-5-mini to ingest those tokens directly, except the RLM actually works while direct ingestion fails.
Even on tasks that fit well within the model's context window (like OOLONG at 132k tokens), RLMs make significant improvements over the base model. This suggests context rot happens even when you're technically "within limits."
Observation 2: REPL Enables Scale, Recursion Enables Intelligence
The ablation studies revealed something nuanced: the two components of RLMs serve different purposes.
The REPL environment alone (without recursive sub-calls) enables scaling beyond context limits. Even when the RLM can't spawn sub-queries, offloading context to a variable that the model manipulates programmatically still outperforms base models on most long-context tasks. On some tasks like CodeQA with Qwen3-Coder, the REPL-only ablation even outperformed the full RLM.
Recursive sub-calling becomes critical for information-dense tasks. On OOLONG and OOLONG-Pairs, where the model needs to perform semantic transformations (like labeling each entry), recursive calls were necessary. The ablation without sub-calls was forced to use keyword heuristics and performed significantly worse.
The takeaway: if you're just dealing with long contexts that need basic processing, REPL alone might suffice. But for tasks requiring deep semantic understanding across the context, recursion is essential.
Observation 3: Degradation vs. Complexity
Perhaps the most interesting finding: LM performance degrades as a function of both input length AND problem complexity, while RLM performance degrades much more slowly.
The researchers tested three benchmark types with different processing costs:
- S-NIAH (constant complexity): Simple needle-in-haystack
- OOLONG (linear complexity): Transform and aggregate many entries
- OOLONG-Pairs (quadratic complexity): Pairwise aggregation across inputs
As contexts grew from small to 2^18 tokens, GPT-5's performance degraded significantly faster on more complex tasks. RLMs also degraded, but at a much slower rate. This aligns with recent findings about how complexity compounds with length in language models.
Interestingly, on small input contexts, base LMs slightly outperform RLMs. This suggests a tradeoff point. There's overhead to the RLM framework that only pays off once inputs exceed a certain threshold. So for short, simple queries, just use the base model.
Observation 4: Cost is Comparable but High Variance
RLM inference costs remain in the same order of magnitude as base model calls, but with much higher variance due to differences in trajectory lengths.
At the 50th percentile, RLMs are often cheaper than base models. But at the 95th percentile, costs can spike sharply when the RLM takes particularly long trajectories to solve complex problems.
This makes sense: when the model finds the answer quickly (efficient grepping or early termination), it's cheap. When it needs to recursively process many chunks or iterate multiple times, costs accumulate. The median query is efficient; the tail is expensive.
This variance is actually a feature, not a bug, since it means that the model is adaptively spending compute where needed rather than using a fixed budget regardless of difficulty.
Why This Matters Beyond Long Context
RLMs represent a fundamentally different approach to test-time compute scaling. While reasoning models like o1 scale by thinking longer, and agent models scale by taking more actions, RLMs scale by recursively decomposing context.
Not Just Agents, Not Just Summarization
Existing agentic systems decompose tasks based on human intuition: "first search the web, then analyze results, then synthesize." RLMs decompose context and let the model decide the strategy. It's the difference between giving someone step-by-step instructions versus trusting them to figure out the best approach.
The Training Data Opportunity
Just as Chain-of-Thought reasoning and instruction-tuning improved models by presenting data in predictable formats, RLMs create a new axis for scaling laws. Imagine training models explicitly to:
- Efficiently partition context
- Choose optimal recursion strategies
- Balance cost vs. performance in their recursion depth
- Handle truly unbounded inputs
These trajectories are entirely learnable. They can be optimized with reinforcement learning the same way reasoning is trained in current frontier models.
RLMs Improve As Models Improve
Here's the multiplier effect: if tomorrow's frontier LM handles 10M tokens well, an RLM built on it could handle 100M+ tokens at potentially lower cost. Every improvement to base model capabilities compounds when applied recursively.
Current Limitations and Future Work
The researchers are transparent about limitations:
- No optimization for speed: Each recursive call is blocking (not async) and doesn't use prefix caching. Queries can take minutes.
- No guarantees on cost or runtime: The model decides how deeply to recurse, which affects both.
- Depth limited to 1: Current experiments only allow the root LM to call other LMs, not other RLMs. Enabling deeper recursion could unlock more complex reasoning.
But these are implementation challenges, not fundamental limitations. The systems community has significant low-hanging fruit to optimize here: asynchronous execution, better caching strategies, and batching recursive calls could dramatically improve performance.
The Philosophical Shift
RLMs force us to reconsider a core assumption: must we solve context rot at the model architecture level? The researchers argue no. Instead of training models that never degrade with context length, build a framework where models never face that context length directly.
This is a different bet than modern agents. Agents encode human intuition about problem decomposition. RLMs encode the principle that language models should decide how to decompose problems for language models.
We don't know yet which approach will win. But given that RLM(GPT-5-mini) already beats GPT-5 on challenging benchmarks without any specialized training, the early results are compelling.
Final Thoughts
Recursive Language Models solve a problem that's been hiding in plain sight. We've been so focused on expanding context windows that we forgot to ask: do we need to show models everything at once?
The answer, increasingly, seems to be no. By letting models recursively explore and process context through a programmable environment, we can:
- Handle effectively unlimited input lengths
- Improve performance even for contexts well within existing limits
- Reduce costs compared to processing everything directly
- Maintain interpretability of model reasoning
As models get better at this kind of recursive reasoning, especially with explicit training, RLMs could represent the next major milestone in test-time inference scaling, right alongside chain-of-thought reasoning and agentic workflows.
The future of long context might not be bigger windows. It might be smarter recursion.
Paper: "Recursive Language Models" by Alex L. Zhang and Omar Khattab (MIT)
Available at: arxiv.org/abs/2512.24601


