Beyond the Benchmark: Why TruthTensor Might Be the Eval Framework We've Been Missing

When was the last time you confidently trusted a benchmark to tell you how an LLM would actually perform in production? The gap between benchmark performance and real-world reliability is significant, and it's a problem that deserves more attention.
I recently read through this paper by Inference Labs, and it addresses a real pain point in LLM evaluation. The authors argue that static benchmarks don't capture what matters for production systems, and propose an alternative approach.
Their core thesis? Treat LLMs as oracle systems that should be evaluated on how well they imitate human probabilistic reasoning under uncertainty, not just on whether they can regurgitate the right answer from their training distribution.
The Problem with Static Benchmarks
Most evaluation frameworks test LLMs on historical data with known answers. MMLU, GSM8K, HumanEval - they measure whether the model can retrieve information it might have seen during training. This creates two fundamental problems.
Contamination: Models trained on web-scale data often encounter variations of test sets during training. The "train on everything, test on a fixed dataset" paradigm breaks down when your training corpus includes Common Crawl and GitHub dumps.
Misaligned evaluation: Beyond contamination, these benchmarks test factual recall and pattern matching rather than adaptive reasoning under uncertainty. In production, we need models that can reason through uncertainty, update beliefs as new information emerges, handle distribution shift, and make decisions that align with human judgment.
The TruthTensor paper reframes the evaluation problem. Traditional benchmarks essentially measure whether a model can produce correct answers given historical questions. What matters in production is whether a model can perform human-aligned reasoning given evolving contexts and genuine uncertainty.
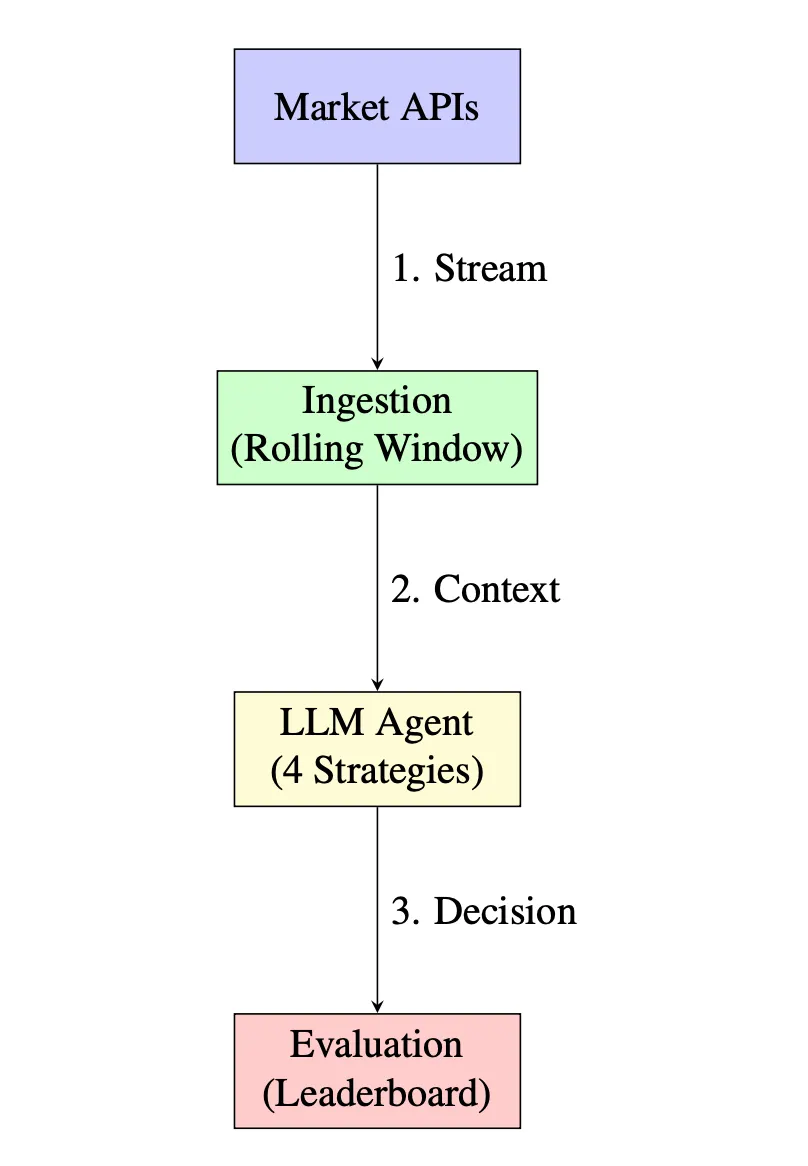
The TruthTensor Approach: Prediction Markets as Ground Truth
So how do they actually do this? They anchor their evaluation to live prediction markets: places like Polymarket, Metaculus, Kalshi, where real humans are putting real money (or reputation) on the line to forecast events.
The technical setup is clever. They:
- Sample from active markets: 500+ markets across politics, economics, technology, and culture
- Time-series evaluation: For each market, they collect model predictions at multiple time points as new information becomes available
- Multi-model comparison: They evaluate across different model families (GPT-4, Claude, Llama, etc.) and sizes
- Structured prompting: Models receive the market question, current price (as a proxy for crowd belief), recent news/events, and are asked to provide both a probability estimate and reasoning
Why prediction markets specifically? Several reasons:
Contamination-free by construction: These are forward-looking questions about events that haven't happened yet. By definition, the ground truth couldn't have been in the training data. This eliminates the entire category of "is the model just memorizing" concerns.
High entropy: The outcomes are genuinely uncertain. Unlike "what's the capital of France" (zero bits of information), these questions have meaningful Shannon entropy. Markets that are 50/50 represent maximum uncertainty; markets at 80/20 represent strong but not absolute belief.
Aggregated human expertise: Prediction markets, especially those with financial stakes, represent a Bayesian aggregation of human forecasters. They're essentially continuous ensemble methods over human reasoning. The Efficient Market Hypothesis (in its weak form) suggests these prices should incorporate all publicly available information.
Dynamic ground truth: As events unfold, the "correct" probability estimate changes. A prediction of 60% today might be perfectly calibrated even if the event happens or doesn't, but by tomorrow, new information might make 60% wildly miscalibrated. This lets you test temporal reasoning and belief updating.
Real-world relevance: These aren't toy problems. They're questions that people actually care about predicting correctly.
The Oracle Framing: LLMs as Probabilistic Reasoners
The paper adopts an "oracle perspective" that treats LLMs as probabilistic reasoning systems rather than deterministic answer machines. Models should navigate uncertainty, update beliefs, and express confidence appropriately like human experts do.
They break down oracle evaluation into several components:
Belief Initialization: Given a question and initial context, can the model form a reasonable prior? They compare model priors to market priors at the start.
Belief Updating: Given new information, does the model update appropriately? Updates should be proportional to the informativeness of new evidence.
Uncertainty Quantification: Can the model express appropriate uncertainty through confidence intervals that match actual outcome frequencies?
Information Synthesis: When facing conflicting evidence, can the model weigh sources appropriately? They test this with scenarios containing contradictory signals.
This maps well to production use cases. When building AI assistants that make recommendations or help with decisions, you need models that reason probabilistically and recognize their limitations, not systems that confidently hallucinate.
The oracle framing also explains why traditional accuracy metrics fail. If an event has a true probability of 60%, both a model predicting 60% and one predicting 90% could get the binary outcome "right" if the event happens. But only the first model demonstrated correct reasoning.
What They're Actually Measuring (And Why It Matters)
This is where it gets interesting. TruthTensor doesn't just score accuracy. It measures:
1. Calibration
Calibration measures whether a model's confidence levels are meaningful. If a model predicts 80% probability, that outcome should occur approximately 80% of the time.
They use Expected Calibration Error (ECE) to quantify this, which partitions predictions into confidence bins and measures the gap between accuracy and confidence in each bin. A perfectly calibrated model has ECE = 0.
They also track Brier scores for probabilistic accuracy, where lower scores indicate better performance. The key insight is tracking these metrics over time and across risk levels. A model might be well-calibrated on straightforward questions but systematically overconfident on difficult ones. Or it might be calibrated initially but drift as events approach.
This matters because overconfident models create deployment risks. If your model reports 95% confidence but is wrong 30% of the time, you'll make poor decisions based on unreliable confidence estimates.
2. Drift Metrics
The paper measures how well models maintain narrative coherence over time. Do predictions flip-flop when new information arrives? Do models overreact to noise?
The Narrative Drift Score quantifies changes in both predictions and reasoning. They use several measures:
Prediction Drift: Simple magnitude of probability changes between time points.
Reasoning Drift: They embed the model's reasoning text into semantic space using sentence transformers, then measure cosine distance between embeddings at different time points. This captures whether the underlying logic changed, not just the final prediction.
Volatility-adjusted drift: Compares model drift to market drift. If the market moves significantly and the model follows, that's appropriate updating. If the market barely moves but the model changes dramatically, that suggests overreaction to noise.
They also track flip frequency: how often a model crosses the 50% threshold, switching from "will happen" to "won't happen."
For agentic systems, this is particularly important. Unstable decision-making logic as context evolves creates reliability problems that accuracy metrics miss. The goal is Bayesian-like updating, ie. beliefs should change in proportion to the information value of new evidence, not random fluctuations.
3. Risk Sensitivity
How do models handle high-stakes vs. low-stakes decisions? TruthTensor tracks whether models appropriately adjust their reasoning and confidence based on the significance of the prediction.
4. Human Imitation
This is the core thesis. Rather than treating LLMs as prediction engines, they evaluate them as human imitation systems. How well do their reasoning patterns, belief updates, and confidence calibration match what human forecasters do in the same markets?
Temporal Drift: Multiple Dimensions of Change
LLMs encode general-purpose knowledge across domains, which means temporal drift manifests in multiple ways simultaneously.
The paper identifies three types of drift:
Data Distribution Drift: The input distribution changes. What people ask about and how they phrase questions evolves over time.
Concept Drift: The relationship between inputs and outputs changes. "Who is the president?" has the same syntax across years, but the correct answer changes. For LLMs, this is particularly challenging because parametric knowledge is frozen at training time.
Language Drift: How people discuss topics evolves. New terminology emerges and existing terms take on new meanings.
TruthTensor measures drift through information event tracking. They timestamp major information events (Fed announcements, poll releases) and measure:
- Market movement magnitude (human belief updates)
- Model movement magnitude (model belief updates)
- Alignment between the two (correlation)
They compute an Information Responsiveness Score that weights information events by significance and measures how well model updates align with market updates.
They also track lag sensitivity: whether models respond to information with appropriate timing. Markets typically react to major news within minutes to hours. Models that don't update until explicitly re-prompted have temporal awareness issues.
For general-purpose LLMs, this creates domain-specific challenges. A model might be current on tech news but outdated on geopolitics. TruthTensor evaluates this by comparing performance across market categories.
Key Findings: Accuracy Isn't Everything
The experiments demonstrate that models with similar forecast accuracy can diverge significantly in calibration, drift, and risk sensitivity.
Notable findings:
Calibration varies across model families: Some models achieve ~72% accuracy with ECE of 0.08, while others hit 74% accuracy with ECE of 0.19. The second model is less reliable for decision-making despite slightly higher accuracy.
Scaling doesn't guarantee calibration: Larger models aren't necessarily better calibrated. Some evidence suggests larger models can become more overconfident in incorrect predictions.
Drift correlates with reasoning depth: Models providing detailed, multi-step reasoning tend to have higher narrative drift but better calibration. There's a tradeoff between reasoning verbosity and prediction stability. Structured reasoning (like explicit Bayesian updating) seems to hit a better balance than lengthy unstructured explanations.
Information responsiveness varies: Some models update heavily on any new information (high responsiveness but also high volatility), while others resist updating even with significant new evidence (low responsiveness, low volatility). Human forecasters typically fall between these extremes, updating proportionally to information value.
Risk sensitivity patterns differ: In high-stakes markets (measured by trading volume), some models become more conservative (regressing toward 50%), while others become more extreme. Neither behaviour is universally correct. It depends on your risk tolerance and error costs.
This has practical implications for model selection. If you're choosing models based solely on accuracy benchmarks, you might miss important differences. A model that's 2% less accurate but significantly better calibrated and more stable over time could be the better production choice.
Ensemble methods help selectively: Averaging predictions across models improves calibration (as expected from ensemble theory), but averaging reasoning traces creates incoherent narratives. For applications requiring explainability, ensembles present challenges.
Experimental Results and Model Performance
The paper evaluated eight frontier LLMs across 500+ live prediction markets over a 30-day window (December 12, 2025 - January 10, 2026). During this period, the platform processed 876,567 forecasting decisions from 531,770 users deploying 983,600 fine-tuned agents, with over $1.14B in active market value. The evaluation captured more than 1.18M probability updates across markets spanning geopolitics, economics, science, and technology.
Model Performance Overview
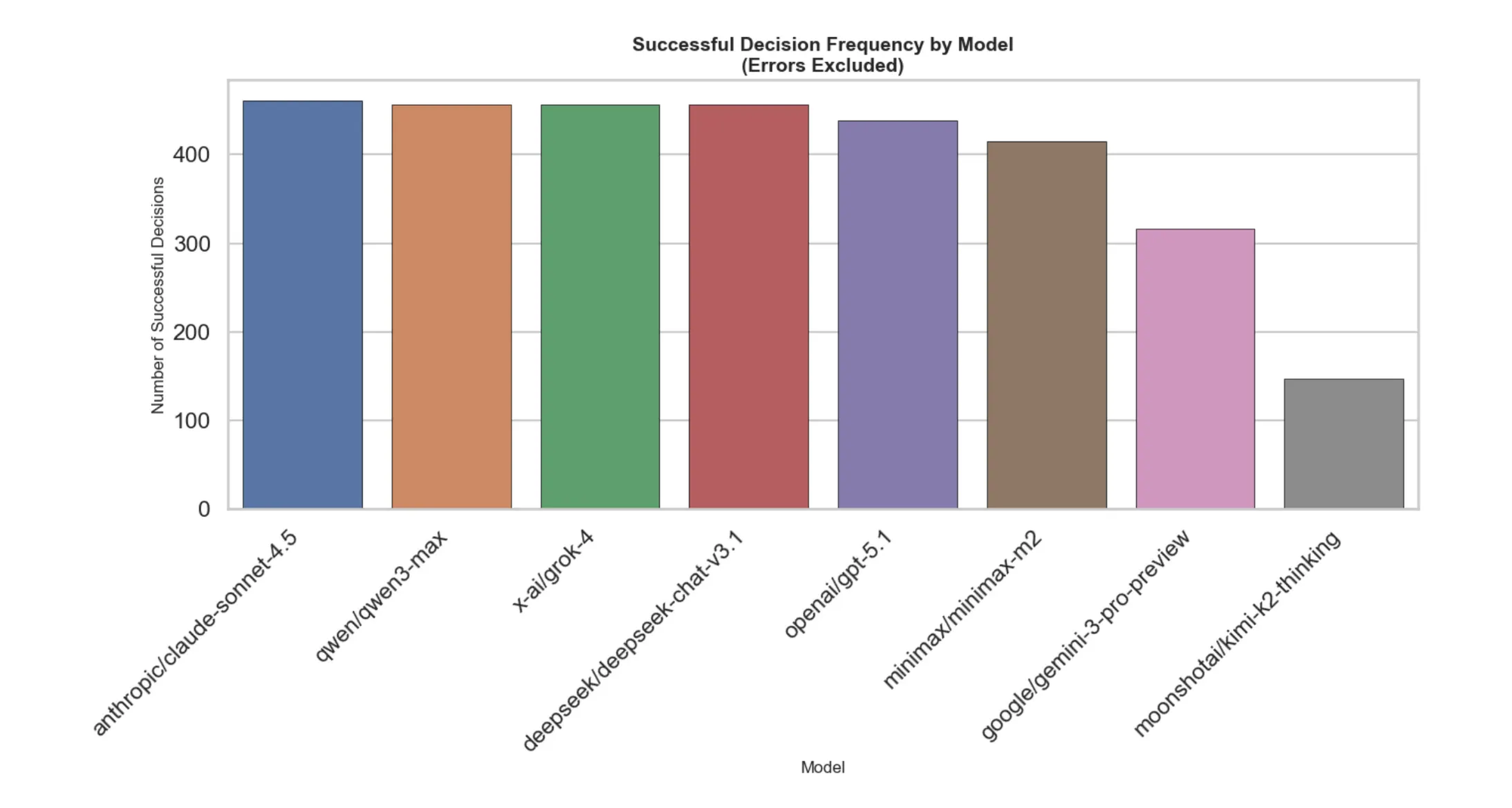
All eight models that met the inclusion criteria (at least 50,000 deployed agents with sustained activity) showed negative P&L, indicating systematic losses when their predictions were used to make hypothetical market decisions. This is the first major insight: raw forecasting ability doesn't automatically translate to profitable decision-making.
Key Observations:
- Claude-Sonnet-4.5 had the worst P&L (-$14.3M) despite being widely deployed. This suggests that while the model may produce confident predictions, those predictions diverged significantly from profitable market decisions. Notably, it had very low output tokens (713), indicating concise reasoning that may have missed important nuance.
- Gemini-3-Pro-Preview had the best (least negative) P&L (-$2.6M) while consuming the most tokens (6,725 input, 4,611 output). This suggests that more extensive reasoning correlates with better decision quality, though still not profitability.
- Token consumption varies dramatically: Qwen3-Max averaged only 429 output tokens while Gemini-3-Pro-Preview averaged 4,611—more than 10x difference. This affects both the reasoning depth and the computational cost of deployment.
Behavioral Patterns
Strategy Selection : Models showed distinct strategy preferences. GPT-5.1 and Grok-4 heavily favored drift-adjusted strategies, indicating frequent recalibration to market movements. This explains their higher temporal drift scores: they were constantly updating beliefs. Models with more HOLD and UNKNOWN actions (like Qwen3-Max) traded responsiveness for stability.
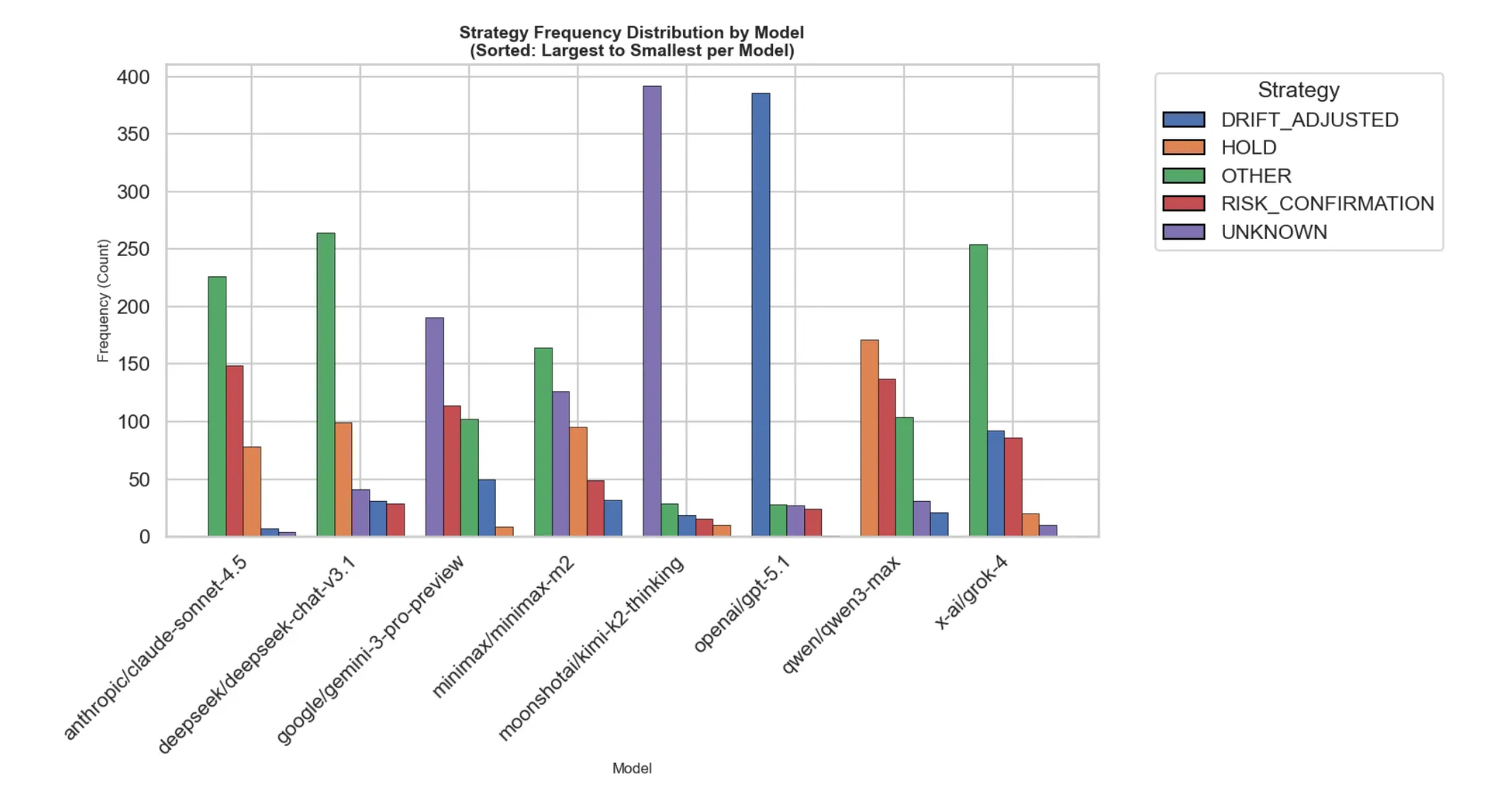
Reasoning Footprint: The token consumption patterns reveal fundamental differences in how models approach forecasting:
- Verbose reasoners (Gemini-3-Pro-Preview, Grok-4): Long internal reasoning chains, explicit probability articulation, richer causal modeling but also higher sensitivity to transient information
- Compact reasoners (Qwen3-Max, DeepSeek-Chat-v3.1): Concise updates, lower variance in probability revisions, more stable but potentially less nuanced
Adjustment Depth: Claude-Sonnet-4.5 performed extremely large expected-return adjustments, showing aggressive re-weighting when new information arrived. Kimi-K2-Thinking exhibited minimal adjustment depth, producing more inert belief trajectories. These differences directly correlate with drift metrics:deeper adjustments mean larger probability swings.
Decision Success Rate: Claude-Sonnet-4.5, Grok-4, and DeepSeek-Chat-v3.1 achieved the highest success counts for returning valid outputs within time constraints. Kimi-K2-Thinking, despite its long reasoning chains (3,166 output tokens), exhibited the lowest success frequency: verbosity didn't translate to effective probabilistic correction.
The Accuracy-Stability-Efficiency Tradeoff
The results reveal a fundamental three-way tradeoff:
High-capacity models (Gemini-3-Pro-Preview, Grok-4):
- Deeper reasoning and better outcome prediction
- Greater volatility in belief updates
- Higher inference costs (6,725+ input tokens)
- More sensitive to transient information
Compact models (Qwen3-Max, DeepSeek-Chat-v3.1):
- Stable, scalable forecasting
- Lower token budgets (429-717 output tokens)
- Less expressive reasoning
- More consistent but potentially less accurate
The paradox: Models with similar forecast accuracy diverged markedly in calibration, drift, and risk sensitivity. This means that choosing models based solely on accuracy benchmarks misses critical deployment considerations. A model that's 2% less accurate but significantly more stable and 10x cheaper to run might be the better production choice.
Why This Matters
TruthTensor gives us a framework for measuring the stuff that actually matters when you deploy:
- Does the model maintain coherent reasoning as context evolves?
- Can I trust its confidence estimates?
- Does it handle uncertainty in a human-aligned way?
- Will it stay stable over time or drift in weird ways?
These aren't academic questions. These are "will this model embarrass us in production" questions.
Final Thoughts
TruthTensor shifts the evaluation question from "is this model smart?" to "does this model reason in ways that align with human thinking under uncertainty?" The experimental results across nearly 1.2M probability updates demonstrate why this reframing matters.
The finding that all eight frontier models produced negative P&L despite being widely deployed is striking. It suggests that current LLMs, while impressive at many tasks, struggle with the kind of probabilistic reasoning and belief updating that characterizes human expertise in uncertain domains. The wide variance in P&L (from -$2.6M to -$14.3M) despite similar deployment scales reveals that model quality differences are real and measurable when evaluated dynamically.
The token consumption patterns are particularly interesting for applied work. Gemini-3-Pro-Preview's 10x higher output token count compared to Qwen3-Max translated to better (less negative) P&L, suggesting that reasoning depth matters for decision quality. But this comes with proportional computational costs, a critical tradeoff for production deployment.
For teams working on LLM evaluation, building agentic systems, or selecting models for production deployment, TruthTensor offers important insights:
- Static benchmarks mask deployment-critical properties: Calibration, drift, and decision stability don't show up in accuracy metrics
- There's no universal "best" model: The right choice depends on whether you prioritize stability, reasoning depth, or computational efficiency
- Temporal evaluation reveals model limitations: How models update beliefs over time matters as much as their initial predictions
The shift from prediction evaluation to human imitation assessment provides metrics that better align with what we actually need from these systems in practice. When the stakes are high and uncertainty is genuine, we need models that reason like experts—not just models that produce confident answers.
Paper: Shahabi, S., Graham, S., & Isah, H. (2025). TruthTensor: Evaluating LLMs through Human Imitation on Prediction Market under Drift and Holistic Reasoning. arXiv:2601.13545
Framework: https://truthtensor.com


