APIGen-MT: Structured Multi-Turn Data via Simulation

Intro: Why this matters
Picture this: You’re building an AI agent to help users book travel, troubleshoot software, or manage finances. One task leads to another. The user changes their mind halfway. New context unfolds mid-conversation. How do you train your AI to navigate all of that without losing its mind—or the thread?
That’s the challenge APIGen-MT tackles: creating rich, realistic multi-turn training data that prepares AI agents for real-world, back-and-forth dialogue.
The problem with current approaches
Today’s AI agents are trained on data that’s too clean, too shallow, and too rigid. Most training sets rely on static, one-shot prompts with canned responses. They don’t reflect how humans actually interact—messy, changing, and full of context.
Even worse, many of these datasets aren’t verifiable. There’s no clear ground truth to judge whether an agent’s action was "correct." That’s a problem if you want your agent to do more than just guess and bluff.
What is APIGen-MT?
APIGen-MT is a two-phase framework for synthesizing realistic, multi-turn agent training data. Think of it as a production line where every task starts with a solid blueprint and then evolves into a full dialogue between a simulated human and AI agent.
But it’s not just about generating chat logs. APIGen-MT ensures:
- Every task is grounded in executable APIs
- Every agent action is verifiable
- Every conversation aligns with a clear, testable user goal
The result? AI training data that’s as rich as real conversations, but structured enough to build better models.
How it works (breakdown + example)
Phase 1: Task blueprinting
It starts with setting the stage: gathering APIs, domain policies, and any context the agent might need. Then, an LLM proposes a user task—something like, "Find me a flight under $500 that lands before noon."
Behind the scenes, APIGen-MT builds a structured plan:
- The user intent (q)
- A sequence of ideal API calls to solve it (agt)
- The final response the agent should produce (ogt)
Before this plan is approved, it’s stress-tested. Format checks verify API syntax. Execution checks make sure those APIs work in a real (simulated) environment. Policy tests, written as Python unit tests, enforce domain rules.
Then comes the review panel—a group of LLMs evaluating the blueprint’s coherence and completeness. If a task fails at any point, feedback is generated and the blueprint is refined in a new round.
And for more complex tasks? APIGen-MT supports "Reverse Task Recombination," stitching together multiple validated tasks into one seamless challenge.
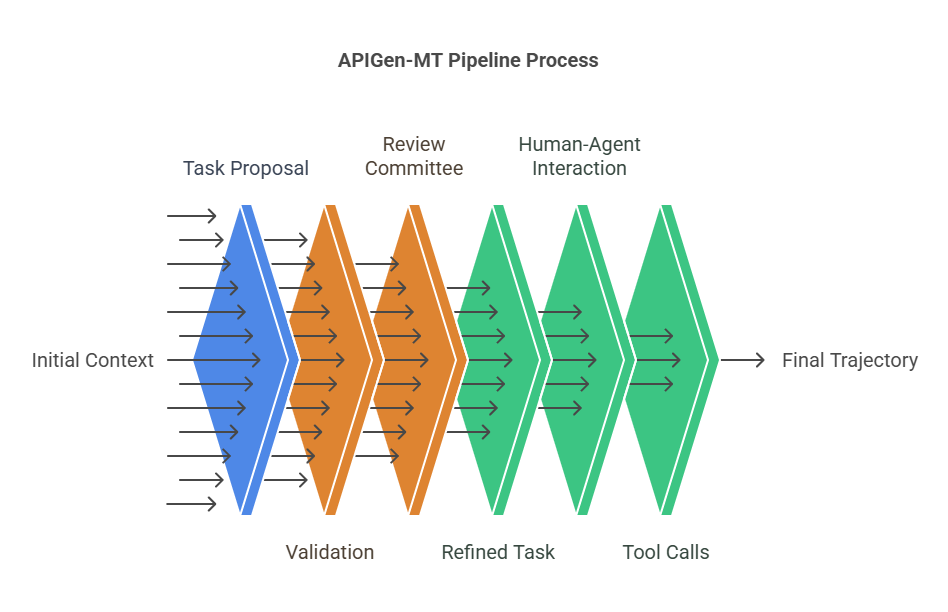
Phase 2: Simulated dialogue
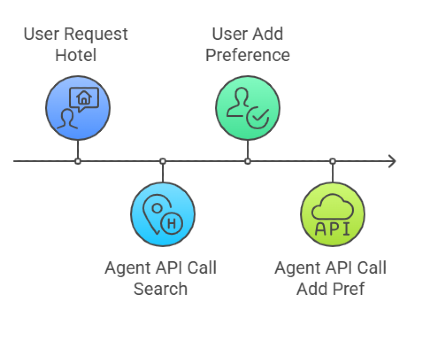
Once a blueprint is approved, it’s turned into a realistic multi-turn conversation.
An LLM plays the human. It gradually reveals subgoals and context. The AI agent interprets the intent and uses API calls to respond. Crucially, the simulated human doesn’t know what tools the agent has—mimicking real-world constraints.
Each interaction is validated: Did the final state match expectations? Did the conversation make sense? Only successful dialogues are added to the training dataset.
To stabilize things, APIGen-MT samples multiple human responses (Best-of-N) and uses self-critique to pick the most consistent ones.
Why it stands out
What makes APIGen-MT such a strong foundation for agentic AI?
First, it separates planning from execution. By designing blueprints first, it avoids tangled logic later.
Second, it grounds everything in execution. API calls aren’t just text—they’re run in a simulated environment, making each task testable and reproducible.
Third, it treats validation seriously—with multi-stage checks, LLM committees, and feedback loops that refine tasks until they’re solid.
And finally, it models agentic interaction as a POMDP—a mathematical framework for decision-making under uncertainty. This helps frame agent behavior in terms of actions, observations, and latent states, just like real-life conversations.
Comparison with similar tools
| Feature | APIGen-MT | MultiChallenge | ToolSandbox | InterCode | AgentInstruct |
|---|---|---|---|---|---|
| Multi-turn generation | ✅ | ✅ | ✅ | ✅ | ✅ |
| Groundtruth verification | ✅ | ❌ | ✅ | ✅ | ❌ |
| Executable environments | ✅ | ❌ | ✅ | ✅ | ❌ |
| Open-sourced pipeline/data | ✅ | ✅ | ✅ | ✅ | ✅ |
Real-world use cases
Whether you’re building a travel assistant or a compliance bot, APIGen-MT makes it easier to:
- Train agents that adapt to evolving user goals
- Simulate complex workflows with many moving parts
- Test agents in controlled, repeatable environments
- Benchmark long-horizon reasoning with confidence
Benchmarks or results
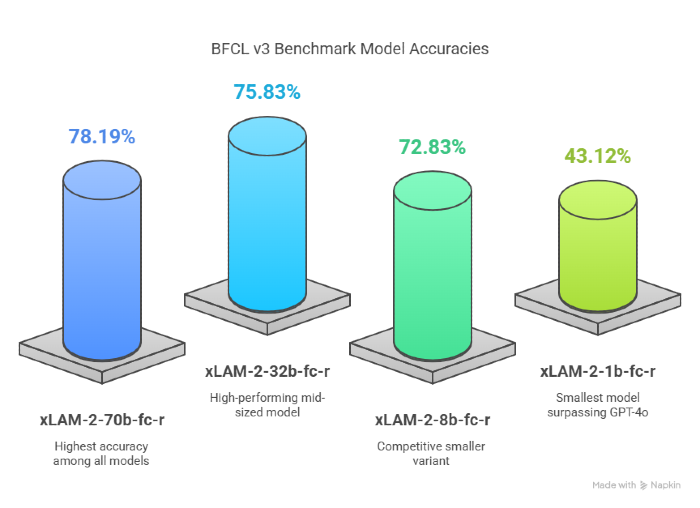
The BFCL v3 benchmark is a leading evaluator of function-calling performance in LLMs, spanning both single-turn and multi-turn scenarios. APIGen-MT-trained models dominate here:
- The xLAM-2-70b-fc-r model achieves a staggering 78.19% accuracy, the highest on the leaderboard—outpacing frontier models like GPT-4o (72.08%) and Claude 3.5.
- Even smaller variants like xLAM-2-32b-fc-r (75.83%) and xLAM-2-8b-fc-r (72.83%) stand tall among giants.
- The smallest xLAM-2-1b-fc-r achieves 43.12%—surpassing GPT-4o’s 41% in function-calling mode.
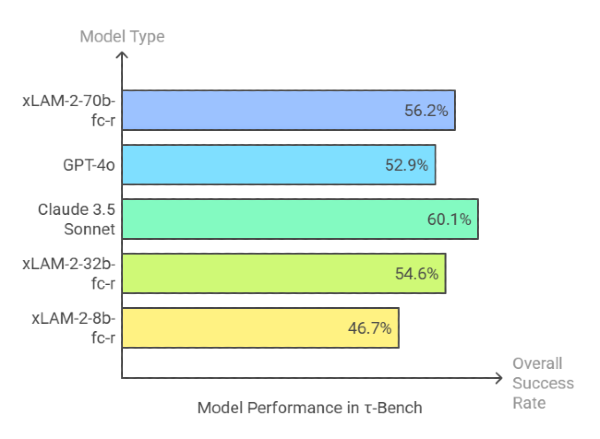
τ-Bench pushes agents into real-world-like conversations with policy-constrained APIs in domains like retail and airlines.
- xLAM-2-70b-fc-r scores 56.2% overall success—leaping over GPT-4o (52.9%) and approaching Claude 3.5 Sonnet (60.1%).
- Smaller models still punch above their weight: xLAM-2-32b-fc-r: 54.6%, xLAM-2-8b-fc-r: 46.7%.
- Even xLAM-2-3b-fc-r and 1b-fc-r hold competitive ground, proving that quality multi-turn training data can reduce the need for massive scale.
The consistent success of smaller xLAM-2 models trained with APIGen-MT data underlines a paradigm shift:
You don’t need a bigger model—you need better data.
By simulating rich agent-human interplay and embedding verifiable actions, APIGen-MT ensures that models aren't just talking—they’re reasoning, executing, and adapting.
The bigger picture
The future of AI isn’t prompt engineering—it’s agent design.
APIGen-MT shifts the paradigm from statically scripted interactions to dynamic, goal-driven simulations. It lets researchers build, validate, and share datasets that reflect how people actually talk and solve problems.
And it’s open-source. The data. The models. The pipeline. If you’re working on tool-using agents, this is the benchmark to beat—and the starting point to build from.
References
- Wang, B., Zhang, K., Lin, Z., Zhou, H., Liu, P., & Ren, X. (2025). APIGen-MT: Agentic Pipeline for Multi-Turn Data Generation via Simulated Agent-Human Interplay. arXiv preprint arXiv:2504.03601. https://arxiv.org/abs/2504.03601
- Berkeley AI Research. (n.d.). BFCL Leaderboard (Berkeley Function-Calling Leaderboard). Retrieved April 11, 2025, from https://gorilla.cs.berkeley.edu/leaderboard.html
- Guo, D., Liu, P., Xie, M., Lin, Z., Yu, M., Zhang, K., & Ren, X. (2024). Tau-bench: Evaluating Agent Functionality and Alignment with Human Intent via Multi-turn Tool-augmented Dialogues. arXiv preprint arXiv:2406.12045. https://arxiv.org/pdf/2406.12045