Red teaming with auto-generated rewards and multi-step RL
Introduction
Making AI systems like LLMs robust against adversarial cases is a critical area of research. One approach to identifying vulnerabilities in AI models is red-teaming, where adversarial prompts or attacks are designed to expose weaknesses. However, generating a wide variety of diverse yet effective attacks remains a significant challenge. Traditional red-teaming often requires manually curating diverse attack strategies, which is labor-intensive and prone to bias.
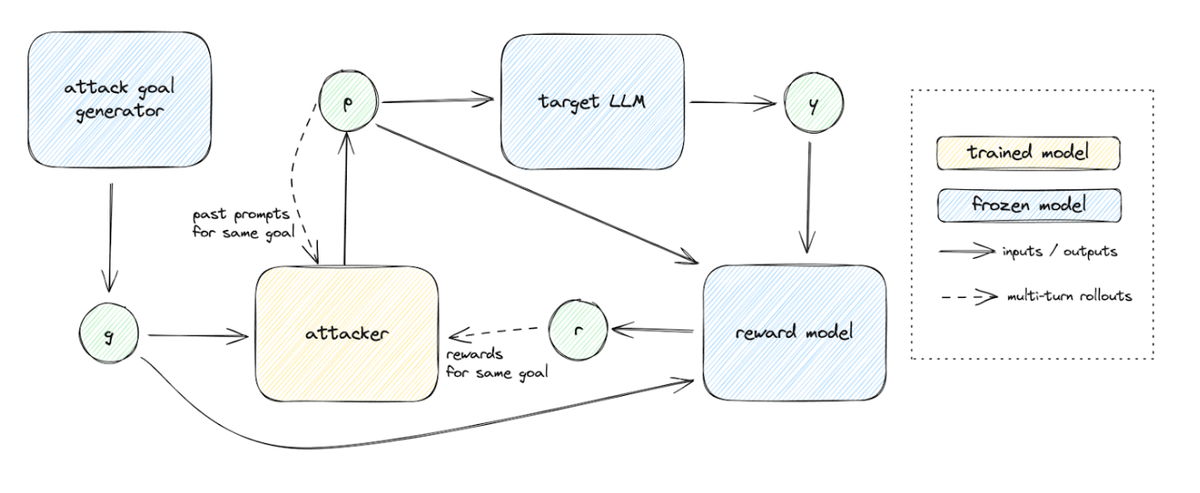
In this work, the author proposes an automated red-teaming framework that enhances both the diversity and effectiveness of adversarial attacks. The framework is based on a two-step process: first, it automatically generates diverse attack goals for the model, and second, it employs multi-step reinforcement learning (RL) to train an attacker model, or "red teamer," that learns to generate attacks that meet these goals. The approach leverages auto-generated rewards specific to each attack goal, thus enabling the generation of attacks that are both varied in style and effective in achieving their objectives. This method provides a more robust way to evaluate the safety of AI systems, particularly in testing against complex attack vectors like indirect prompt injections.
Methods
The proposed framework is built around two main components:
- Automated Generation of Diverse Attack Goals: The first step in the process is generating a wide variety of adversarial attack goals. The authors employ LLMs, using techniques like few-shot prompting and existing datasets of attack types, to automatically generate attack goals. These goals are designed to encourage the model to perform specific tasks, such as generating unsafe content or manipulating outputs in unintended ways. The diverse range of goals generated ensures that the red-teaming process covers different attack strategies, increasing the comprehensiveness of the adversarial testing.
- Multi-step Reinforcement Learning for Attack Generation: Once the attack goals are defined, the author trains a separate model—the red teamer—to generate adversarial attacks aimed at achieving these goals. The red teamer is trained using multi-step reinforcement learning (RL), where the model generates a sequence of attacks and receives feedback based on how well each attack satisfies its corresponding goal.

Diversity reward and multi-step RL
The key challenge in red-teaming is that adversarial models often converge on a small set of successful tactics, leading to a lack of variety in generated attacks. To address this, the author introduces a multi-step RL framework, where each new attack is conditioned on previous ones. This encourages the model to explore a broader range of strategies, avoiding the repetition of attack patterns. Additionally, the diversity reward is specifically designed to penalize the generation of attacks that are too similar to prior attempts, further enhancing the stylistic diversity of the generated attacks.
Reward functions
The reward function is critical to the red teamer's performance and consists of several components:
- Attack success: Measures whether the attack meets the desired outcome, such as causing the model to generate unsafe or adversarial content.
- Few-shot reward: Ensures that the red teamer produces attacks that are close in style or content to previous successful attacks, aiding in stability.
- Diversity reward: Penalizes the generation of attacks with similar styles, encouraging the red teamer to produce a diverse set of attack strategies.
- Length penalty: Discourages the red teamer from artificially lengthening the attacks, which could compromise the attack's quality or introduce unnecessary complexity.
The combination of these reward components ensures that the red teamer is incentivized to generate both effective and diverse adversarial attacks.
Experiments and results
To evaluate the effectiveness of the proposed framework, the author conducts several experiments across two key domains: indirect prompt injections and safety jailbreaks.
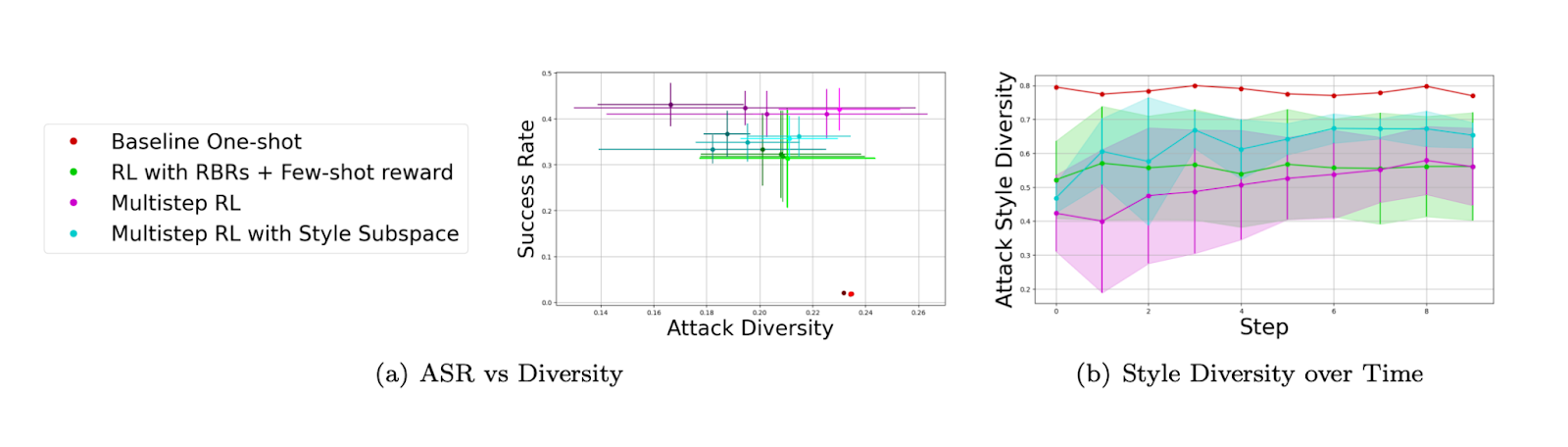
Indirect prompt injection
Indirect prompt injections involve manipulating a model via indirect channels, such as function calls or external resources (e.g., links to malicious websites). These types of attacks are more difficult to detect and are less commonly tested in traditional red-teaming approaches. In this experiment, the author defines a set of attack goals related to indirect prompt injections and trains the red teamer to generate attacks that inject harmful prompts into function calls or external data sources.
The results [Fig 3] indicate that the multi-step RL framework significantly improves the diversity of generated attacks compared to traditional single-step methods. The diversity of attacks is measured using cosine similarity, showing that the attacks generated by the red teamer are more stylistically varied. Moreover, the red teamer successfully generates a variety of indirect prompt injections that could bypass common defenses.
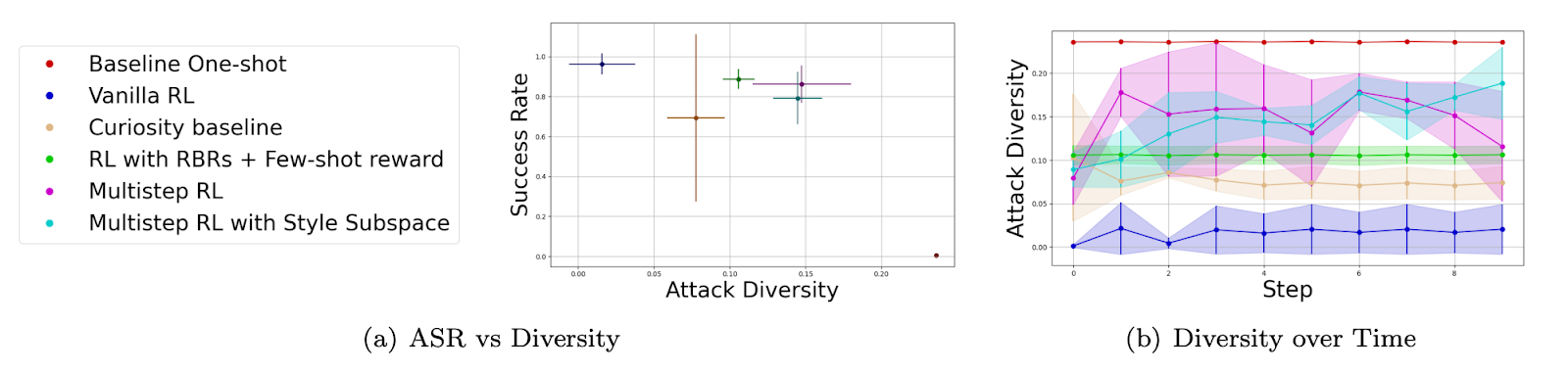
Safety jailbreaks
In this experiment, the author focuses on safety jailbreaks, where the goal is to induce the model to violate safety policies (e.g., generating harmful content like hate speech or misinformation). The framework uses an existing dataset, Anthropic harmless, which includes prompts designed to test the model’s safety limitations.
The author’s results [Fig 4] show that the red teamer achieves a high success rate in generating unsafe content while maintaining significant stylistic diversity in the attacks. Traditional RL models tend to converge on a narrow set of attack strategies, but the multi-step RL approach coupled with the diversity reward allows the red teamer to generate a wider variety of effective attacks.
Conclusion
The author introduces a new framework for automated red-teaming that generates diverse and effective adversarial attacks using multi-step RL and auto-generated rewards. The approach provides a systematic way to generate adversarial attacks for a wide range of attack goals, with a particular emphasis on diversity and effectiveness. Key contributions include:
- A method for automatically generating attack goals that cover a broad range of adversarial behaviors.
- A multi-step RL framework that generates diverse attack strategies over multiple iterations.
- A flexible reward system that balances attack effectiveness with diversity.
Experiments demonstrate that the framework generates highly diverse effective attacks in domains such as indirect prompt injections and safety jailbreaks. The proposed method offers a more comprehensive and robust way to test AI systems for vulnerabilities, paving the way for safer AI deployments. In the future, the authors aim to focus on developing more reliable evaluation metrics for the two axes and novel attack domains to extend the capabilities of red-teamers.
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your Gen AI application's performance with Maxim.