Advanced RAG techniques

Introduction
LLMs excel in knowledge-intensive tasks but often struggle with niche or long-tail queries. RAG enhances LLMs by incorporating external knowledge, yet it faces a key challenge: imperfect retrieval. This occurs when retrieved information is incorrect, irrelevant, or conflicting, leading to unreliable results. In this blog, we explore an advanced RAG technique called Astute RAG, designed to tackle the pitfalls of imperfect retrieval. By adaptively leveraging both internal and external knowledge, Astute RAG enhances the robustness of LLMs and effectively resolves knowledge conflicts. We will dive into the core methodology of Astute RAG, its experimental results, and how it outperforms existing RAG methods in realistic and challenging scenarios.
The problem of imperfect retrieval in existing RAG methods
RAG systems rely heavily on external sources to enhance LLM performance. However, one of the most significant challenges in RAG is the frequent occurrence of imperfect retrieval. These issues can lead to RAG failures, whether due to limitations in the retriever, the quality of the corpus, or the complexity of the queries.
For example, when tasked with answering an obscure question, an LLM might retrieve irrelevant or misleading information. Such occurrences are not rare. In fact, around 70% of retrieved passages in real-world scenarios do not contain the correct answers, severely impeding the model’s performance. Worse still, irrelevant or misleading passages may propagate false or inaccurate information into the LLM’s generated response.
One of the biggest challenges is the knowledge conflict that arises between the LLM's internal knowledge and the retrieved external sources. Internal knowledge is derived from the extensive data used to pre-train LLMs, while external information is fetched in real-time, often from noisy or unverified sources. When these two knowledge streams conflict, RAG systems often fail to reconcile them, leading to incorrect answers.

Astute RAG: An approach to handle imperfect retrieval
Astute RAG is designed to address the pitfalls of imperfect retrieval by adaptively utilizing both LLM-internal knowledge and external sources. It is built on the premise that while retrieval can augment LLM performance, it should only be trusted when reliable.
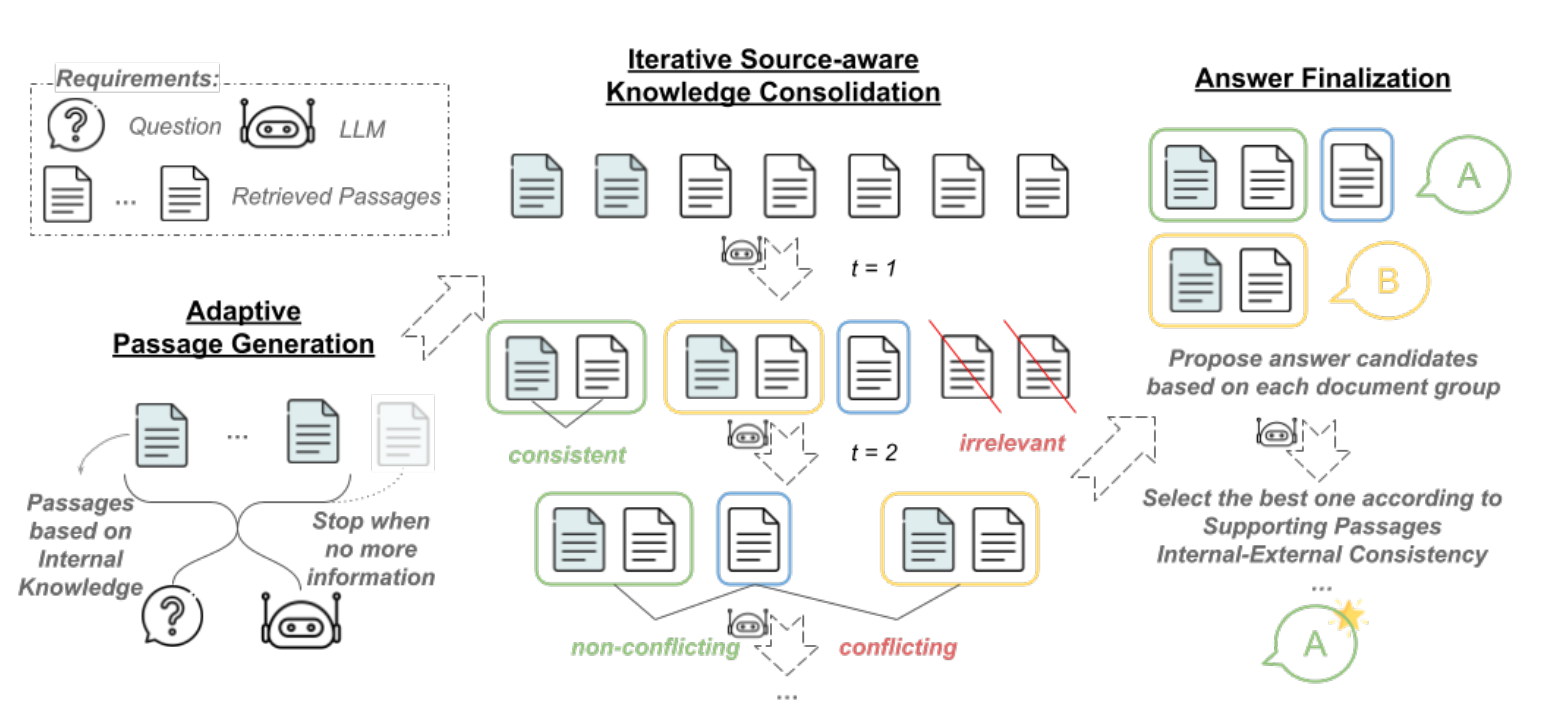
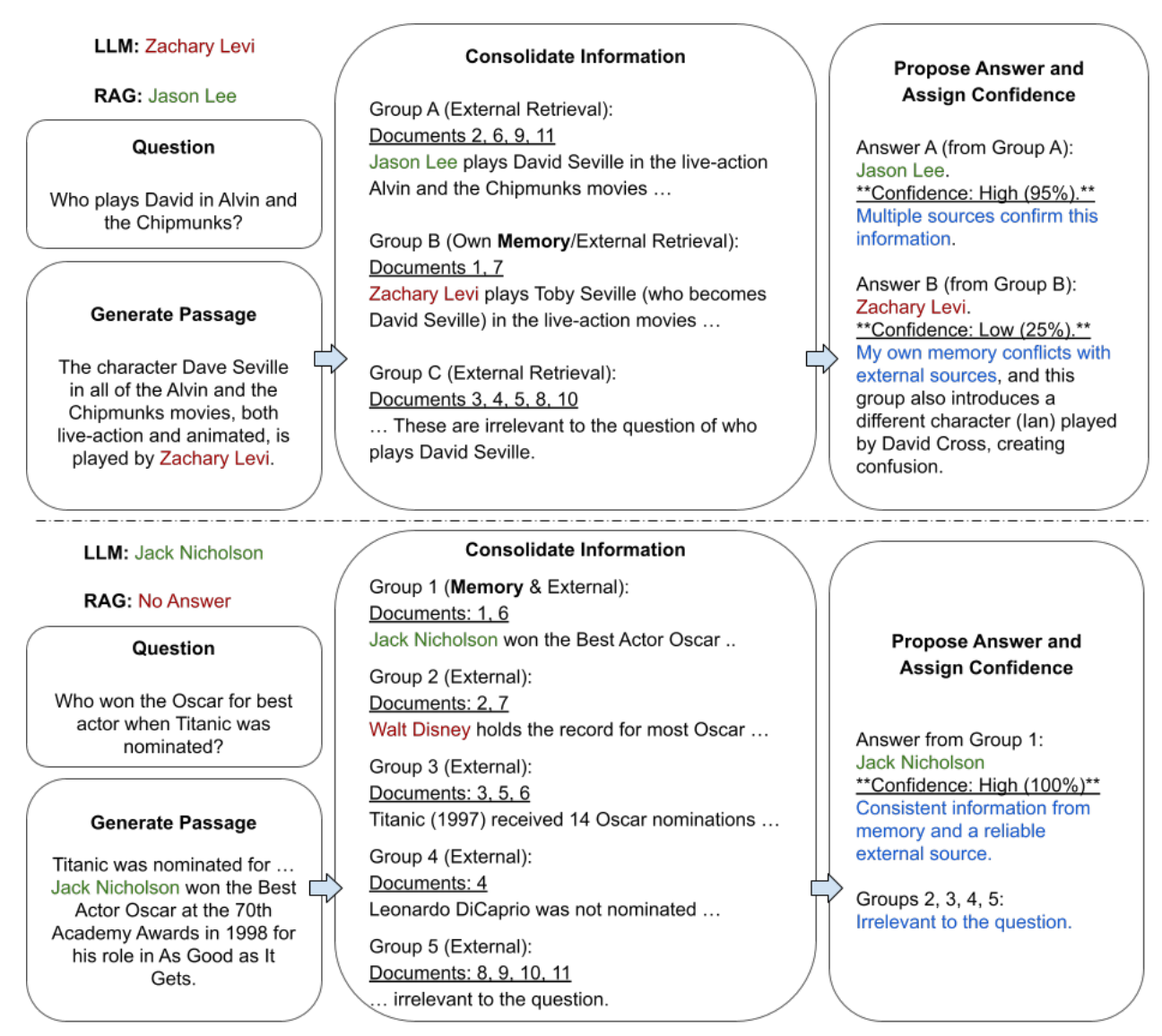
Astute RAG introduces a three-step process to improve RAG robustness:
Adaptive generation of internal knowledge: Before relying on external retrieval, Astute RAG prompts the LLM to tap into its own internal knowledge to generate relevant passages. This helps to preemptively fill in gaps that may arise from insufficient external retrieval and provides an initial answer that reflects the model’s extensive pre-training.

Iterative source-aware knowledge consolidation: Astute RAG combines the internally generated passages with retrieved external information. Through an iterative process, the model consolidates knowledge by identifying consistent information, flagging conflicts, and filtering out irrelevant content. Each passage is tagged with its source (internal or external) to enable a better evaluation of its trustworthiness.

Answer finalization based on reliability: After consolidating the knowledge, Astute RAG compares the information from different sources to propose a final, reliable answer. The model prioritizes information based on consistency and source credibility, ensuring that the most accurate knowledge is used to generate the final response.
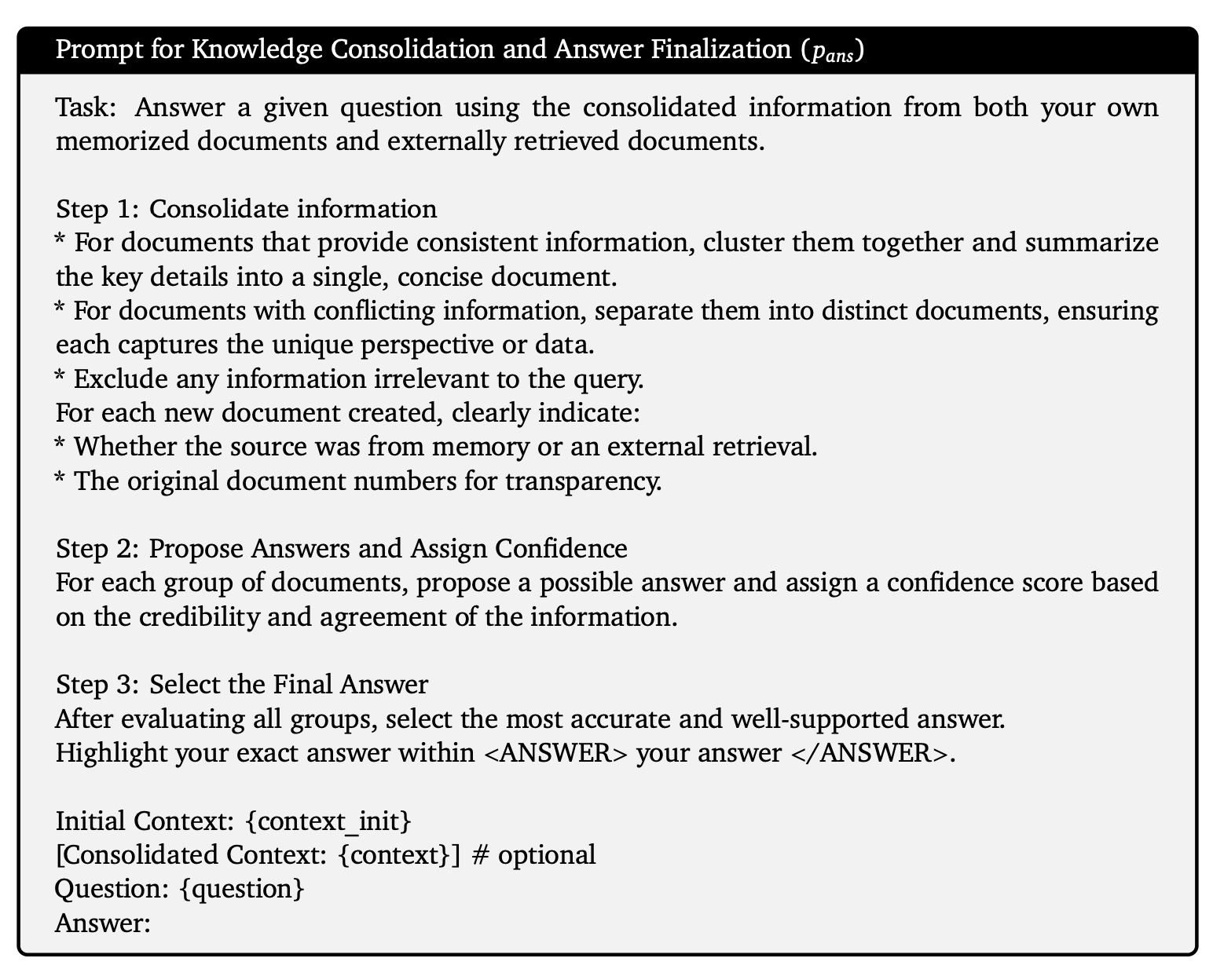
This iterative approach ensures that even in the face of imperfect retrieval, Astute RAG can reconcile conflicts between internal and external knowledge and produce more reliable outputs.
Experimental validation of Astute RAG
To evaluate the effectiveness of Astute RAG, experiments were conducted using two advanced LLMs: Gemini and Claude. The models were tested across various datasets, including general, domain-specific, and long-tail queries from sources like Natural Questions (NQ), TriviaQA, BioASQ, and PopQA.
The experiments revealed the following key findings:
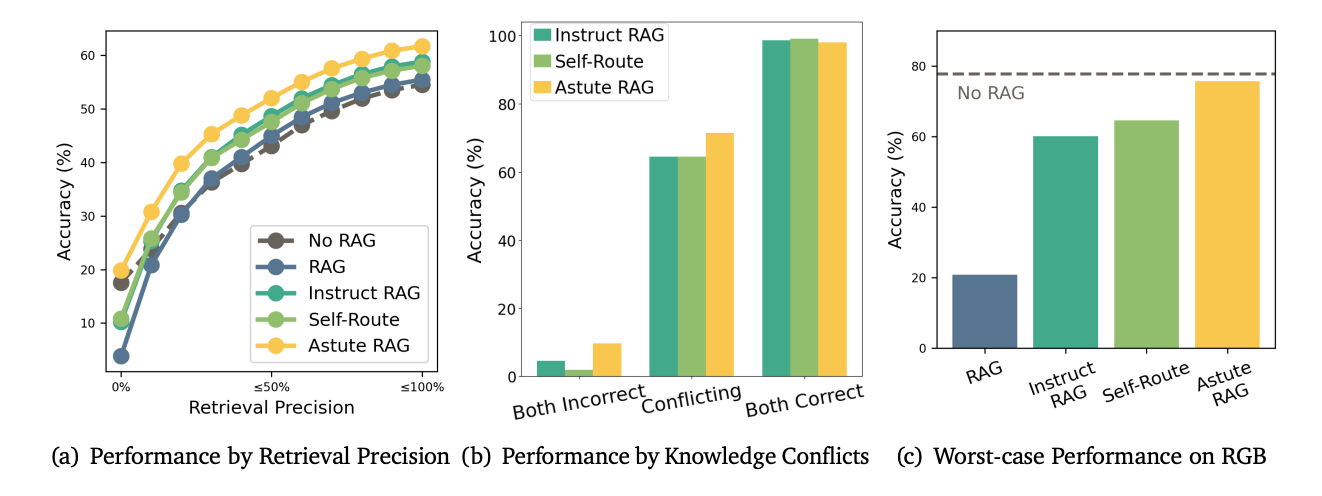
Prevalence of imperfect retrieval: In approximately 20% of the cases, no retrieved passage contained the correct answer. In certain datasets like PopQA, this rate rose to 50%. This highlights the severe limitations of current retrieval mechanisms and the need for systems like Astute RAG that can mitigate these issues.
Astute RAG outperforms baselines: Compared to other RAG methods such as GenRead, RobustRAG, and InstructRAG, Astute RAG consistently outperformed them across all datasets. The overall improvement was 6.85% on Claude and 4.13% on Gemini. Notably, Astute RAG showed its strength in domain-specific datasets like BioASQ, where it achieved substantial gains over other methods.
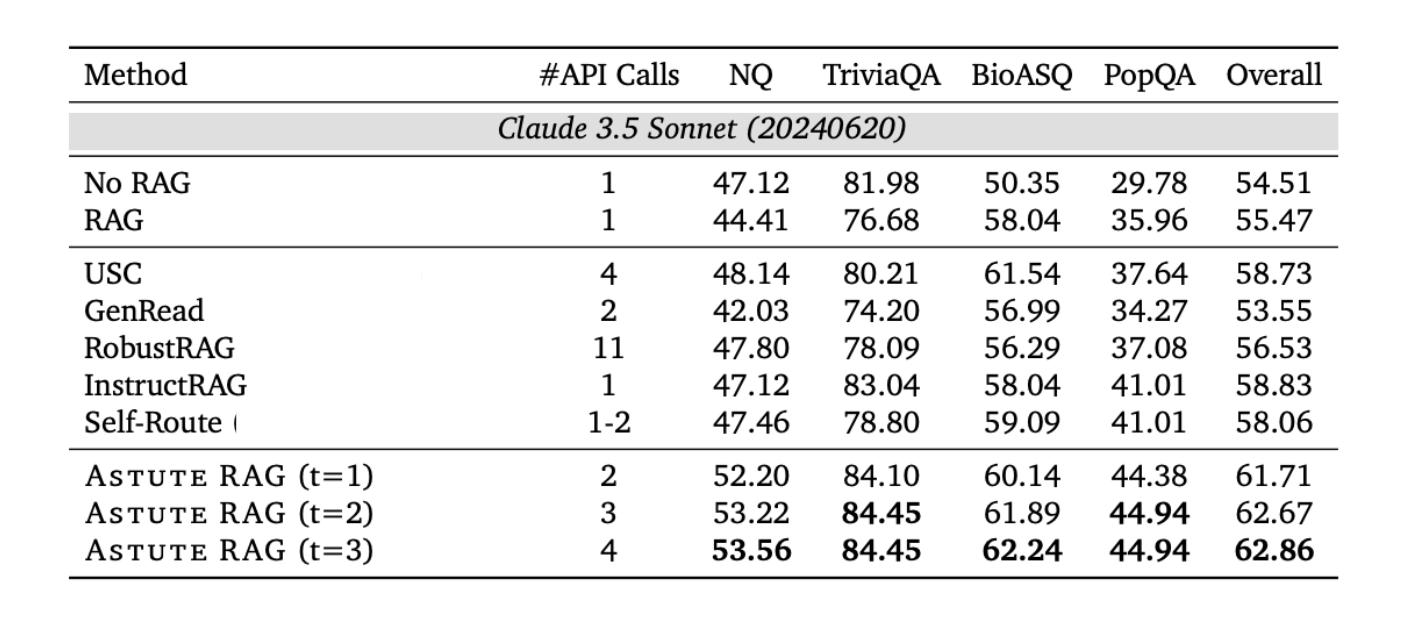
Addressing knowledge conflicts: Astute RAG demonstrated a remarkable ability to resolve knowledge conflicts between internal and external sources. In cases where the internal and external knowledge conflicted, Astute RAG chose the correct answer about 80% of the time, significantly outperforming other methods.
Worst-case scenario performance: In scenarios where all retrieved passages were unhelpful (e.g., containing only negative information), Astute RAG was the only method that performed comparably to using no retrieval at all. This underscores its robustness in handling the worst-case retrieval situations.
Why does Astute RAG work?
The success of Astute RAG lies in its ability to adaptively generate and consolidate knowledge. Leveraging the internal knowledge of LLMs compensates for gaps left by imperfect retrieval. The iterative consolidation process further refines the information by filtering out irrelevant or conflicting data, ensuring that only the most reliable knowledge is used.
Moreover, Astute RAG’s source awareness enables it to distinguish between different types of knowledge (internal vs. external), allowing it to assess the credibility of the information before generating a response. This nuanced approach to handling knowledge conflicts is what sets Astute RAG apart from previous methods.
Conclusion
Imperfect retrieval is an inherent challenge in retrieval-augmented generation systems, leading to knowledge conflicts and unreliable outputs. However, Astute RAG offers a promising solution by adaptively utilizing internal knowledge and iteratively consolidating it with external information. Through controlled experiments, Astute RAG has demonstrated its superiority over existing RAG methods, especially in challenging scenarios with conflicting or unreliable retrieval results. Astute RAG’s ability to resolve knowledge conflicts and maintain high performance, even in worst-case scenarios, makes it a powerful tool for enhancing the trustworthiness of LLM-based systems.
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your Gen AI application's performance with Maxim.